 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPERC: Direct Parameter Estimation for Mixed Data
Jan 17, 2025

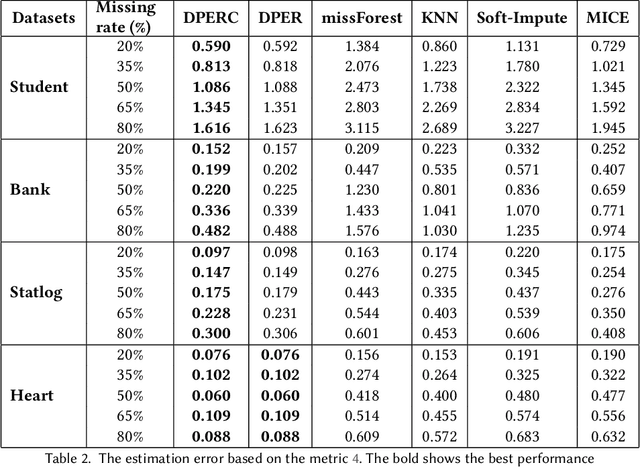
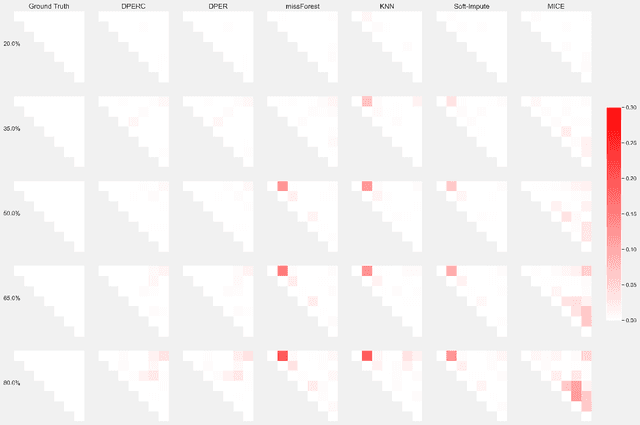
The covariance matrix is a foundation in numerous statistical and machine-learning applications such as Principle Component Analysis, Correlation Heatmap, etc. However, missing values within datasets present a formidable obstacle to accurately estimating this matrix. While imputation methods offer one avenue for addressing this challenge, they often entail a trade-off between computational efficiency and estimation accuracy. Consequently, attention has shifted towards direct parameter estimation, given its precision and reduced computational burden. In this paper, we propose Direct Parameter Estimation for Randomly Missing Data with Categorical Features (DPERC), an efficient approach for direct parameter estimation tailored to mixed data that contains missing values within continuous features. Our method is motivated by leveraging information from categorical features, which can significantly enhance covariance matrix estimation for continuous features. Our approach effectively harnesses the information embedded within mixed data structures. Through comprehensive evaluations of diverse datasets, we demonstrate the competitive performance of DPERC compared to various contemporary techniques. In addition, we also show by experiments that DPERC is a valuable tool for visualizing the correlation heatmap.
Weighted Missing Linear Discriminant Analysis: An Explainable Approach for Classification with Missing Data
Jun 30, 2024



As Artificial Intelligence (AI) models are gradually being adopted in real-life applications, the explainability of the model used is critical, especially in high-stakes areas such as medicine, finance, etc. Among the commonly used models, Linear Discriminant Analysis (LDA) is a widely used classification tool that is also explainable thanks to its ability to model class distributions and maximize class separation through linear feature combinations. Nevertheless, real-world data is frequently incomplete, presenting significant challenges for classification tasks and model explanations. In this paper, we propose a novel approach to LDA under missing data, termed \textbf{\textit{Weighted missing Linear Discriminant Analysis (WLDA)}}, to directly classify observations in data that contains missing values without imputation effectively by estimating the parameters directly on missing data and use a weight matrix for missing values to penalize missing entries during classification. Furthermore, we also analyze the theoretical properties and examine the explainability of the proposed technique in a comprehensive manner. Experimental results demonstrate that WLDA outperforms conventional methods by a significant margin, particularly in scenarios where missing values are present in both training and test sets.