 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
MS2: Multi-Document Summarization of Medical Studies
Apr 15, 2021

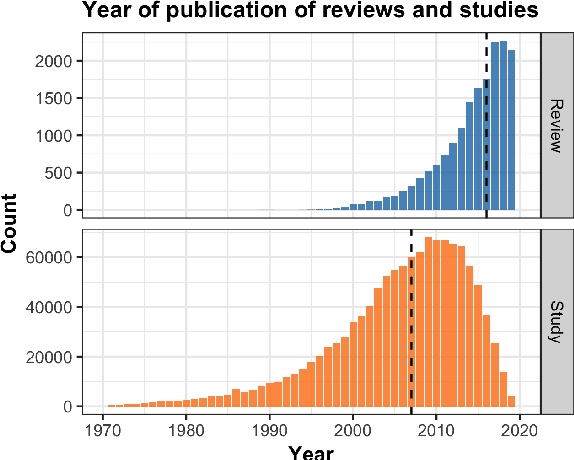
To assess the effectiveness of any medical intervention, researchers must conduct a time-intensive and highly manual literature review. NLP systems can help to automate or assist in parts of this expensive process. In support of this goal, we release MS^2 (Multi-Document Summarization of Medical Studies), a dataset of over 470k documents and 20k summaries derived from the scientific literature. This dataset facilitates the development of systems that can assess and aggregate contradictory evidence across multiple studies, and is the first large-scale, publicly available multi-document summarization dataset in the biomedical domain. We experiment with a summarization system based on BART, with promising early results. We formulate our summarization inputs and targets in both free text and structured forms and modify a recently proposed metric to assess the quality of our system's generated summaries. Data and models are available at https://github.com/allenai/ms2
MedICaT: A Dataset of Medical Images, Captions, and Textual References
Oct 12, 2020

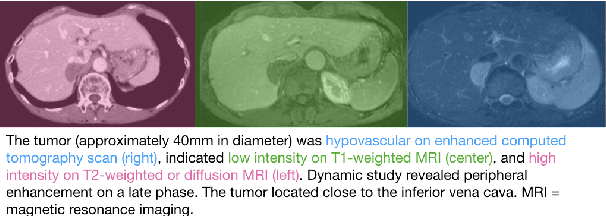
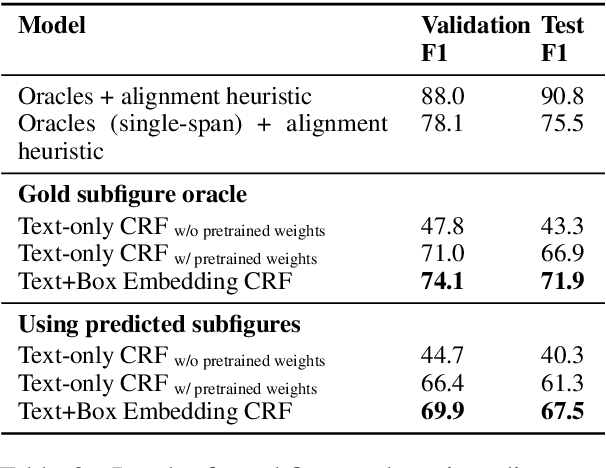
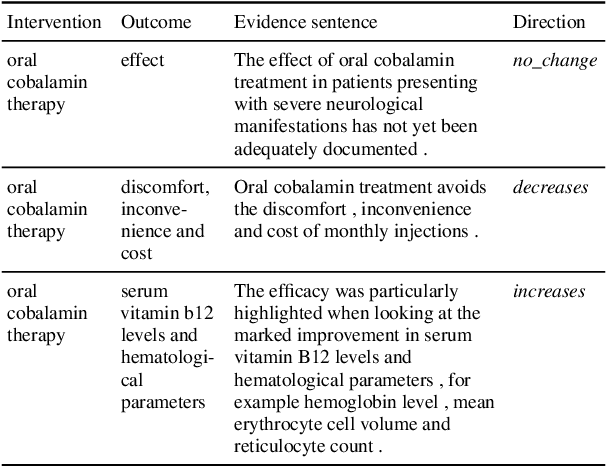
Understanding the relationship between figures and text is key to scientific document understanding. Medical figures in particular are quite complex, often consisting of several subfigures (75% of figures in our dataset), with detailed text describing their content. Previous work studying figures in scientific papers focused on classifying figure content rather than understanding how images relate to the text. To address challenges in figure retrieval and figure-to-text alignment, we introduce MedICaT, a dataset of medical images in context. MedICaT consists of 217K images from 131K open access biomedical papers, and includes captions, inline references for 74% of figures, and manually annotated subfigures and subcaptions for a subset of figures. Using MedICaT, we introduce the task of subfigure to subcaption alignment in compound figures and demonstrate the utility of inline references in image-text matching. Our data and code can be accessed at https://github.com/allenai/medicat.
Extracting a Knowledge Base of Mechanisms from COVID-19 Papers
Oct 08, 2020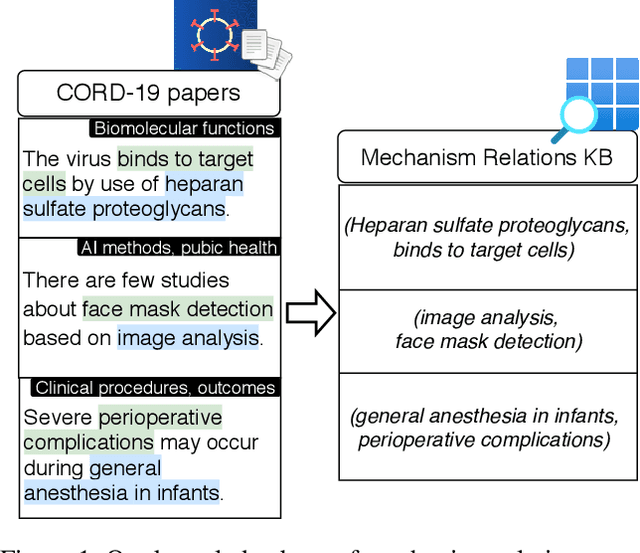
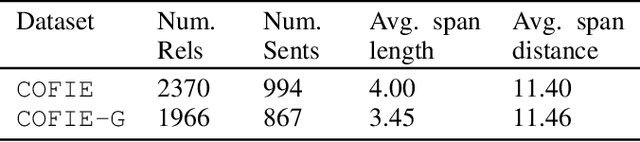

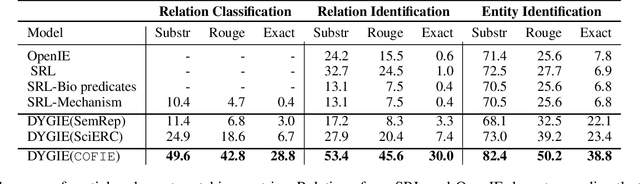
The urgency of mitigating COVID-19 has spawned a large and diverse body of scientific literature that is challenging for researchers to navigate. This explosion of information has stimulated interest in automated tools to help identify useful knowledge. We have pursued the use of methods for extracting diverse forms of mechanism relations from the natural language of scientific papers. We seek to identify concepts in COVID-19 and related literature which represent activities, functions, associations and causal relations, ranging from cellular processes to economic impacts. We formulate a broad, coarse-grained schema targeting mechanism relations between open, free-form entities. Our approach strikes a balance between expressivity and breadth that supports generalization across diverse concepts. We curate a dataset of scientific papers annotated according to our novel schema. Using an information extraction model trained on this new corpus, we construct a knowledge base (KB) of 2M mechanism relations, which we make publicly available. Our model is able to extract relations at an F1 at least twice that of baselines such as open IE or related scientific IE systems. We conduct experiments examining the ability of our system to retrieve relevant information on viral mechanisms of action, and on applications of AI to COVID-19 research. In both cases, our system identifies relevant information from our automatically-constructed knowledge base with high precision.
SciREX: A Challenge Dataset for Document-Level Information Extraction
May 01, 2020

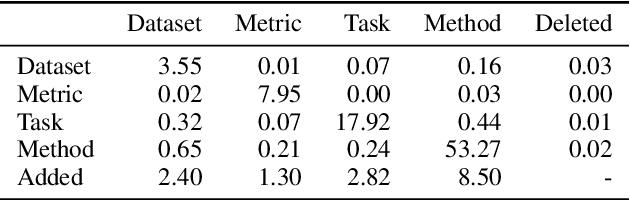

Extracting information from full documents is an important problem in many domains, but most previous work focus on identifying relationships within a sentence or a paragraph. It is challenging to create a large-scale information extraction (IE) dataset at the document level since it requires an understanding of the whole document to annotate entities and their document-level relationships that usually span beyond sentences or even sections. In this paper, we introduce SciREX, a document level IE dataset that encompasses multiple IE tasks, including salient entity identification and document level $N$-ary relation identification from scientific articles. We annotate our dataset by integrating automatic and human annotations, leveraging existing scientific knowledge resources. We develop a neural model as a strong baseline that extends previous state-of-the-art IE models to document-level IE. Analyzing the model performance shows a significant gap between human performance and current baselines, inviting the community to use our dataset as a challenge to develop document-level IE models. Our data and code are publicly available at https://github.com/allenai/SciREX
Fact or Fiction: Verifying Scientific Claims
May 01, 2020


We introduce the task of scientific fact-checking. Given a corpus of scientific articles and a claim about a scientific finding, a fact-checking model must identify abstracts that support or refute the claim. In addition, it must provide rationales for its predictions in the form of evidentiary sentences from the retrieved abstracts. For this task, we introduce SciFact, a dataset of 1.4K expert-written scientific claims paired with evidence-containing abstracts, and annotated with labels and rationales. We present a baseline model and assess its performance on SciFact. We observe that, while fact-checking models trained on Wikipedia articles or political news have difficulty generalizing to our task, simple domain adaptation techniques represent a promising avenue for improvement. Finally, we provide initial results showing how our model can be used to verify claims relevant to COVID-19 on the CORD-19 corpus. Our dataset will be made publicly available at https://github.com/allenai/scifact.
Structural Scaffolds for Citation Intent Classification in Scientific Publications
Apr 02, 2019
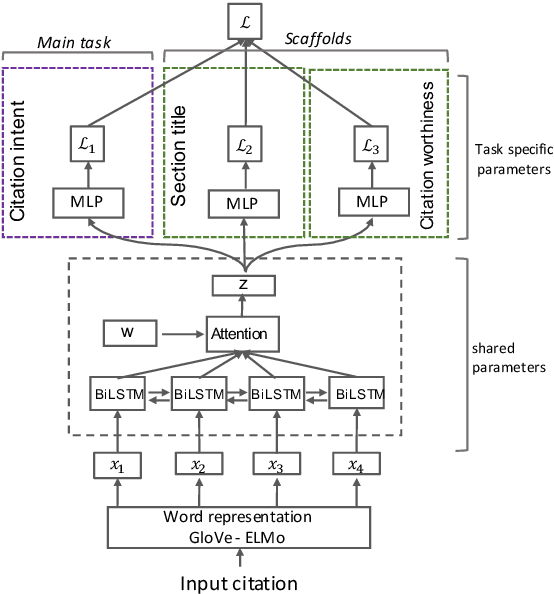

Identifying the intent of a citation in scientific papers (e.g., background information, use of methods, comparing results) is critical for machine reading of individual publications and automated analysis of the scientific literature. We propose structural scaffolds, a multitask model to incorporate structural information of scientific papers into citations for effective classification of citation intents. Our model achieves a new state-of-the-art on an existing ACL anthology dataset (ACL-ARC) with a 13.3% absolute increase in F1 score, without relying on external linguistic resources or hand-engineered features as done in existing methods. In addition, we introduce a new dataset of citation intents (SciCite) which is more than five times larger and covers multiple scientific domains compared with existing datasets. Our code and data are available at: https://github.com/allenai/scicite.
Construction of the Literature Graph in Semantic Scholar
May 06, 2018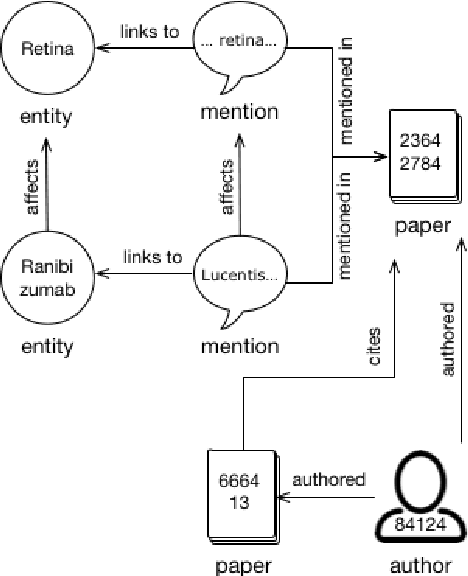

We describe a deployed scalable system for organizing published scientific literature into a heterogeneous graph to facilitate algorithmic manipulation and discovery. The resulting literature graph consists of more than 280M nodes, representing papers, authors, entities and various interactions between them (e.g., authorships, citations, entity mentions). We reduce literature graph construction into familiar NLP tasks (e.g., entity extraction and linking), point out research challenges due to differences from standard formulations of these tasks, and report empirical results for each task. The methods described in this paper are used to enable semantic features in www.semanticscholar.org
A Dataset of Peer Reviews : Collection, Insights and NLP Applications
Apr 25, 2018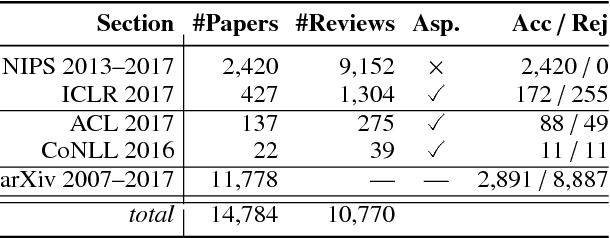
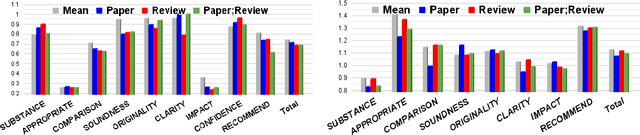
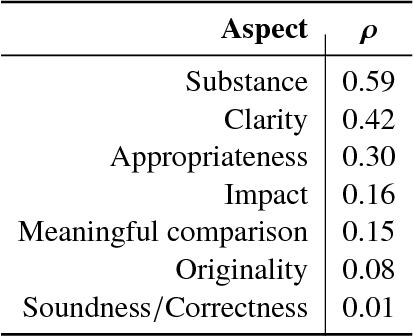
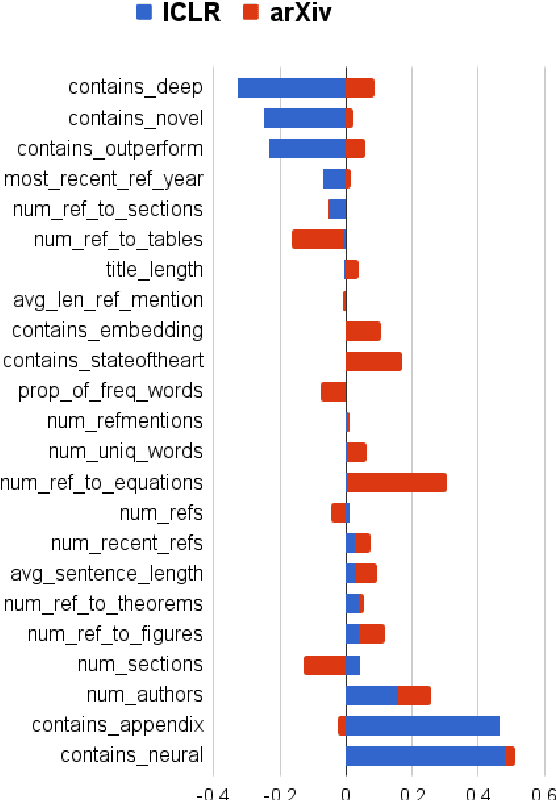
Peer reviewing is a central component in the scientific publishing process. We present the first public dataset of scientific peer reviews available for research purposes (PeerRead v1) providing an opportunity to study this important artifact. The dataset consists of 14.7K paper drafts and the corresponding accept/reject decisions in top-tier venues including ACL, NIPS and ICLR. The dataset also includes 10.7K textual peer reviews written by experts for a subset of the papers. We describe the data collection process and report interesting observed phenomena in the peer reviews. We also propose two novel NLP tasks based on this dataset and provide simple baseline models. In the first task, we show that simple models can predict whether a paper is accepted with up to 21% error reduction compared to the majority baseline. In the second task, we predict the numerical scores of review aspects and show that simple models can outperform the mean baseline for aspects with high variance such as 'originality' and 'impact'.