 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Semantic Scholar Open Data Platform
Jan 24, 2023



The volume of scientific output is creating an urgent need for automated tools to help scientists keep up with developments in their field. Semantic Scholar (S2) is an open data platform and website aimed at accelerating science by helping scholars discover and understand scientific literature. We combine public and proprietary data sources using state-of-the-art techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date, with 200M+ papers, 80M+ authors, 550M+ paper-authorship edges, and 2.4B+ citation edges. The graph includes advanced semantic features such as structurally parsed text, natural language summaries, and vector embeddings. In this paper, we describe the components of the S2 data processing pipeline and the associated APIs offered by the platform. We will update this living document to reflect changes as we add new data offerings and improve existing services.
Overview of the TREC 2020 Fair Ranking Track
Aug 11, 2021

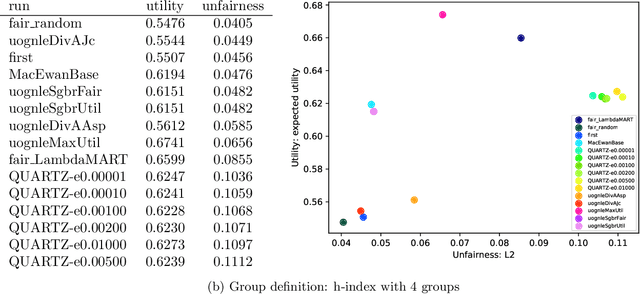
This paper provides an overview of the NIST TREC 2020 Fair Ranking track. For 2020, we again adopted an academic search task, where we have a corpus of academic article abstracts and queries submitted to a production academic search engine. The central goal of the Fair Ranking track is to provide fair exposure to different groups of authors (a group fairness framing). We recognize that there may be multiple group definitions (e.g. based on demographics, stature, topic) and hoped for the systems to be robust to these. We expected participants to develop systems that optimize for fairness and relevance for arbitrary group definitions, and did not reveal the exact group definitions until after the evaluation runs were submitted.The track contains two tasks,reranking and retrieval, with a shared evaluation.
CORD-19: The Covid-19 Open Research Dataset
Apr 25, 2020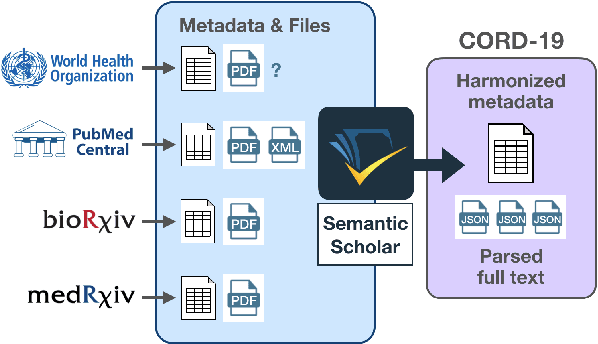
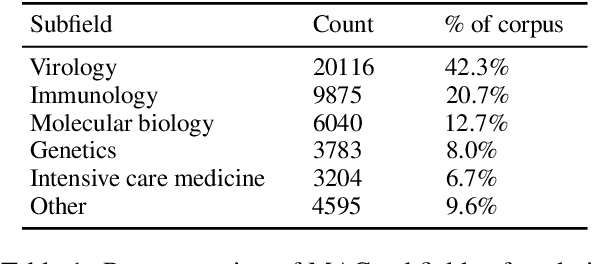
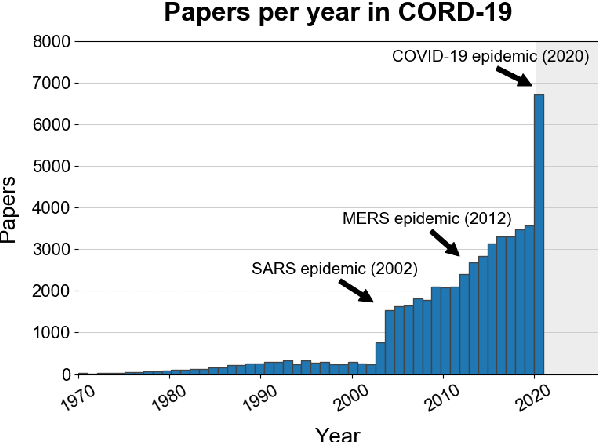

The Covid-19 Open Research Dataset (CORD-19) is a growing resource of scientific papers on Covid-19 and related historical coronavirus research. CORD-19 is designed to facilitate the development of text mining and information retrieval systems over its rich collection of metadata and structured full text papers. Since its release, CORD-19 has been downloaded over 75K times and has served as the basis of many Covid-19 text mining and discovery systems. In this article, we describe the mechanics of dataset construction, highlighting challenges and key design decisions, provide an overview of how CORD-19 has been used, and preview tools and upcoming shared tasks built around the dataset. We hope this resource will continue to bring together the computing community, biomedical experts, and policy makers in the search for effective treatments and management policies for Covid-19.
Overview of the TREC 2019 Fair Ranking Track
Mar 25, 2020The goal of the TREC Fair Ranking track was to develop a benchmark for evaluating retrieval systems in terms of fairness to different content providers in addition to classic notions of relevance. As part of the benchmark, we defined standardized fairness metrics with evaluation protocols and released a dataset for the fair ranking problem. The 2019 task focused on reranking academic paper abstracts given a query. The objective was to fairly represent relevant authors from several groups that were unknown at the system submission time. Thus, the track emphasized the development of systems which have robust performance across a variety of group definitions. Participants were provided with querylog data (queries, documents, and relevance) from Semantic Scholar. This paper presents an overview of the track, including the task definition, descriptions of the data and the annotation process, as well as a comparison of the performance of submitted systems.
Construction of the Literature Graph in Semantic Scholar
May 06, 2018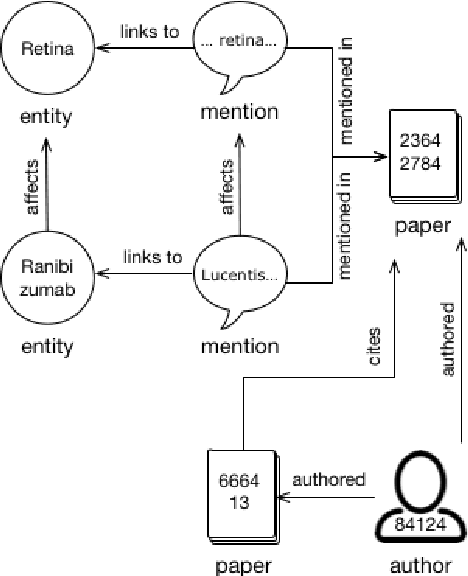
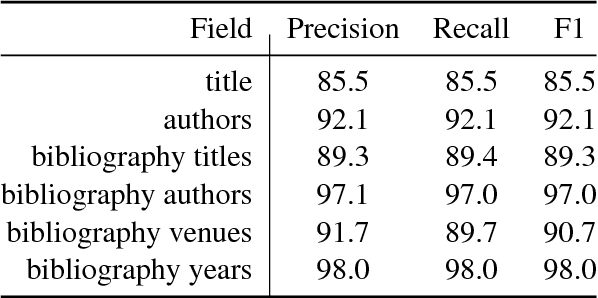
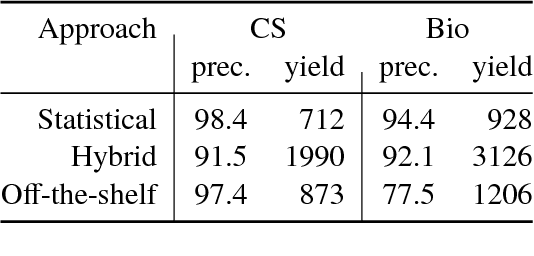

We describe a deployed scalable system for organizing published scientific literature into a heterogeneous graph to facilitate algorithmic manipulation and discovery. The resulting literature graph consists of more than 280M nodes, representing papers, authors, entities and various interactions between them (e.g., authorships, citations, entity mentions). We reduce literature graph construction into familiar NLP tasks (e.g., entity extraction and linking), point out research challenges due to differences from standard formulations of these tasks, and report empirical results for each task. The methods described in this paper are used to enable semantic features in www.semanticscholar.org
A Dataset of Peer Reviews : Collection, Insights and NLP Applications
Apr 25, 2018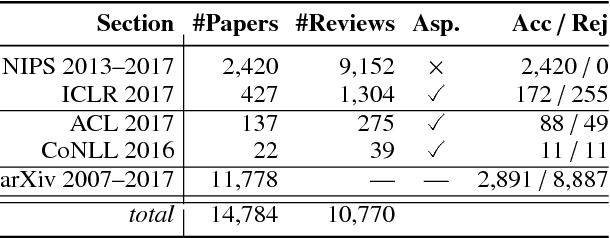
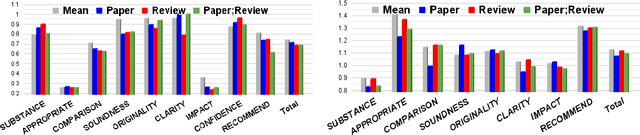
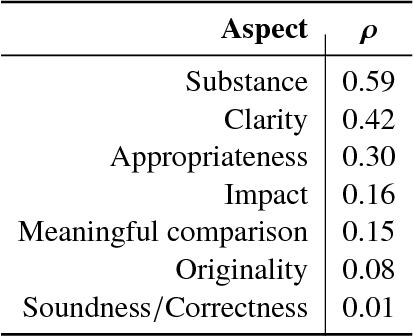
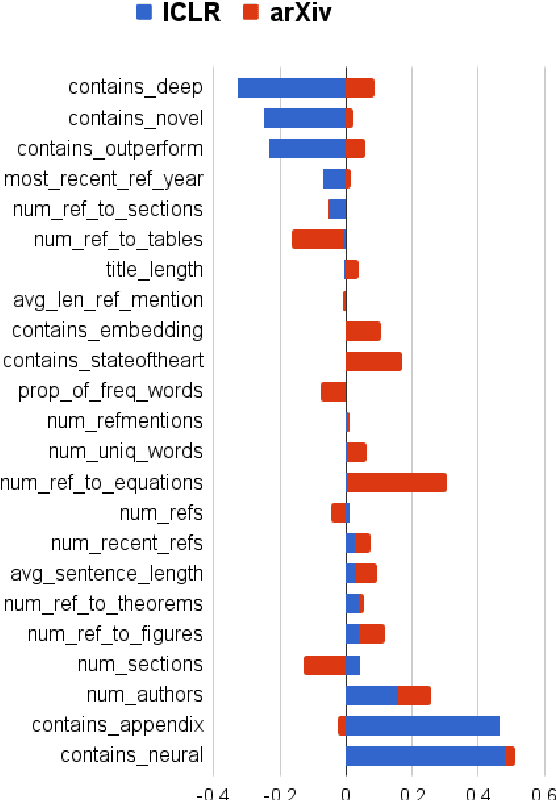
Peer reviewing is a central component in the scientific publishing process. We present the first public dataset of scientific peer reviews available for research purposes (PeerRead v1) providing an opportunity to study this important artifact. The dataset consists of 14.7K paper drafts and the corresponding accept/reject decisions in top-tier venues including ACL, NIPS and ICLR. The dataset also includes 10.7K textual peer reviews written by experts for a subset of the papers. We describe the data collection process and report interesting observed phenomena in the peer reviews. We also propose two novel NLP tasks based on this dataset and provide simple baseline models. In the first task, we show that simple models can predict whether a paper is accepted with up to 21% error reduction compared to the majority baseline. In the second task, we predict the numerical scores of review aspects and show that simple models can outperform the mean baseline for aspects with high variance such as 'originality' and 'impact'.