 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Durable Algorithmic Recourse
Sep 26, 2025Algorithmic recourse seeks to provide individuals with actionable recommendations that increase their chances of receiving favorable outcomes from automated decision systems (e.g., loan approvals). While prior research has emphasized robustness to model updates, considerably less attention has been given to the temporal dynamics of recourse--particularly in competitive, resource-constrained settings where recommendations shape future applicant pools. In this work, we present a novel time-aware framework for algorithmic recourse, explicitly modeling how candidate populations adapt in response to recommendations. Additionally, we introduce a novel reinforcement learning (RL)-based recourse algorithm that captures the evolving dynamics of the environment to generate recommendations that are both feasible and valid. We design our recommendations to be durable, supporting validity over a predefined time horizon T. This durability allows individuals to confidently reapply after taking time to implement the suggested changes. Through extensive experiments in complex simulation environments, we show that our approach substantially outperforms existing baselines, offering a superior balance between feasibility and long-term validity. Together, these results underscore the importance of incorporating temporal and behavioral dynamics into the design of practical recourse systems.
Fairness and Bias in Algorithmic Hiring
Sep 25, 2023


Employers are adopting algorithmic hiring technology throughout the recruitment pipeline. Algorithmic fairness is especially applicable in this domain due to its high stakes and structural inequalities. Unfortunately, most work in this space provides partial treatment, often constrained by two competing narratives, optimistically focused on replacing biased recruiter decisions or pessimistically pointing to the automation of discrimination. Whether, and more importantly what types of, algorithmic hiring can be less biased and more beneficial to society than low-tech alternatives currently remains unanswered, to the detriment of trustworthiness. This multidisciplinary survey caters to practitioners and researchers with a balanced and integrated coverage of systems, biases, measures, mitigation strategies, datasets, and legal aspects of algorithmic hiring and fairness. Our work supports a contextualized understanding and governance of this technology by highlighting current opportunities and limitations, providing recommendations for future work to ensure shared benefits for all stakeholders.
(Re)Politicizing Digital Well-Being: Beyond User Engagements
Mar 15, 2022
The psychological costs of the attention economy are often considered through the binary of harmful design and healthy use, with digital well-being chiefly characterised as a matter of personal responsibility. This article adopts an interdisciplinary approach to highlight the empirical, ideological, and political limits of embedding this individualised perspective in computational discourses and designs of digital well-being measurement. We will reveal well-being to be a culturally specific and environmentally conditioned concept and will problematize user engagement as a universal proxy for well-being. Instead, the contributing factors of user well-being will be located in environing social, cultural, and political conditions far beyond the control of individual users alone. In doing so, we hope to reinvigorate the issue of digital well-being measurement as a nexus point of political concern, through which multiple disciplines can study experiences of digital ill as symptomatic of wider social inequalities and (capitalist) relations of power.
Exposing Query Identification for Search Transparency
Oct 14, 2021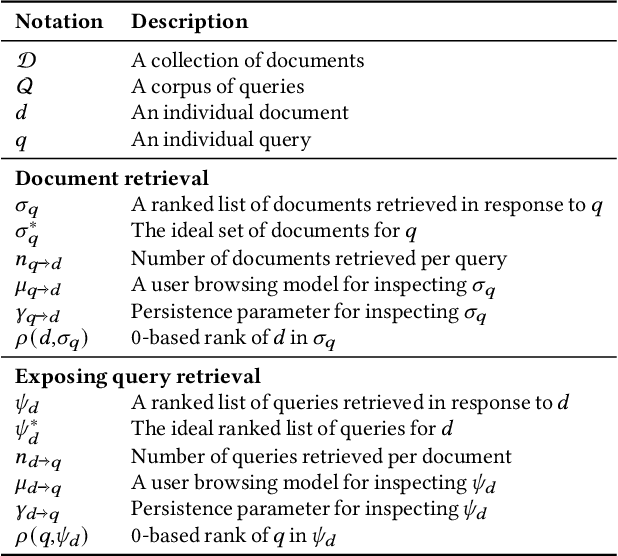

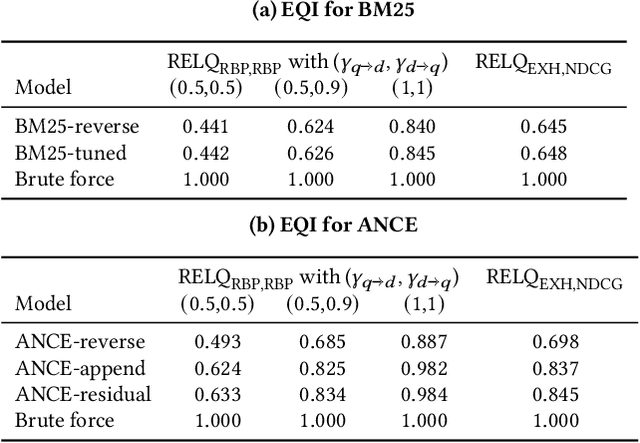
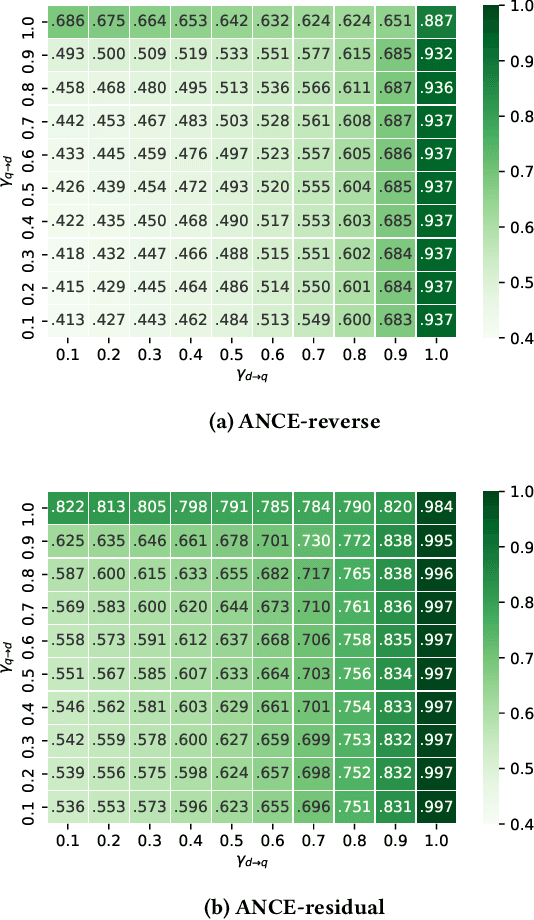
Search systems control the exposure of ranked content to searchers. In many cases, creators value not only the exposure of their content but, moreover, an understanding of the specific searches where the content is surfaced. The problem of identifying which queries expose a given piece of content in the ranking results is an important and relatively under-explored search transparency challenge. Exposing queries are useful for quantifying various issues of search bias, privacy, data protection, security, and search engine optimization. Exact identification of exposing queries in a given system is computationally expensive, especially in dynamic contexts such as web search. In quest of a more lightweight solution, we explore the feasibility of approximate exposing query identification (EQI) as a retrieval task by reversing the role of queries and documents in two classes of search systems: dense dual-encoder models and traditional BM25 models. We then propose how this approach can be improved through metric learning over the retrieval embedding space. We further derive an evaluation metric to measure the quality of a ranking of exposing queries, as well as conducting an empirical analysis focusing on various practical aspects of approximate EQI.
Overview of the TREC 2020 Fair Ranking Track
Aug 11, 2021

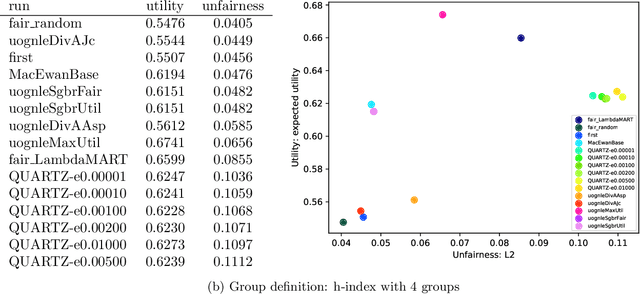
This paper provides an overview of the NIST TREC 2020 Fair Ranking track. For 2020, we again adopted an academic search task, where we have a corpus of academic article abstracts and queries submitted to a production academic search engine. The central goal of the Fair Ranking track is to provide fair exposure to different groups of authors (a group fairness framing). We recognize that there may be multiple group definitions (e.g. based on demographics, stature, topic) and hoped for the systems to be robust to these. We expected participants to develop systems that optimize for fairness and relevance for arbitrary group definitions, and did not reveal the exact group definitions until after the evaluation runs were submitted.The track contains two tasks,reranking and retrieval, with a shared evaluation.
Operationalizing the Legal Principle of Data Minimization for Personalization
May 28, 2020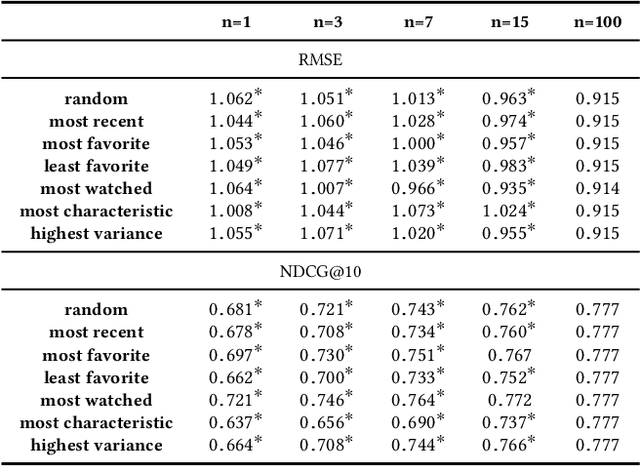
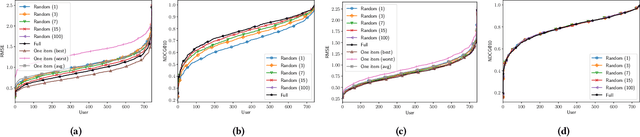
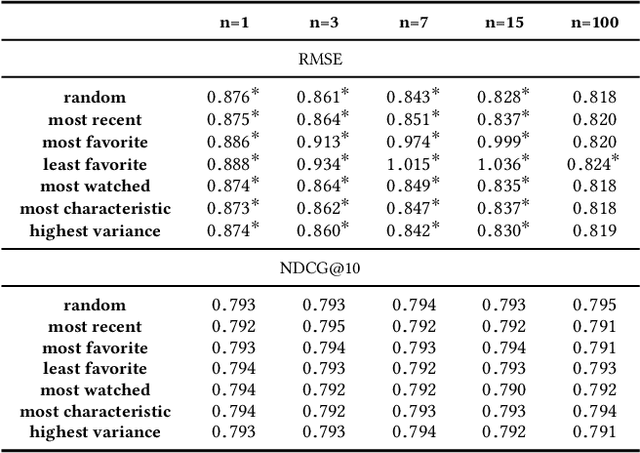
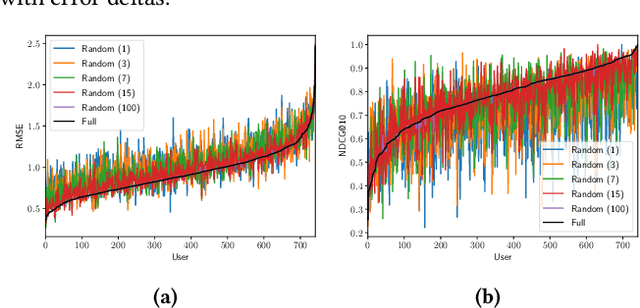
Article 5(1)(c) of the European Union's General Data Protection Regulation (GDPR) requires that "personal data shall be [...] adequate, relevant, and limited to what is necessary in relation to the purposes for which they are processed (`data minimisation')". To date, the legal and computational definitions of `purpose limitation' and `data minimization' remain largely unclear. In particular, the interpretation of these principles is an open issue for information access systems that optimize for user experience through personalization and do not strictly require personal data collection for the delivery of basic service. In this paper, we identify a lack of a homogeneous interpretation of the data minimization principle and explore two operational definitions applicable in the context of personalization. The focus of our empirical study in the domain of recommender systems is on providing foundational insights about the (i) feasibility of different data minimization definitions, (ii) robustness of different recommendation algorithms to minimization, and (iii) performance of different minimization strategies.We find that the performance decrease incurred by data minimization might not be substantial, but that it might disparately impact different users---a finding which has implications for the viability of different formal minimization definitions. Overall, our analysis uncovers the complexities of the data minimization problem in the context of personalization and maps the remaining computational and regulatory challenges.
Overview of the TREC 2019 Fair Ranking Track
Mar 25, 2020The goal of the TREC Fair Ranking track was to develop a benchmark for evaluating retrieval systems in terms of fairness to different content providers in addition to classic notions of relevance. As part of the benchmark, we defined standardized fairness metrics with evaluation protocols and released a dataset for the fair ranking problem. The 2019 task focused on reranking academic paper abstracts given a query. The objective was to fairly represent relevant authors from several groups that were unknown at the system submission time. Thus, the track emphasized the development of systems which have robust performance across a variety of group definitions. Participants were provided with querylog data (queries, documents, and relevance) from Semantic Scholar. This paper presents an overview of the track, including the task definition, descriptions of the data and the annotation process, as well as a comparison of the performance of submitted systems.