 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperationalizing the Legal Principle of Data Minimization for Personalization
May 28, 2020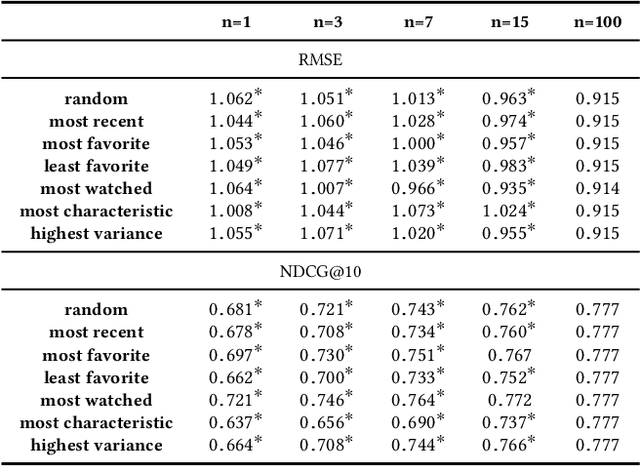
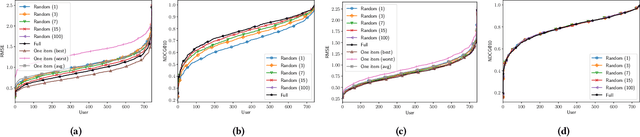
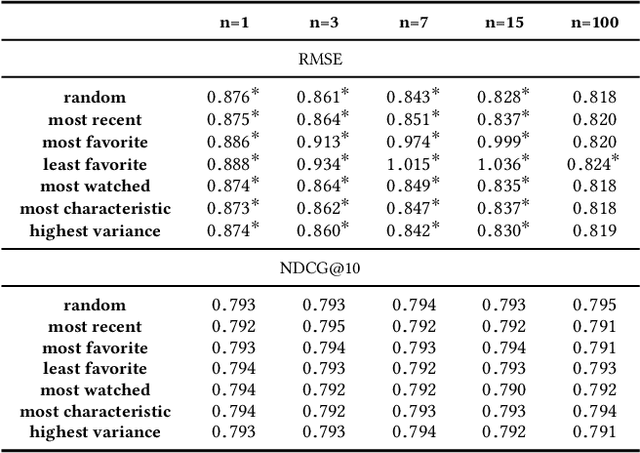
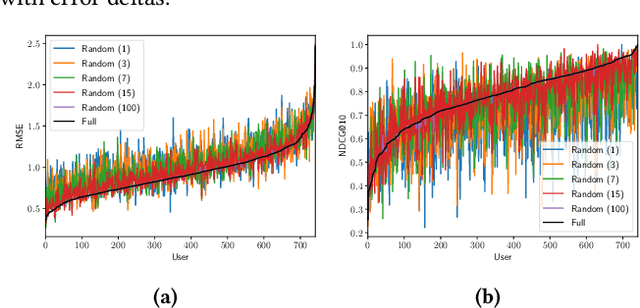
Article 5(1)(c) of the European Union's General Data Protection Regulation (GDPR) requires that "personal data shall be [...] adequate, relevant, and limited to what is necessary in relation to the purposes for which they are processed (`data minimisation')". To date, the legal and computational definitions of `purpose limitation' and `data minimization' remain largely unclear. In particular, the interpretation of these principles is an open issue for information access systems that optimize for user experience through personalization and do not strictly require personal data collection for the delivery of basic service. In this paper, we identify a lack of a homogeneous interpretation of the data minimization principle and explore two operational definitions applicable in the context of personalization. The focus of our empirical study in the domain of recommender systems is on providing foundational insights about the (i) feasibility of different data minimization definitions, (ii) robustness of different recommendation algorithms to minimization, and (iii) performance of different minimization strategies.We find that the performance decrease incurred by data minimization might not be substantial, but that it might disparately impact different users---a finding which has implications for the viability of different formal minimization definitions. Overall, our analysis uncovers the complexities of the data minimization problem in the context of personalization and maps the remaining computational and regulatory challenges.
Playing log(N)-Questions over Sentences
Aug 13, 2019
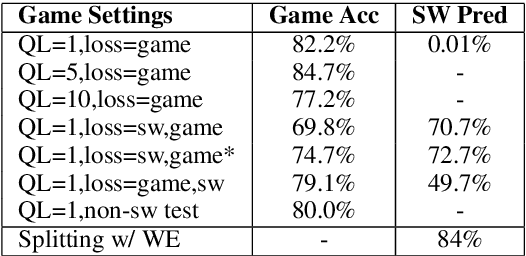
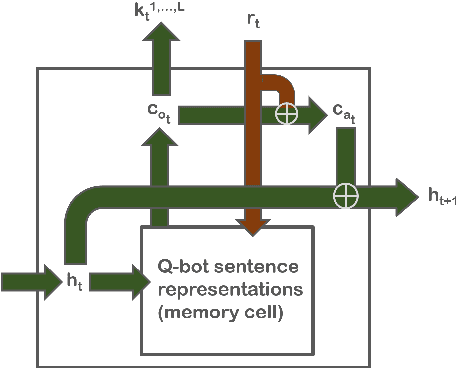

We propose a two-agent game wherein a questioner must be able to conjure discerning questions between sentences, incorporate responses from an answerer, and keep track of a hypothesis state. The questioner must be able to understand the information required to make its final guess, while also being able to reason over the game's text environment based on the answerer's responses. We experiment with an end-to-end model where both agents can learn simultaneously to play the game, showing that simultaneously achieving high game accuracy and producing meaningful questions can be a difficult trade-off.
The Effect of Downstream Classification Tasks for Evaluating Sentence Embeddings
Apr 03, 2019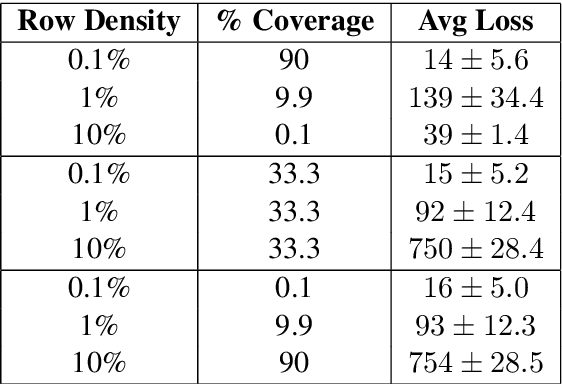


One popular method for quantitatively evaluating the performance of sentence embeddings involves their usage on downstream language processing tasks that require sentence representations as input. One simple such task is classification, where the sentence representations are used to train and test models on several classification datasets. We argue that by evaluating sentence representations in such a manner, the goal of the representations becomes learning a low-dimensional factorization of a sentence-task label matrix. We show how characteristics of this matrix can affect the ability for a low-dimensional factorization to perform as sentence representations in a suite of classification tasks. Primarily, sentences that have more labels across all possible classification tasks have a higher reconstruction loss, though this effect can be drastically negated if the amount of such sentences is small.
Here's My Point: Joint Pointer Architecture for Argument Mining
May 08, 2017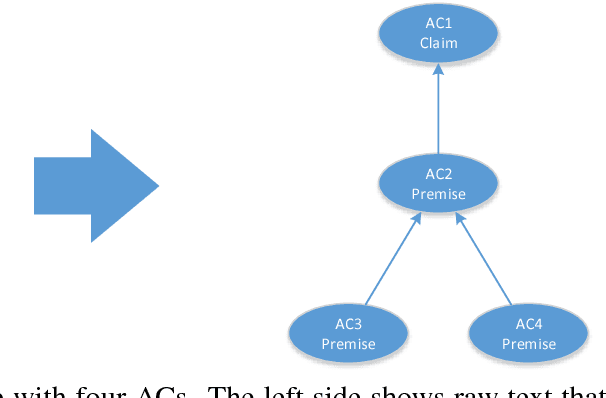
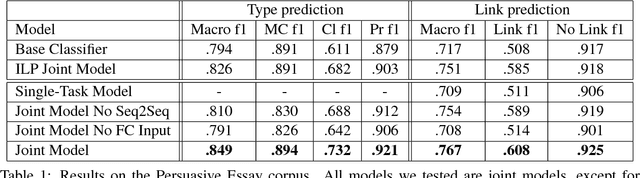
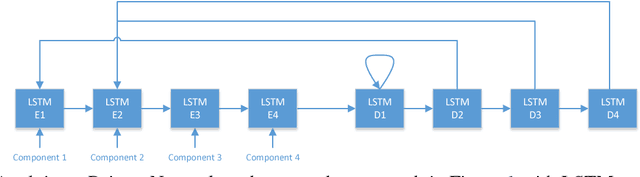
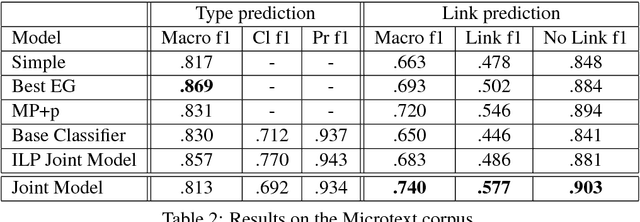
One of the major goals in automated argumentation mining is to uncover the argument structure present in argumentative text. In order to determine this structure, one must understand how different individual components of the overall argument are linked. General consensus in this field dictates that the argument components form a hierarchy of persuasion, which manifests itself in a tree structure. This work provides the first neural network-based approach to argumentation mining, focusing on the two tasks of extracting links between argument components, and classifying types of argument components. In order to solve this problem, we propose to use a joint model that is based on a Pointer Network architecture. A Pointer Network is appealing for this task for the following reasons: 1) It takes into account the sequential nature of argument components; 2) By construction, it enforces certain properties of the tree structure present in argument relations; 3) The hidden representations can be applied to auxiliary tasks. In order to extend the contribution of the original Pointer Network model, we construct a joint model that simultaneously attempts to learn the type of argument component, as well as continuing to predict links between argument components. The proposed joint model achieves state-of-the-art results on two separate evaluation corpora, achieving far superior performance than a regular Pointer Network model. Our results show that optimizing for both tasks, and adding a fully-connected layer prior to recurrent neural network input, is crucial for high performance.
#HashtagWars: Learning a Sense of Humor
Apr 15, 2017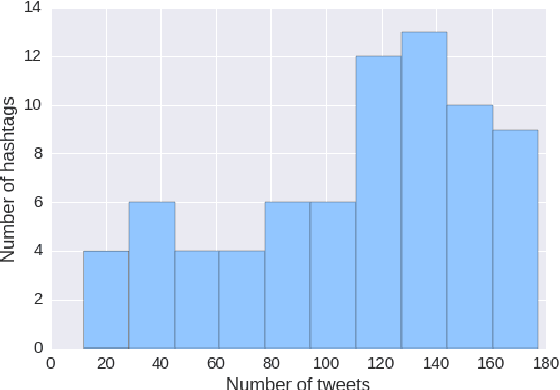


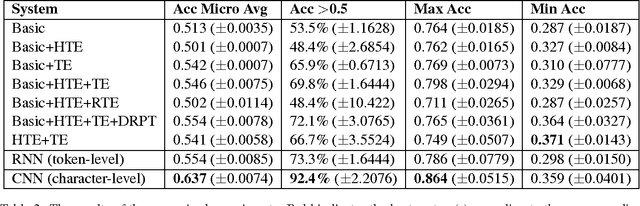
In this work, we present a new dataset for computational humor, specifically comparative humor ranking, which attempts to eschew the ubiquitous binary approach to humor detection. The dataset consists of tweets that are humorous responses to a given hashtag. We describe the motivation for this new dataset, as well as the collection process, which includes a description of our semi-automated system for data collection. We also present initial experiments for this dataset using both unsupervised and supervised approaches. Our best supervised system achieved 63.7% accuracy, suggesting that this task is much more difficult than comparable humor detection tasks. Initial experiments indicate that a character-level model is more suitable for this task than a token-level model, likely due to a large amount of puns that can be captured by a character-level model.
Evaluating Creative Language Generation: The Case of Rap Lyric Ghostwriting
Dec 09, 2016


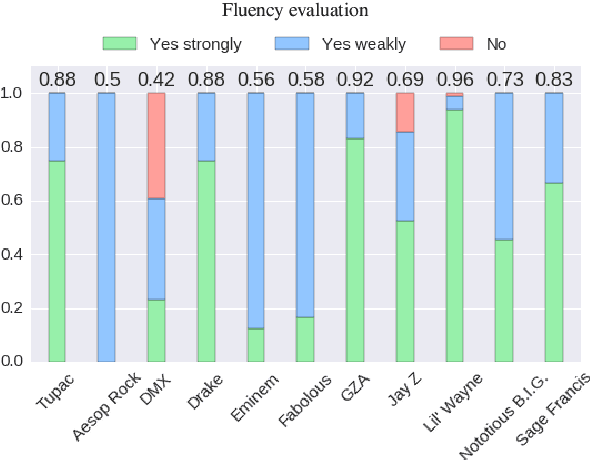
Language generation tasks that seek to mimic human ability to use language creatively are difficult to evaluate, since one must consider creativity, style, and other non-trivial aspects of the generated text. The goal of this paper is to develop evaluation methods for one such task, ghostwriting of rap lyrics, and to provide an explicit, quantifiable foundation for the goals and future directions of this task. Ghostwriting must produce text that is similar in style to the emulated artist, yet distinct in content. We develop a novel evaluation methodology that addresses several complementary aspects of this task, and illustrate how such evaluation can be used to meaningfully analyze system performance. We provide a corpus of lyrics for 13 rap artists, annotated for stylistic similarity, which allows us to assess the feasibility of manual evaluation for generated verse.