 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Downstream Classification Tasks for Evaluating Sentence Embeddings
Paper and Code
Apr 03, 2019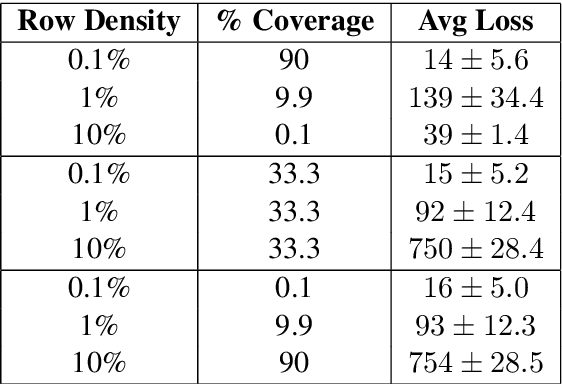


One popular method for quantitatively evaluating the performance of sentence embeddings involves their usage on downstream language processing tasks that require sentence representations as input. One simple such task is classification, where the sentence representations are used to train and test models on several classification datasets. We argue that by evaluating sentence representations in such a manner, the goal of the representations becomes learning a low-dimensional factorization of a sentence-task label matrix. We show how characteristics of this matrix can affect the ability for a low-dimensional factorization to perform as sentence representations in a suite of classification tasks. Primarily, sentences that have more labels across all possible classification tasks have a higher reconstruction loss, though this effect can be drastically negated if the amount of such sentences is small.