 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge#HashtagWars: Learning a Sense of Humor
Paper and Code
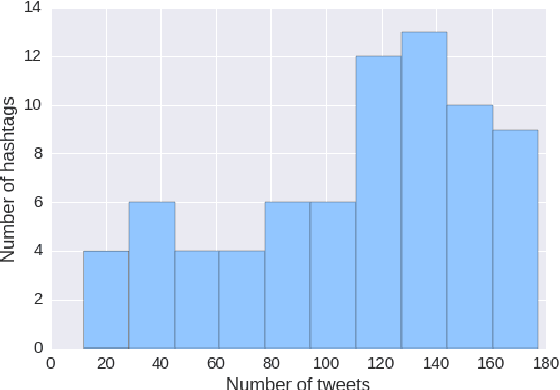


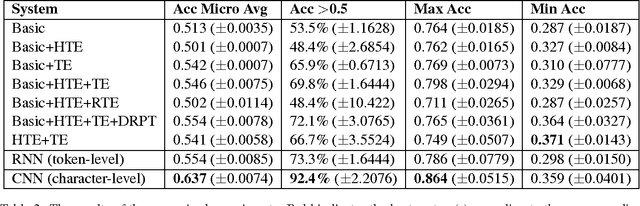
In this work, we present a new dataset for computational humor, specifically comparative humor ranking, which attempts to eschew the ubiquitous binary approach to humor detection. The dataset consists of tweets that are humorous responses to a given hashtag. We describe the motivation for this new dataset, as well as the collection process, which includes a description of our semi-automated system for data collection. We also present initial experiments for this dataset using both unsupervised and supervised approaches. Our best supervised system achieved 63.7% accuracy, suggesting that this task is much more difficult than comparable humor detection tasks. Initial experiments indicate that a character-level model is more suitable for this task than a token-level model, likely due to a large amount of puns that can be captured by a character-level model.