 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI, Climate, and Regulation: From Data Centers to the AI Act
Oct 09, 2024

We live in a world that is experiencing an unprecedented boom of AI applications that increasingly penetrate and enhance all sectors of private and public life, from education, media, medicine, and mobility to the industrial and professional workspace, and -- potentially particularly consequentially -- robotics. As this world is simultaneously grappling with climate change, the climate and environmental implications of the development and use of AI have become an important subject of public and academic debate. In this paper, we aim to provide guidance on the climate-related regulation for data centers and AI specifically, and discuss how to operationalize these requirements. We also highlight challenges and room for improvement, and make a number of policy proposals to this end. In particular, we propose a specific interpretation of the AI Act to bring reporting on the previously unadressed energy consumption from AI inferences back into the scope. We also find that the AI Act fails to address indirect greenhouse gas emissions from AI applications. Furthermore, for the purpose of energy consumption reporting, we compare levels of measurement within data centers and recommend measurement at the cumulative server level. We also argue for an interpretation of the AI Act that includes environmental concerns in the mandatory risk assessment (sustainability risk assessment, SIA), and provide guidance on its operationalization. The EU data center regulation proves to be a good first step but requires further development by including binding renewable energy and efficiency targets for data centers. Overall, we make twelve concrete policy proposals, in four main areas: Energy and Environmental Reporting Obligations; Legal and Regulatory Clarifications; Transparency and Accountability Mechanisms; and Future Far-Reaching Measures beyond Transparency.
Generative AI in EU Law: Liability, Privacy, Intellectual Property, and Cybersecurity
Jan 14, 2024The advent of Generative AI, particularly through Large Language Models (LLMs) like ChatGPT and its successors, marks a paradigm shift in the AI landscape. Advanced LLMs exhibit multimodality, handling diverse data formats, thereby broadening their application scope. However, the complexity and emergent autonomy of these models introduce challenges in predictability and legal compliance. This paper delves into the legal and regulatory implications of Generative AI and LLMs in the European Union context, analyzing aspects of liability, privacy, intellectual property, and cybersecurity. It critically examines the adequacy of the existing and proposed EU legislation, including the Artificial Intelligence Act (AIA) draft, in addressing the unique challenges posed by Generative AI in general and LLMs in particular. The paper identifies potential gaps and shortcomings in the legislative framework and proposes recommendations to ensure the safe and compliant deployment of generative models, ensuring they align with the EU's evolving digital landscape and legal standards.
AI Regulation in Europe: From the AI Act to Future Regulatory Challenges
Oct 06, 2023This chapter provides a comprehensive discussion on AI regulation in the European Union, contrasting it with the more sectoral and self-regulatory approach in the UK. It argues for a hybrid regulatory strategy that combines elements from both philosophies, emphasizing the need for agility and safe harbors to ease compliance. The paper examines the AI Act as a pioneering legislative effort to address the multifaceted challenges posed by AI, asserting that, while the Act is a step in the right direction, it has shortcomings that could hinder the advancement of AI technologies. The paper also anticipates upcoming regulatory challenges, such as the management of toxic content, environmental concerns, and hybrid threats. It advocates for immediate action to create protocols for regulated access to high-performance, potentially open-source AI systems. Although the AI Act is a significant legislative milestone, it needs additional refinement and global collaboration for the effective governance of rapidly evolving AI technologies.
Fairness and Bias in Algorithmic Hiring
Sep 25, 2023

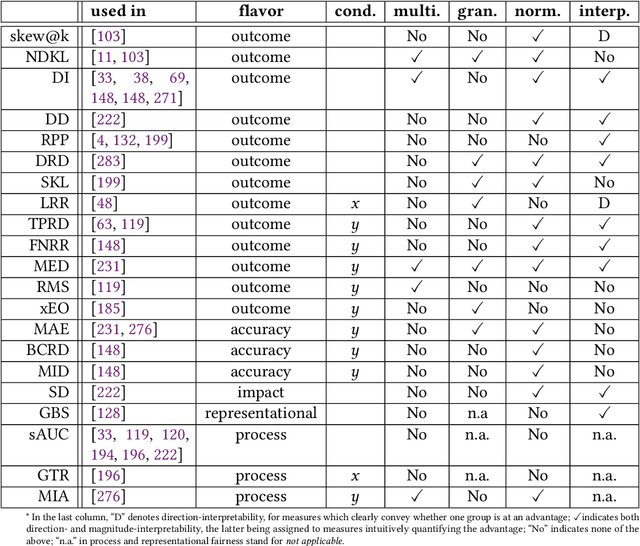

Employers are adopting algorithmic hiring technology throughout the recruitment pipeline. Algorithmic fairness is especially applicable in this domain due to its high stakes and structural inequalities. Unfortunately, most work in this space provides partial treatment, often constrained by two competing narratives, optimistically focused on replacing biased recruiter decisions or pessimistically pointing to the automation of discrimination. Whether, and more importantly what types of, algorithmic hiring can be less biased and more beneficial to society than low-tech alternatives currently remains unanswered, to the detriment of trustworthiness. This multidisciplinary survey caters to practitioners and researchers with a balanced and integrated coverage of systems, biases, measures, mitigation strategies, datasets, and legal aspects of algorithmic hiring and fairness. Our work supports a contextualized understanding and governance of this technology by highlighting current opportunities and limitations, providing recommendations for future work to ensure shared benefits for all stakeholders.
Regulating ChatGPT and other Large Generative AI Models
Feb 10, 2023Large generative AI models (LGAIMs), such as ChatGPT or Stable Diffusion, are rapidly transforming the way we communicate, illustrate, and create. However, AI regulation, in the EU and beyond, has primarily focused on conventional AI models, not LGAIMs. This paper will situate these new generative models in the current debate on trustworthy AI regulation, and ask how the law can be tailored to their capabilities. After laying technical foundations, the legal part of the paper proceeds in four steps, covering (1) direct regulation, (2) data protection, (3) content moderation, and (4) policy proposals. It suggests a novel terminology to capture the AI value chain in LGAIM settings by differentiating between LGAIM developers, deployers, professional and non-professional users, as well as recipients of LGAIM output. We tailor regulatory duties to these different actors along the value chain and suggest four strategies to ensure that LGAIMs are trustworthy and deployed for the benefit of society at large. Rules in the AI Act and other direct regulation must match the specificities of pre-trained models. In particular, regulation should focus on concrete high-risk applications, and not the pre-trained model itself, and should include (i) obligations regarding transparency and (ii) risk management. Non-discrimination provisions (iii) may, however, apply to LGAIM developers. Lastly, (iv) the core of the DSA content moderation rules should be expanded to cover LGAIMs. This includes notice and action mechanisms, and trusted flaggers. In all areas, regulators and lawmakers need to act fast to keep track with the dynamics of ChatGPT et al.
Regulating Gatekeeper AI and Data: Transparency, Access, and Fairness under the DMA, the GDPR, and beyond
Dec 09, 2022Artificial intelligence is not only increasingly used in business and administration contexts, but a race for its regulation is also underway, with the EU spearheading the efforts. Contrary to existing literature, this article suggests, however, that the most far-reaching and effective EU rules for AI applications in the digital economy will not be contained in the proposed AI Act - but have just been enacted in the Digital Markets Act. We analyze the impact of the DMA and related EU acts on AI models and their underlying data across four key areas: disclosure requirements; the regulation of AI training data; access rules; and the regime for fair rankings. The paper demonstrates that fairness, in the sense of the DMA, goes beyond traditionally protected categories of non-discrimination law on which scholarship at the intersection of AI and law has so far largely focused on. Rather, we draw on competition law and the FRAND criteria known from intellectual property law to interpret and refine the DMA provisions on fair rankings. Moreover, we show how, based on CJEU jurisprudence, a coherent interpretation of the concept of non-discrimination in both traditional non-discrimination and competition law may be found. The final part sketches specific proposals for a comprehensive framework of transparency, access, and fairness under the DMA and beyond.
The European AI Liability Directives -- Critique of a Half-Hearted Approach and Lessons for the Future
Dec 07, 2022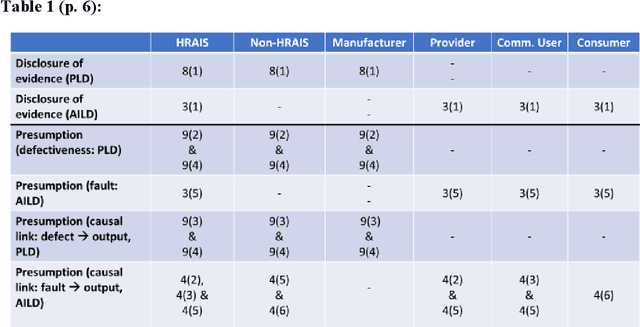

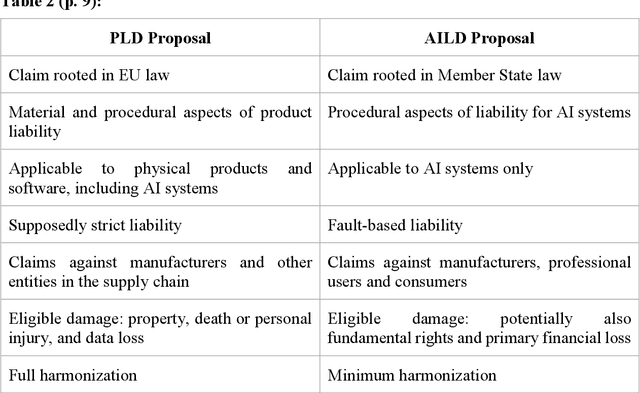

The optimal liability framework for AI systems remains an unsolved problem across the globe. In a much-anticipated move, the European Commission advanced two proposals outlining the European approach to AI liability in September 2022: a novel AI Liability Directive and a revision of the Product Liability Directive. They constitute the final, and much-anticipated, cornerstone of AI regulation in the EU. Crucially, the liability proposals and the EU AI Act are inherently intertwined: the latter does not contain any individual rights of affected persons, and the former lack specific, substantive rules on AI development and deployment. Taken together, these acts may well trigger a Brussels effect in AI regulation, with significant consequences for the US and other countries. This paper makes three novel contributions. First, it examines in detail the Commission proposals and shows that, while making steps in the right direction, they ultimately represent a half-hearted approach: if enacted as foreseen, AI liability in the EU will primarily rest on disclosure of evidence mechanisms and a set of narrowly defined presumptions concerning fault, defectiveness and causality. Hence, second, the article suggests amendments, which are collected in an Annex at the end of the paper. Third, based on an analysis of the key risks AI poses, the final part of the paper maps out a road for the future of AI liability and regulation, in the EU and beyond. This includes: a comprehensive framework for AI liability; provisions to support innovation; an extension to non-discrimination/algorithmic fairness, as well as explainable AI; and sustainability. I propose to jump-start sustainable AI regulation via sustainability impact assessments in the AI Act and sustainable design defects in the liability regime. In this way, the law may help spur not only fair AI and XAI, but potentially also sustainable AI (SAI).
A continuous framework for fairness
Dec 21, 2017


Increasingly, discrimination by algorithms is perceived as a societal and legal problem. As a response, a number of criteria for implementing algorithmic fairness in machine learning have been developed in the literature. This paper proposes the Continuous Fairness Algorithm (CFA$\theta$) which enables a continuous interpolation between different fairness definitions. More specifically, we make three main contributions to the existing literature. First, our approach allows the decision maker to continuously vary between concepts of individual and group fairness. As a consequence, the algorithm enables the decision maker to adopt intermediate "worldviews" on the degree of discrimination encoded in algorithmic processes, adding nuance to the extreme cases of "we're all equal" (WAE) and "what you see is what you get" (WYSIWYG) proposed so far in the literature. Second, we use optimal transport theory, and specifically the concept of the barycenter, to maximize decision maker utility under the chosen fairness constraints. Third, the algorithm is able to handle cases of intersectionality, i.e., of multi-dimensional discrimination of certain groups on grounds of several criteria. We discuss three main examples (college admissions; credit application; insurance contracts) and map out the policy implications of our approach. The explicit formalization of the trade-off between individual and group fairness allows this post-processing approach to be tailored to different situational contexts in which one or the other fairness criterion may take precedence.