 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI, Climate, and Regulation: From Data Centers to the AI Act
Oct 09, 2024

We live in a world that is experiencing an unprecedented boom of AI applications that increasingly penetrate and enhance all sectors of private and public life, from education, media, medicine, and mobility to the industrial and professional workspace, and -- potentially particularly consequentially -- robotics. As this world is simultaneously grappling with climate change, the climate and environmental implications of the development and use of AI have become an important subject of public and academic debate. In this paper, we aim to provide guidance on the climate-related regulation for data centers and AI specifically, and discuss how to operationalize these requirements. We also highlight challenges and room for improvement, and make a number of policy proposals to this end. In particular, we propose a specific interpretation of the AI Act to bring reporting on the previously unadressed energy consumption from AI inferences back into the scope. We also find that the AI Act fails to address indirect greenhouse gas emissions from AI applications. Furthermore, for the purpose of energy consumption reporting, we compare levels of measurement within data centers and recommend measurement at the cumulative server level. We also argue for an interpretation of the AI Act that includes environmental concerns in the mandatory risk assessment (sustainability risk assessment, SIA), and provide guidance on its operationalization. The EU data center regulation proves to be a good first step but requires further development by including binding renewable energy and efficiency targets for data centers. Overall, we make twelve concrete policy proposals, in four main areas: Energy and Environmental Reporting Obligations; Legal and Regulatory Clarifications; Transparency and Accountability Mechanisms; and Future Far-Reaching Measures beyond Transparency.
PatentMatch: A Dataset for Matching Patent Claims & Prior Art
Dec 27, 2020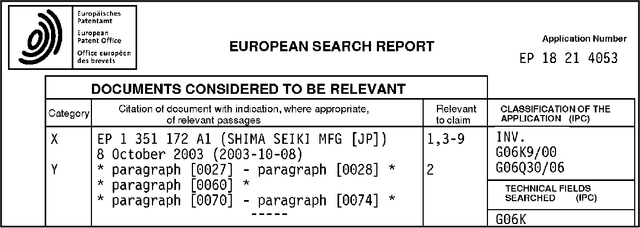
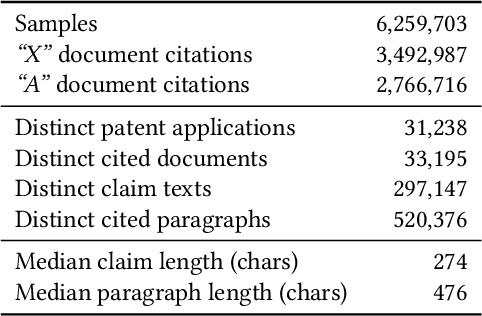
Patent examiners need to solve a complex information retrieval task when they assess the novelty and inventive step of claims made in a patent application. Given a claim, they search for prior art, which comprises all relevant publicly available information. This time-consuming task requires a deep understanding of the respective technical domain and the patent-domain-specific language. For these reasons, we address the computer-assisted search for prior art by creating a training dataset for supervised machine learning called PatentMatch. It contains pairs of claims from patent applications and semantically corresponding text passages of different degrees from cited patent documents. Each pair has been labeled by technically-skilled patent examiners from the European Patent Office. Accordingly, the label indicates the degree of semantic correspondence (matching), i.e., whether the text passage is prejudicial to the novelty of the claimed invention or not. Preliminary experiments using a baseline system show that PatentMatch can indeed be used for training a binary text pair classifier on this challenging information retrieval task. The dataset is available online: https://hpi.de/naumann/s/patentmatch.