 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Complex Concepts with Transformers: Matching Patent Claims Against Natural Language Text
Jul 14, 2024

A key capability in managing patent applications or a patent portfolio is comparing claims to other text, e.g. a patent specification. Because the language of claims is different from language used elsewhere in the patent application or in non-patent text, this has been challenging for computer based natural language processing. We test two new LLM-based approaches and find that both provide substantially better performance than previously published values. The ability to match dense information from one domain against much more distributed information expressed in a different vocabulary may also be useful beyond the intellectual property space.
Patent Sentiment Analysis to Highlight Patent Paragraphs
Nov 06, 2021
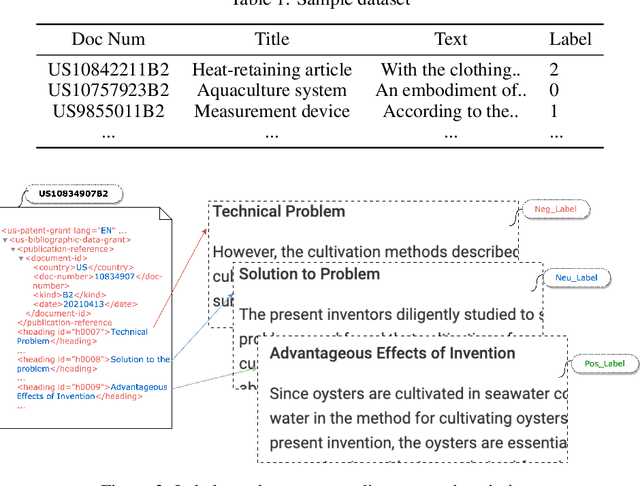
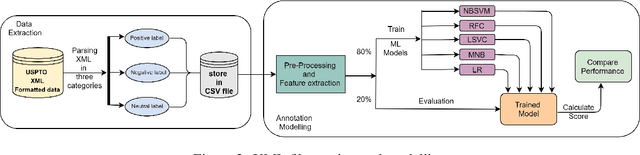
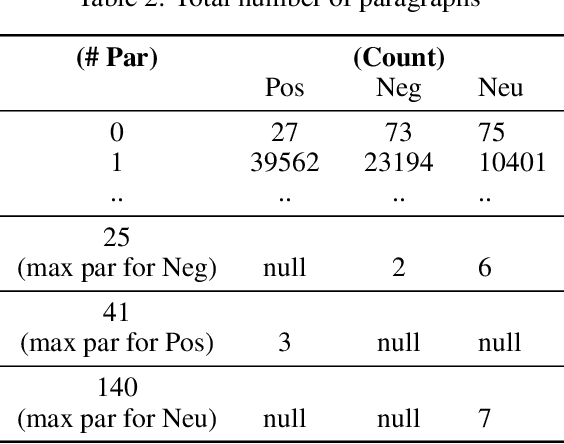
Given a patent document, identifying distinct semantic annotations is an interesting research aspect. Text annotation helps the patent practitioners such as examiners and patent attorneys to quickly identify the key arguments of any invention, successively providing a timely marking of a patent text. In the process of manual patent analysis, to attain better readability, recognising the semantic information by marking paragraphs is in practice. This semantic annotation process is laborious and time-consuming. To alleviate such a problem, we proposed a novel dataset to train Machine Learning algorithms to automate the highlighting process. The contributions of this work are: i) we developed a multi-class, novel dataset of size 150k samples by traversing USPTO patents over a decade, ii) articulated statistics and distributions of data using imperative exploratory data analysis, iii) baseline Machine Learning models are developed to utilize the dataset to address patent paragraph highlighting task, iv) dataset and codes relating to this task are open-sourced through a dedicated GIT web page: https://github.com/Renuk9390/Patent_Sentiment_Analysis and v) future path to extend this work using Deep Learning and domain specific pre-trained language models to develop a tool to highlight is provided. This work assist patent practitioners in highlighting semantic information automatically and aid to create a sustainable and efficient patent analysis using the aptitude of Machine Learning.
PatentMatch: A Dataset for Matching Patent Claims & Prior Art
Dec 27, 2020
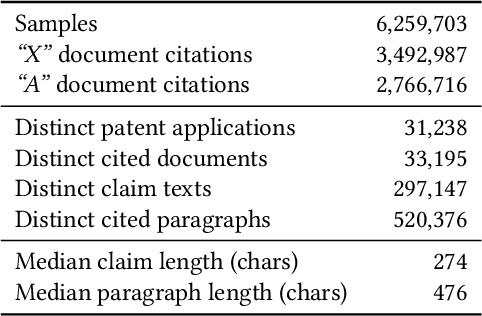
Patent examiners need to solve a complex information retrieval task when they assess the novelty and inventive step of claims made in a patent application. Given a claim, they search for prior art, which comprises all relevant publicly available information. This time-consuming task requires a deep understanding of the respective technical domain and the patent-domain-specific language. For these reasons, we address the computer-assisted search for prior art by creating a training dataset for supervised machine learning called PatentMatch. It contains pairs of claims from patent applications and semantically corresponding text passages of different degrees from cited patent documents. Each pair has been labeled by technically-skilled patent examiners from the European Patent Office. Accordingly, the label indicates the degree of semantic correspondence (matching), i.e., whether the text passage is prejudicial to the novelty of the claimed invention or not. Preliminary experiments using a baseline system show that PatentMatch can indeed be used for training a binary text pair classifier on this challenging information retrieval task. The dataset is available online: https://hpi.de/naumann/s/patentmatch.