 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatent Sentiment Analysis to Highlight Patent Paragraphs
Paper and Code

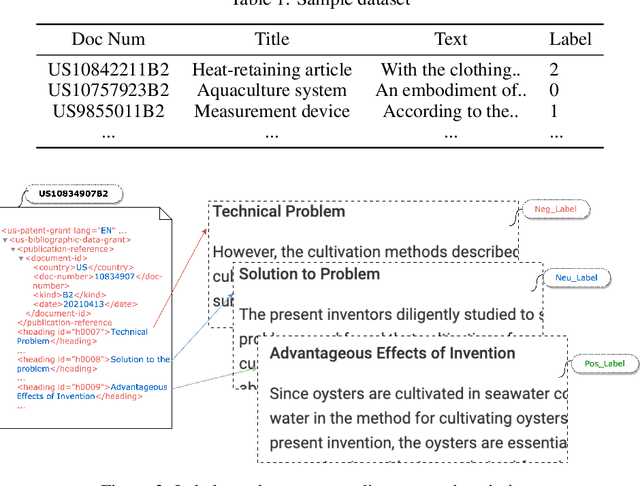
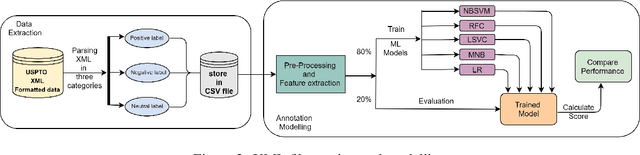
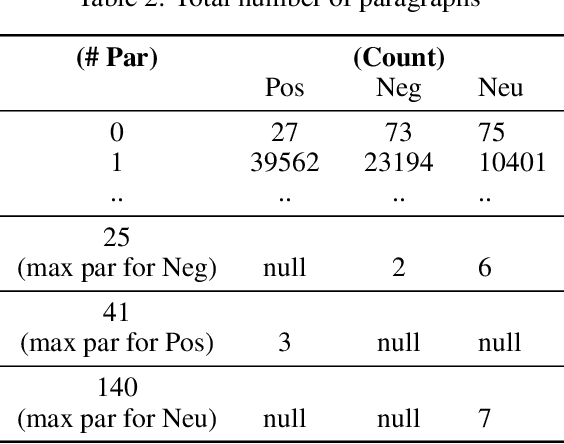
Given a patent document, identifying distinct semantic annotations is an interesting research aspect. Text annotation helps the patent practitioners such as examiners and patent attorneys to quickly identify the key arguments of any invention, successively providing a timely marking of a patent text. In the process of manual patent analysis, to attain better readability, recognising the semantic information by marking paragraphs is in practice. This semantic annotation process is laborious and time-consuming. To alleviate such a problem, we proposed a novel dataset to train Machine Learning algorithms to automate the highlighting process. The contributions of this work are: i) we developed a multi-class, novel dataset of size 150k samples by traversing USPTO patents over a decade, ii) articulated statistics and distributions of data using imperative exploratory data analysis, iii) baseline Machine Learning models are developed to utilize the dataset to address patent paragraph highlighting task, iv) dataset and codes relating to this task are open-sourced through a dedicated GIT web page: https://github.com/Renuk9390/Patent_Sentiment_Analysis and v) future path to extend this work using Deep Learning and domain specific pre-trained language models to develop a tool to highlight is provided. This work assist patent practitioners in highlighting semantic information automatically and aid to create a sustainable and efficient patent analysis using the aptitude of Machine Learning.