 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the TREC 2019 Fair Ranking Track
Paper and Code


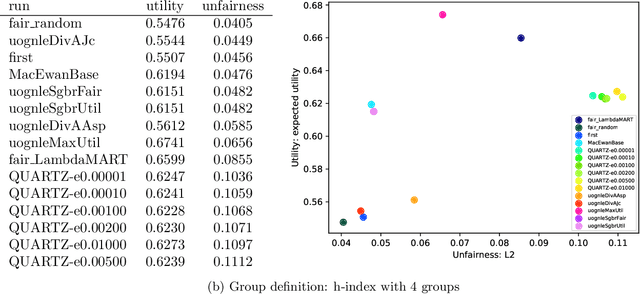
The goal of the TREC Fair Ranking track was to develop a benchmark for evaluating retrieval systems in terms of fairness to different content providers in addition to classic notions of relevance. As part of the benchmark, we defined standardized fairness metrics with evaluation protocols and released a dataset for the fair ranking problem. The 2019 task focused on reranking academic paper abstracts given a query. The objective was to fairly represent relevant authors from several groups that were unknown at the system submission time. Thus, the track emphasized the development of systems which have robust performance across a variety of group definitions. Participants were provided with querylog data (queries, documents, and relevance) from Semantic Scholar. This paper presents an overview of the track, including the task definition, descriptions of the data and the annotation process, as well as a comparison of the performance of submitted systems.