 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite
Oct 24, 2025AI agents hold the potential to revolutionize scientific productivity by automating literature reviews, replicating experiments, analyzing data, and even proposing new directions of inquiry; indeed, there are now many such agents, ranging from general-purpose "deep research" systems to specialized science-specific agents, such as AI Scientist and AIGS. Rigorous evaluation of these agents is critical for progress. Yet existing benchmarks fall short on several fronts: they (1) fail to provide holistic, product-informed measures of real-world use cases such as science research; (2) lack reproducible agent tools necessary for a controlled comparison of core agentic capabilities; (3) do not account for confounding variables such as model cost and tool access; (4) do not provide standardized interfaces for quick agent prototyping and evaluation; and (5) lack comprehensive baseline agents necessary to identify true advances. In response, we define principles and tooling for more rigorously benchmarking agents. Using these, we present AstaBench, a suite that provides the first holistic measure of agentic ability to perform scientific research, comprising 2400+ problems spanning the entire scientific discovery process and multiple scientific domains, and including many problems inspired by actual user requests to deployed Asta agents. Our suite comes with the first scientific research environment with production-grade search tools that enable controlled, reproducible evaluation, better accounting for confounders. Alongside, we provide a comprehensive suite of nine science-optimized classes of Asta agents and numerous baselines. Our extensive evaluation of 57 agents across 22 agent classes reveals several interesting findings, most importantly that despite meaningful progress on certain individual aspects, AI remains far from solving the challenge of science research assistance.
Towards Teachable Reasoning Systems
Apr 27, 2022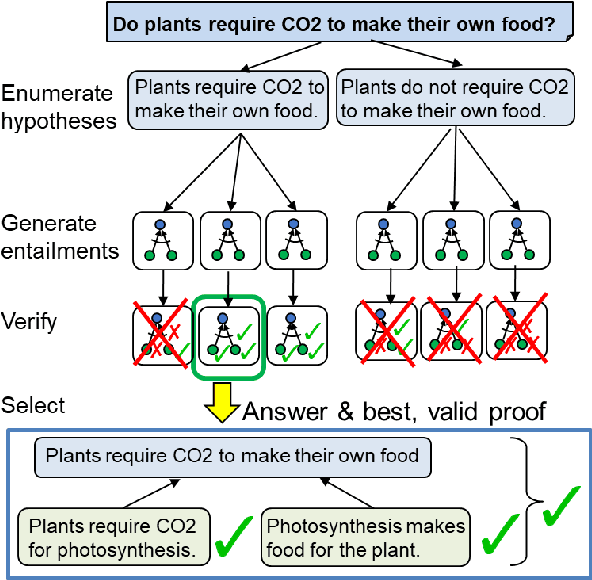

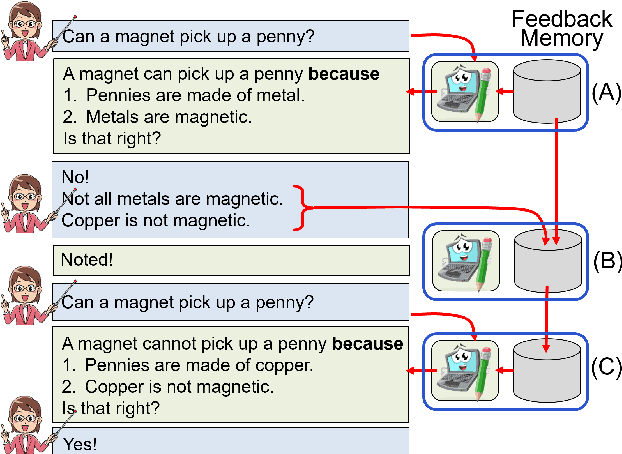
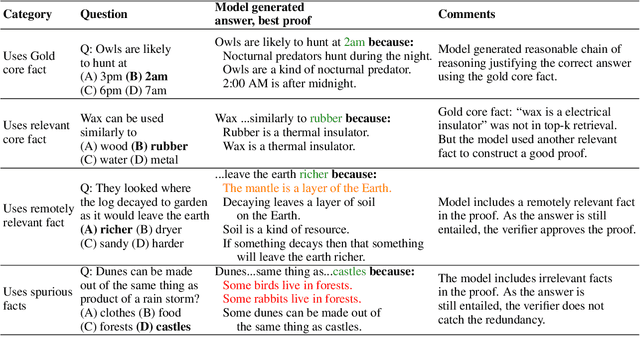
Our goal is a teachable reasoning system for question-answering (QA), where a user can interact with faithful answer explanations, and correct errors so that the system improves over time. Our approach is three-fold: First, generated chains of reasoning show how answers are implied by the system's own internal beliefs. Second, users can interact with the explanations to identify erroneous model beliefs and provide corrections. Third, we augment the model with a dynamic memory of such corrections. Retrievals from memory are used as additional context for QA, to help avoid previous mistakes in similar new situations - a novel type of memory-based continuous learning. To our knowledge, this is the first system to generate chains that are both faithful (the answer follows from the reasoning) and truthful (the chain reflects the system's own beliefs, as ascertained by self-querying). In evaluation, users judge that a majority (65%+) of generated chains clearly show how an answer follows from a set of facts - substantially better than a high-performance baseline. We also find that using simulated feedback, our system (called EntailmentWriter) continually improves with time, requiring feedback on only 25% of training examples to reach within 1% of the upper-bound (feedback on all examples). We observe a similar trend with real users. This suggests new opportunities for using language models in an interactive setting where users can inspect, debug, correct, and improve a system's performance over time.
Explaining Answers with Entailment Trees
Apr 17, 2021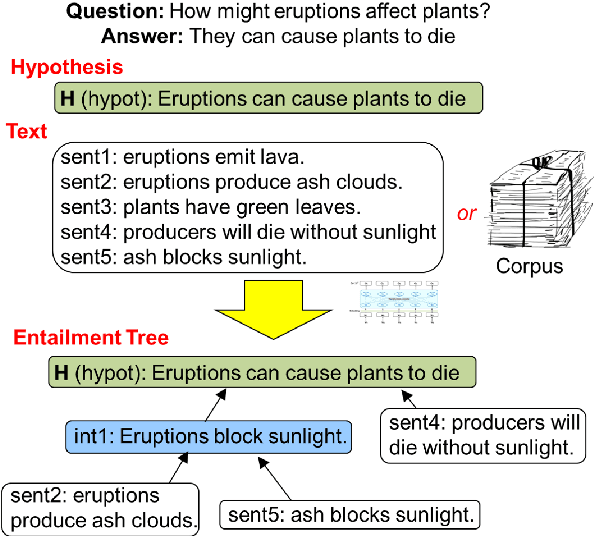

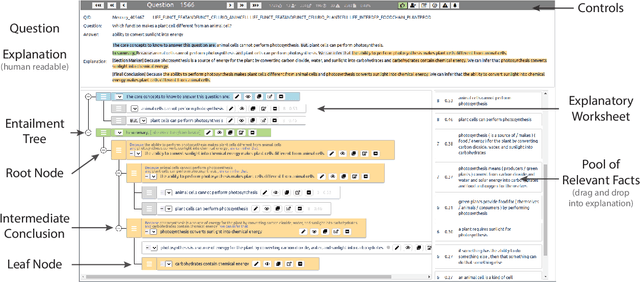

Our goal, in the context of open-domain textual question-answering (QA), is to explain answers by not just listing supporting textual evidence ("rationales"), but also showing how such evidence leads to the answer in a systematic way. If this could be done, new opportunities for understanding and debugging the system's reasoning would become possible. Our approach is to generate explanations in the form of entailment trees, namely a tree of entailment steps from facts that are known, through intermediate conclusions, to the final answer. To train a model with this skill, we created ENTAILMENTBANK, the first dataset to contain multistep entailment trees. At each node in the tree (typically) two or more facts compose together to produce a new conclusion. Given a hypothesis (question + answer), we define three increasingly difficult explanation tasks: generate a valid entailment tree given (a) all relevant sentences (the leaves of the gold entailment tree), (b) all relevant and some irrelevant sentences, or (c) a corpus. We show that a strong language model only partially solves these tasks, and identify several new directions to improve performance. This work is significant as it provides a new type of dataset (multistep entailments) and baselines, offering a new avenue for the community to generate richer, more systematic explanations.
What-if I ask you to explain: Explaining the effects of perturbations in procedural text
May 04, 2020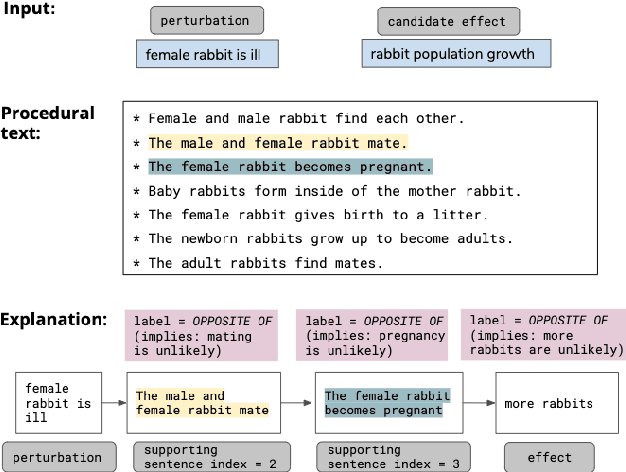
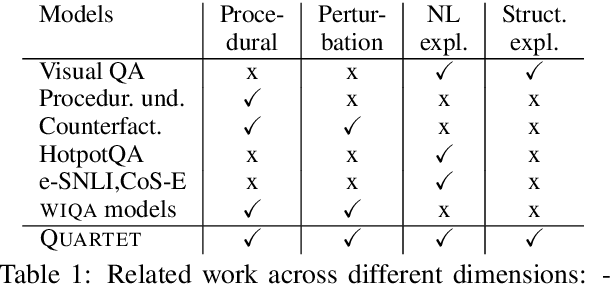

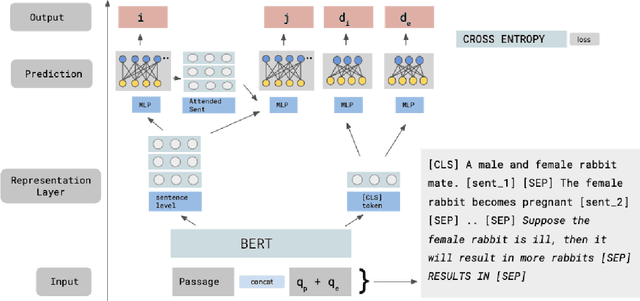
We address the task of explaining the effects of perturbations in procedural text, an important test of process comprehension. Consider a passage describing a rabbit's life-cycle: humans can easily explain the effect on the rabbit population if a female rabbit becomes ill -- i.e., the female rabbit would not become pregnant, and as a result not have babies leading to a decrease in rabbit population. We present QUARTET, a system that constructs such explanations from paragraphs, by modeling the explanation task as a multitask learning problem. QUARTET provides better explanations (based on the sentences in the procedural text) compared to several strong baselines on a recent process comprehension benchmark. We also present a surprising secondary effect: our model also achieves a new SOTA with a 7% absolute F1 improvement on a downstream QA task. This illustrates that good explanations do not have to come at the expense of end task performance.
Pretrained Language Models for Sequential Sentence Classification
Sep 22, 2019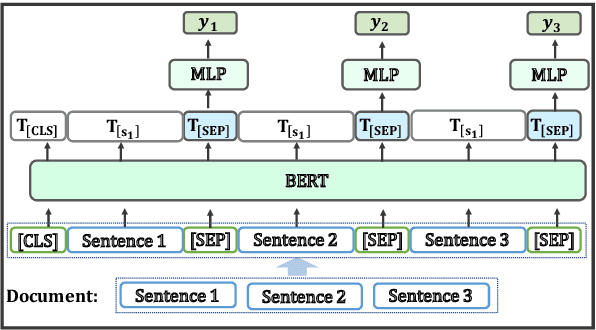

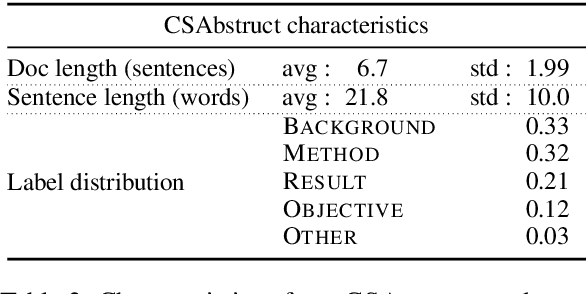
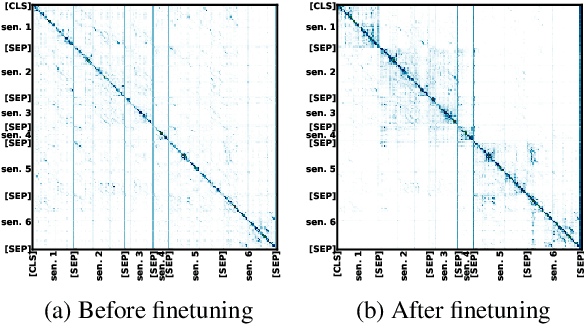
As a step toward better document-level understanding, we explore classification of a sequence of sentences into their corresponding categories, a task that requires understanding sentences in context of the document. Recent successful models for this task have used hierarchical models to contextualize sentence representations, and Conditional Random Fields (CRFs) to incorporate dependencies between subsequent labels. In this work, we show that pretrained language models, BERT (Devlin et al., 2018) in particular, can be used for this task to capture contextual dependencies without the need for hierarchical encoding nor a CRF. Specifically, we construct a joint sentence representation that allows BERT Transformer layers to directly utilize contextual information from all words in all sentences. Our approach achieves state-of-the-art results on four datasets, including a new dataset of structured scientific abstracts.
A Dataset of Peer Reviews : Collection, Insights and NLP Applications
Apr 25, 2018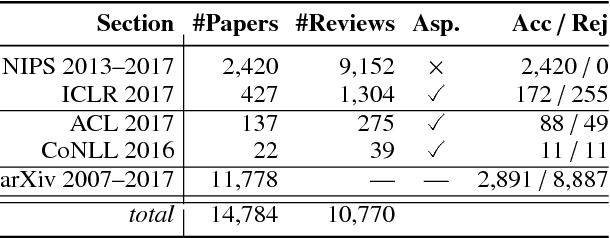
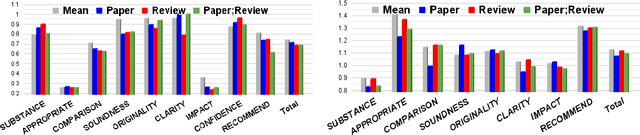
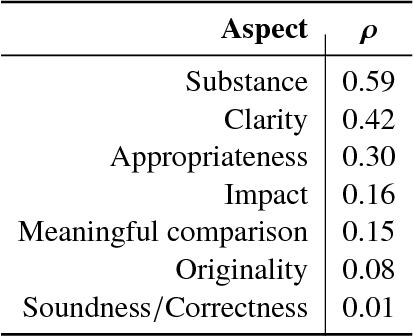
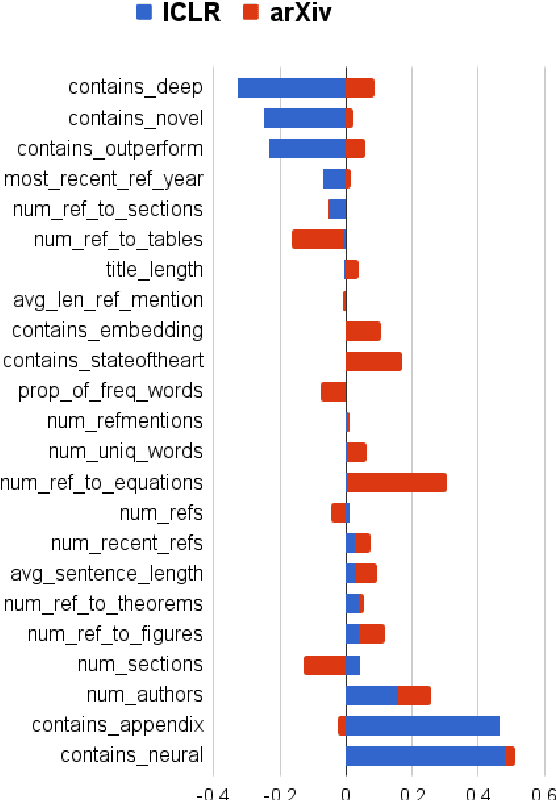
Peer reviewing is a central component in the scientific publishing process. We present the first public dataset of scientific peer reviews available for research purposes (PeerRead v1) providing an opportunity to study this important artifact. The dataset consists of 14.7K paper drafts and the corresponding accept/reject decisions in top-tier venues including ACL, NIPS and ICLR. The dataset also includes 10.7K textual peer reviews written by experts for a subset of the papers. We describe the data collection process and report interesting observed phenomena in the peer reviews. We also propose two novel NLP tasks based on this dataset and provide simple baseline models. In the first task, we show that simple models can predict whether a paper is accepted with up to 21% error reduction compared to the majority baseline. In the second task, we predict the numerical scores of review aspects and show that simple models can outperform the mean baseline for aspects with high variance such as 'originality' and 'impact'.
What Happened? Leveraging VerbNet to Predict the Effects of Actions in Procedural Text
Apr 15, 2018
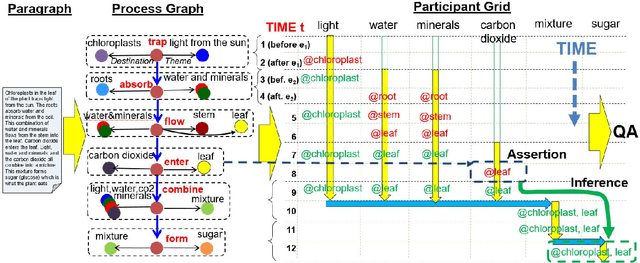
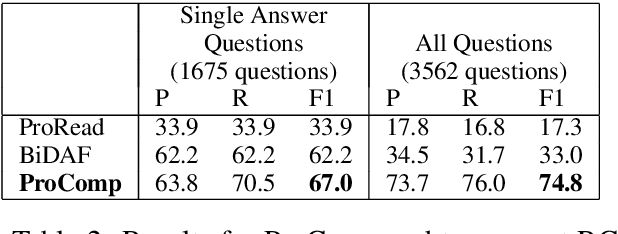
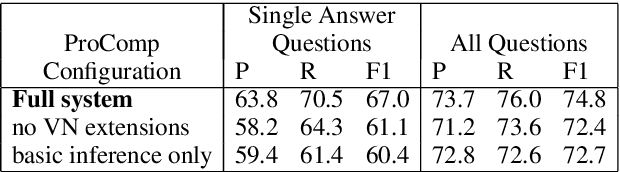
Our goal is to answer questions about paragraphs describing processes (e.g., photosynthesis). Texts of this genre are challenging because the effects of actions are often implicit (unstated), requiring background knowledge and inference to reason about the changing world states. To supply this knowledge, we leverage VerbNet to build a rulebase (called the Semantic Lexicon) of the preconditions and effects of actions, and use it along with commonsense knowledge of persistence to answer questions about change. Our evaluation shows that our system, ProComp, significantly outperforms two strong reading comprehension (RC) baselines. Our contributions are two-fold: the Semantic Lexicon rulebase itself, and a demonstration of how a simulation-based approach to machine reading can outperform RC methods that rely on surface cues alone. Since this work was performed, we have developed neural systems that outperform ProComp, described elsewhere (Dalvi et al., NAACL'18). However, the Semantic Lexicon remains a novel and potentially useful resource, and its integration with neural systems remains a currently unexplored opportunity for further improvements in machine reading about processes.
WebSets: Extracting Sets of Entities from the Web Using Unsupervised Information Extraction
Jul 01, 2013
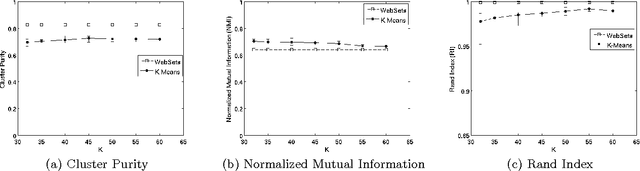
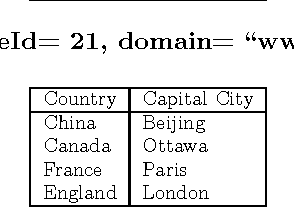

We describe a open-domain information extraction method for extracting concept-instance pairs from an HTML corpus. Most earlier approaches to this problem rely on combining clusters of distributionally similar terms and concept-instance pairs obtained with Hearst patterns. In contrast, our method relies on a novel approach for clustering terms found in HTML tables, and then assigning concept names to these clusters using Hearst patterns. The method can be efficiently applied to a large corpus, and experimental results on several datasets show that our method can accurately extract large numbers of concept-instance pairs.
Exploratory Learning
Jul 01, 2013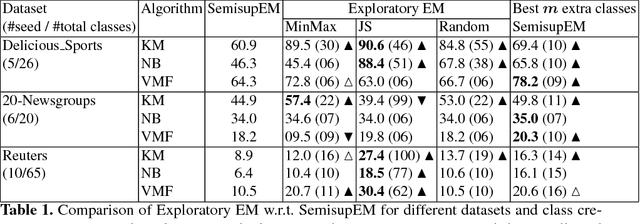
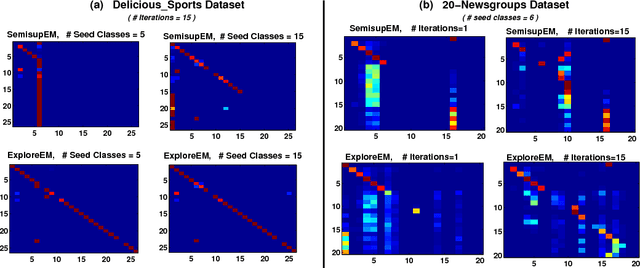
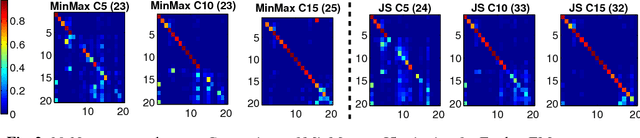

In multiclass semi-supervised learning (SSL), it is sometimes the case that the number of classes present in the data is not known, and hence no labeled examples are provided for some classes. In this paper we present variants of well-known semi-supervised multiclass learning methods that are robust when the data contains an unknown number of classes. In particular, we present an "exploratory" extension of expectation-maximization (EM) that explores different numbers of classes while learning. "Exploratory" SSL greatly improves performance on three datasets in terms of F1 on the classes with seed examples i.e., the classes which are expected to be in the data. Our Exploratory EM algorithm also outperforms a SSL method based non-parametric Bayesian clustering.