 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretrained Language Models for Sequential Sentence Classification
Paper and Code
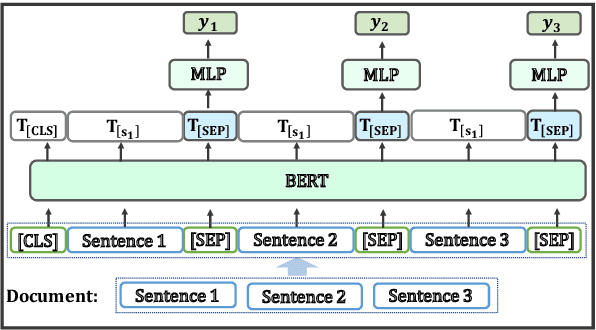

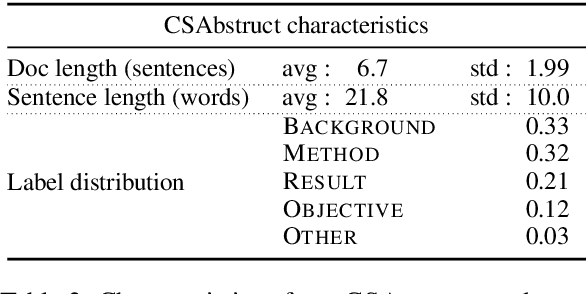
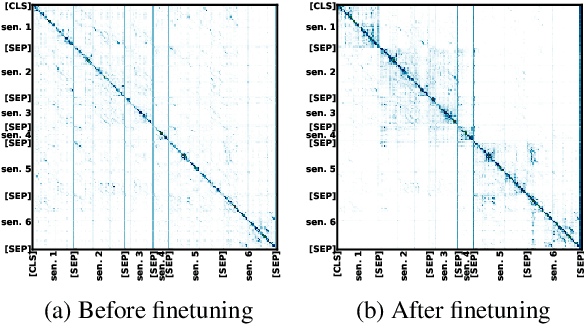
As a step toward better document-level understanding, we explore classification of a sequence of sentences into their corresponding categories, a task that requires understanding sentences in context of the document. Recent successful models for this task have used hierarchical models to contextualize sentence representations, and Conditional Random Fields (CRFs) to incorporate dependencies between subsequent labels. In this work, we show that pretrained language models, BERT (Devlin et al., 2018) in particular, can be used for this task to capture contextual dependencies without the need for hierarchical encoding nor a CRF. Specifically, we construct a joint sentence representation that allows BERT Transformer layers to directly utilize contextual information from all words in all sentences. Our approach achieves state-of-the-art results on four datasets, including a new dataset of structured scientific abstracts.