Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebSets: Extracting Sets of Entities from the Web Using Unsupervised Information Extraction
Paper and Code
Jul 01, 2013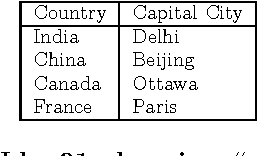
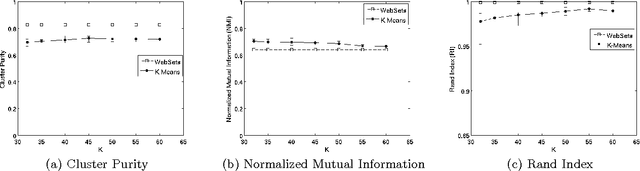
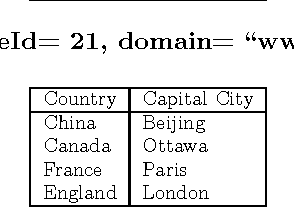

We describe a open-domain information extraction method for extracting concept-instance pairs from an HTML corpus. Most earlier approaches to this problem rely on combining clusters of distributionally similar terms and concept-instance pairs obtained with Hearst patterns. In contrast, our method relies on a novel approach for clustering terms found in HTML tables, and then assigning concept names to these clusters using Hearst patterns. The method can be efficiently applied to a large corpus, and experimental results on several datasets show that our method can accurately extract large numbers of concept-instance pairs.
* 10 pages; International Conference on Web Search and Data Mining 2012
View paper on