 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Usage and Engagement in AI-Powered Scientific Research Tools: The Asta Interaction Dataset
Feb 26, 2026AI-powered scientific research tools are rapidly being integrated into research workflows, yet the field lacks a clear lens into how researchers use these systems in real-world settings. We present and analyze the Asta Interaction Dataset, a large-scale resource comprising over 200,000 user queries and interaction logs from two deployed tools (a literature discovery interface and a scientific question-answering interface) within an LLM-powered retrieval-augmented generation platform. Using this dataset, we characterize query patterns, engagement behaviors, and how usage evolves with experience. We find that users submit longer and more complex queries than in traditional search, and treat the system as a collaborative research partner, delegating tasks such as drafting content and identifying research gaps. Users treat generated responses as persistent artifacts, revisiting and navigating among outputs and cited evidence in non-linear ways. With experience, users issue more targeted queries and engage more deeply with supporting citations, although keyword-style queries persist even among experienced users. We release the anonymized dataset and analysis with a new query intent taxonomy to inform future designs of real-world AI research assistants and to support realistic evaluation.
AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite
Oct 24, 2025AI agents hold the potential to revolutionize scientific productivity by automating literature reviews, replicating experiments, analyzing data, and even proposing new directions of inquiry; indeed, there are now many such agents, ranging from general-purpose "deep research" systems to specialized science-specific agents, such as AI Scientist and AIGS. Rigorous evaluation of these agents is critical for progress. Yet existing benchmarks fall short on several fronts: they (1) fail to provide holistic, product-informed measures of real-world use cases such as science research; (2) lack reproducible agent tools necessary for a controlled comparison of core agentic capabilities; (3) do not account for confounding variables such as model cost and tool access; (4) do not provide standardized interfaces for quick agent prototyping and evaluation; and (5) lack comprehensive baseline agents necessary to identify true advances. In response, we define principles and tooling for more rigorously benchmarking agents. Using these, we present AstaBench, a suite that provides the first holistic measure of agentic ability to perform scientific research, comprising 2400+ problems spanning the entire scientific discovery process and multiple scientific domains, and including many problems inspired by actual user requests to deployed Asta agents. Our suite comes with the first scientific research environment with production-grade search tools that enable controlled, reproducible evaluation, better accounting for confounders. Alongside, we provide a comprehensive suite of nine science-optimized classes of Asta agents and numerous baselines. Our extensive evaluation of 57 agents across 22 agent classes reveals several interesting findings, most importantly that despite meaningful progress on certain individual aspects, AI remains far from solving the challenge of science research assistance.
Do Pretrained Contextual Language Models Distinguish between Hebrew Homograph Analyses?
May 11, 2024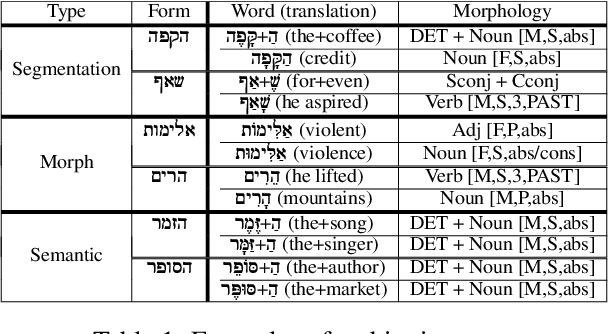
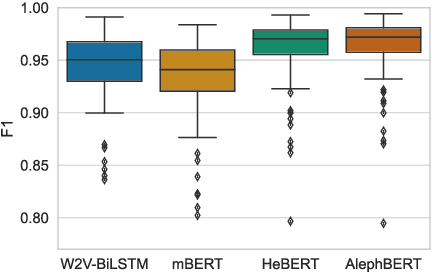
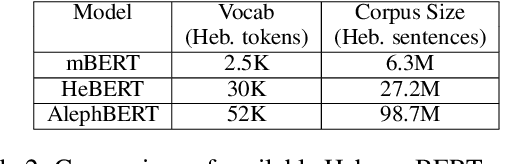
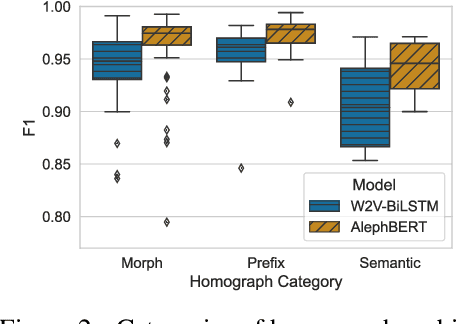
Semitic morphologically-rich languages (MRLs) are characterized by extreme word ambiguity. Because most vowels are omitted in standard texts, many of the words are homographs with multiple possible analyses, each with a different pronunciation and different morphosyntactic properties. This ambiguity goes beyond word-sense disambiguation (WSD), and may include token segmentation into multiple word units. Previous research on MRLs claimed that standardly trained pre-trained language models (PLMs) based on word-pieces may not sufficiently capture the internal structure of such tokens in order to distinguish between these analyses. Taking Hebrew as a case study, we investigate the extent to which Hebrew homographs can be disambiguated and analyzed using PLMs. We evaluate all existing models for contextualized Hebrew embeddings on a novel Hebrew homograph challenge sets that we deliver. Our empirical results demonstrate that contemporary Hebrew contextualized embeddings outperform non-contextualized embeddings; and that they are most effective for disambiguating segmentation and morphosyntactic features, less so regarding pure word-sense disambiguation. We show that these embeddings are more effective when the number of word-piece splits is limited, and they are more effective for 2-way and 3-way ambiguities than for 4-way ambiguity. We show that the embeddings are equally effective for homographs of both balanced and skewed distributions, whether calculated as masked or unmasked tokens. Finally, we show that these embeddings are as effective for homograph disambiguation with extensive supervised training as with a few-shot setup.
The Perfect Victim: Computational Analysis of Judicial Attitudes towards Victims of Sexual Violence
May 09, 2023We develop computational models to analyze court statements in order to assess judicial attitudes toward victims of sexual violence in the Israeli court system. The study examines the resonance of "rape myths" in the criminal justice system's response to sex crimes, in particular in judicial assessment of victim's credibility. We begin by formulating an ontology for evaluating judicial attitudes toward victim's credibility, with eight ordinal labels and binary categorizations. Second, we curate a manually annotated dataset for judicial assessments of victim's credibility in the Hebrew language, as well as a model that can extract credibility labels from court cases. The dataset consists of 855 verdict decision documents in sexual assault cases from 1990-2021, annotated with the help of legal experts and trained law students. The model uses a combined approach of syntactic and latent structures to find sentences that convey the judge's attitude towards the victim and classify them according to the credibility label set. Our ontology, data, and models will be made available upon request, in the hope they spur future progress in this judicial important task.
Large Pre-Trained Models with Extra-Large Vocabularies: A Contrastive Analysis of Hebrew BERT Models and a New One to Outperform Them All
Nov 28, 2022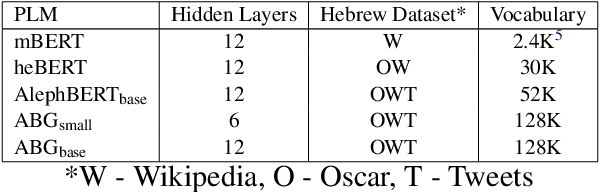
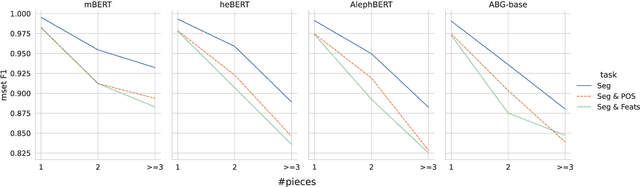

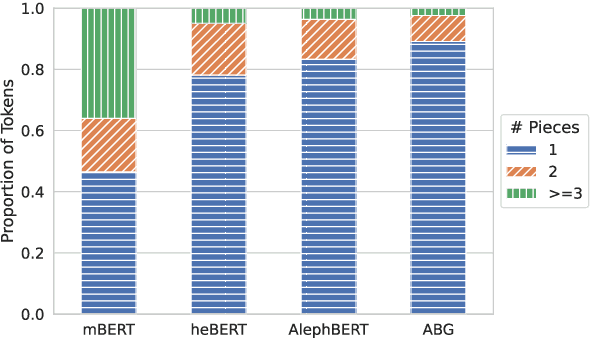
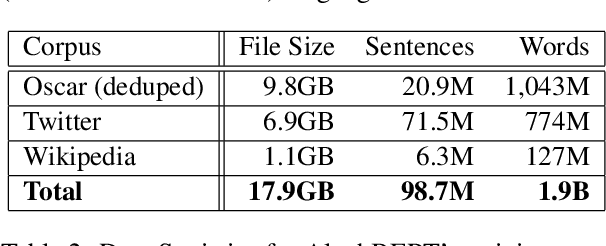
We present a new pre-trained language model (PLM) for modern Hebrew, termed AlephBERTGimmel, which employs a much larger vocabulary (128K items) than standard Hebrew PLMs before. We perform a contrastive analysis of this model against all previous Hebrew PLMs (mBERT, heBERT, AlephBERT) and assess the effects of larger vocabularies on task performance. Our experiments show that larger vocabularies lead to fewer splits, and that reducing splits is better for model performance, across different tasks. All in all this new model achieves new SOTA on all available Hebrew benchmarks, including Morphological Segmentation, POS Tagging, Full Morphological Analysis, NER, and Sentiment Analysis. Subsequently we advocate for PLMs that are larger not only in terms of number of layers or training data, but also in terms of their vocabulary. We release the new model publicly for unrestricted use.
AlephBERT:A Hebrew Large Pre-Trained Language Model to Start-off your Hebrew NLP Application With
Apr 08, 2021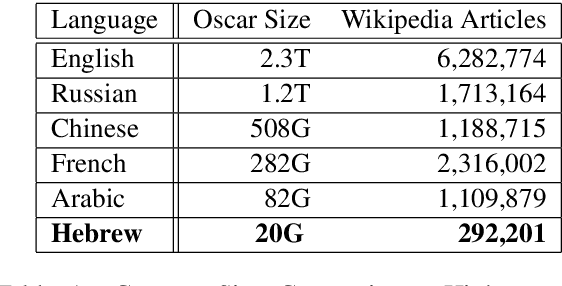

Large Pre-trained Language Models (PLMs) have become ubiquitous in the development of language understanding technology and lie at the heart of many artificial intelligence advances. While advances reported for English using PLMs are unprecedented, reported advances using PLMs in Hebrew are few and far between. The problem is twofold. First, Hebrew resources available for training NLP models are not at the same order of magnitude as their English counterparts. Second, there are no accepted tasks and benchmarks to evaluate the progress of Hebrew PLMs on. In this work we aim to remedy both aspects. First, we present AlephBERT, a large pre-trained language model for Modern Hebrew, which is trained on larger vocabulary and a larger dataset than any Hebrew PLM before. Second, using AlephBERT we present new state-of-the-art results on multiple Hebrew tasks and benchmarks, including: Segmentation, Part-of-Speech Tagging, full Morphological Tagging, Named-Entity Recognition and Sentiment Analysis. We make our AlephBERT model publicly available, providing a single point of entry for the development of Hebrew NLP applications.
Neural Modeling for Named Entities and Morphology (NEMO^2)
Jul 30, 2020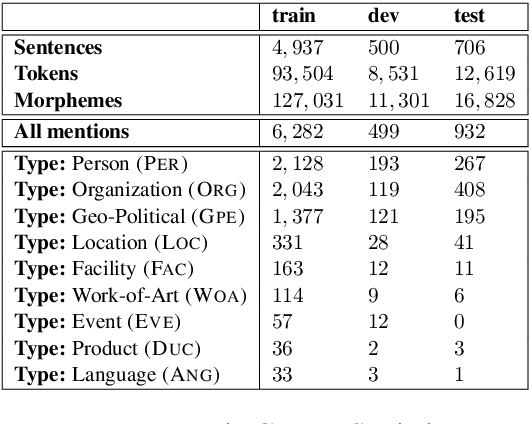
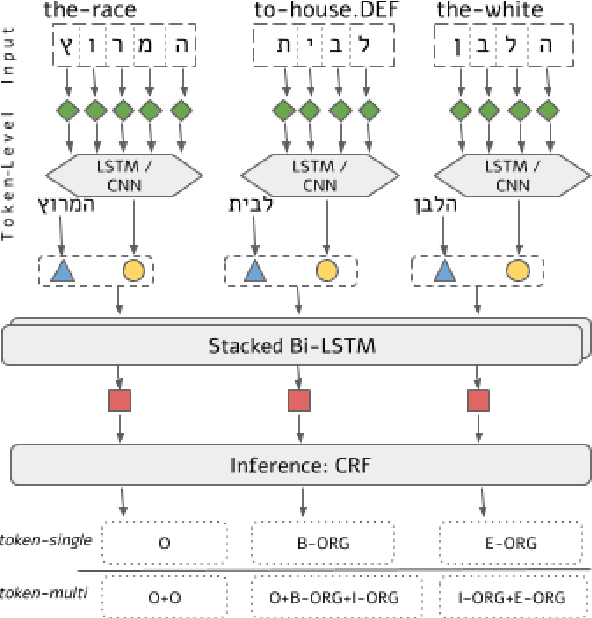
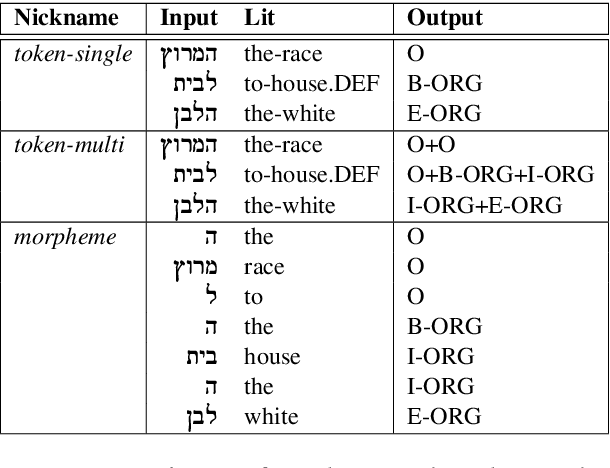

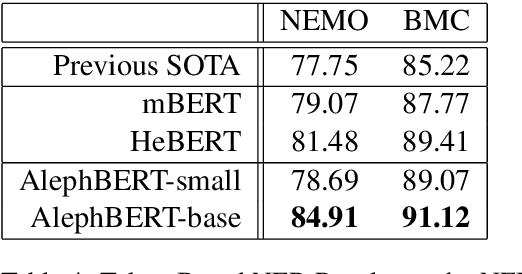
Named Entity Recognition (NER) is a fundamental NLP task, commonly formulated as classification over a sequence of tokens. Morphologically-Rich Languages (MRLs) pose a challenge to this basic formulation, as the boundaries of Named Entities do not coincide with token boundaries, rather, they respect morphological boundaries. To address NER in MRLs we then need to answer two fundamental modeling questions: (i) What should be the basic units to be identified and labeled, are they token-based or morpheme-based? and (ii) How can morphological units be encoded and accurately obtained in realistic (non-gold) scenarios? We empirically investigate these questions on a novel parallel NER benchmark we deliver, with parallel token-level and morpheme-level NER annotations for Modern Hebrew, a morphologically complex language. Our results show that explicitly modeling morphological boundaries consistently leads to improved NER performance, and that a novel hybrid architecture that we propose, in which NER precedes and prunes the morphological decomposition (MD) space, greatly outperforms the standard pipeline approach, on both Hebrew NER and Hebrew MD in realistic scenarios.
From SPMRL to NMRL: What Did We Learn in a Decade of Parsing Morphologically-Rich Languages ?
May 04, 2020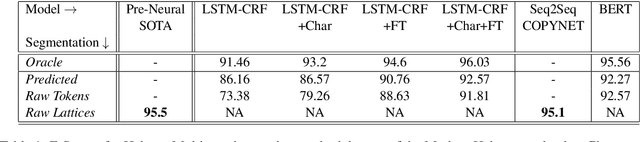
It has been exactly a decade since the first establishment of SPMRL, a research initiative unifying multiple research efforts to address the peculiar challenges of Statistical Parsing for Morphologically-Rich Languages (MRLs).Here we reflect on parsing MRLs in that decade, highlight the solutions and lessons learned for the architectural, modeling and lexical challenges in the pre-neural era, and argue that similar challenges re-emerge in neural architectures for MRLs. We then aim to offer a climax, suggesting that incorporating symbolic ideas proposed in SPMRL terms into nowadays neural architectures has the potential to push NLP for MRLs to a new level. We sketch strategies for designing Neural Models for MRLs (NMRL), and showcase preliminary support for these strategies via investigating the task of multi-tagging in Hebrew, a morphologically-rich, high-fusion, language