 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Neural Token Segmentation for High Token-Internal Complexity
Mar 21, 2022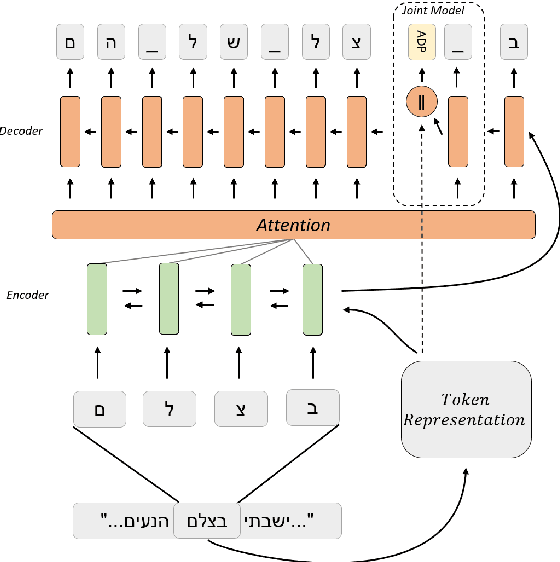
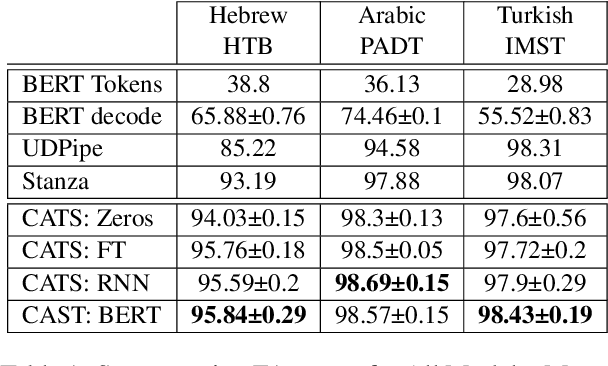
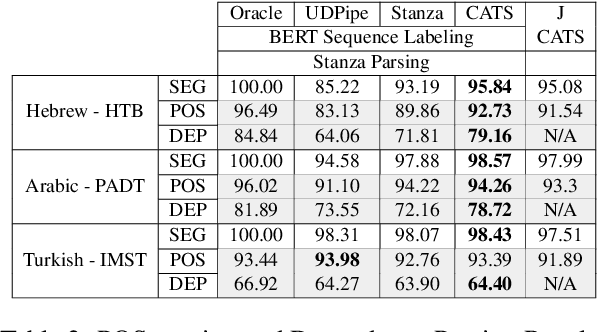
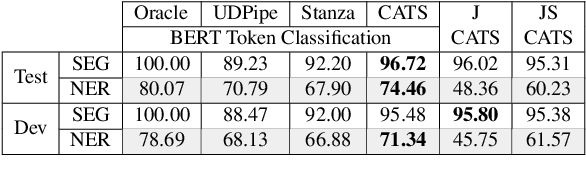
Tokenizing raw texts into word units is an essential pre-processing step for critical tasks in the NLP pipeline such as tagging, parsing, named entity recognition, and more. For most languages, this tokenization step straightforward. However, for languages with high token-internal complexity, further token-to-word segmentation is required. Previous canonical segmentation studies were based on character-level frameworks, with no contextualised representation involved. Contextualized vectors a la BERT show remarkable results in many applications, but were not shown to improve performance on linguistic segmentation per se. Here we propose a novel neural segmentation model which combines the best of both worlds, contextualised token representation and char-level decoding, which is particularly effective for languages with high token-internal complexity and extreme morphological ambiguity. Our model shows substantial improvements in segmentation accuracy on Hebrew and Arabic compared to the state-of-the-art, and leads to further improvements on downstream tasks such as Part-of-Speech Tagging, Dependency Parsing and Named-Entity Recognition, over existing pipelines. When comparing our segmentation-first pipeline with joint segmentation and labeling in the same settings, we show that, contrary to pre-neural studies, the pipeline performance is superior.
Topo2vec: Topography Embedding Using the Fractal Effect
Aug 19, 2021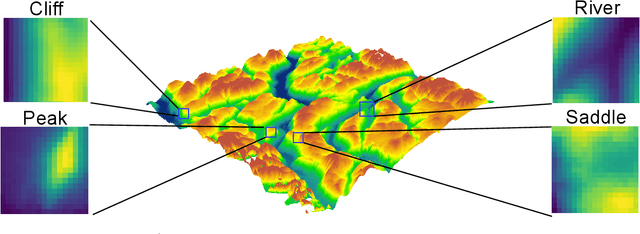

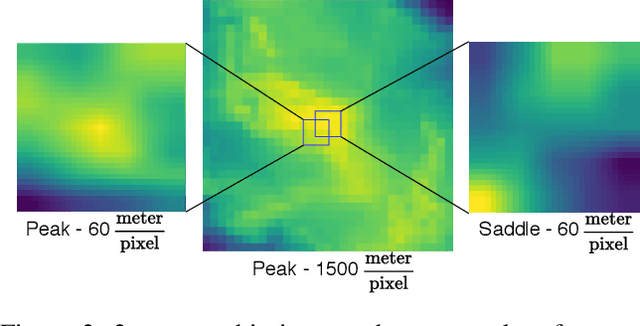
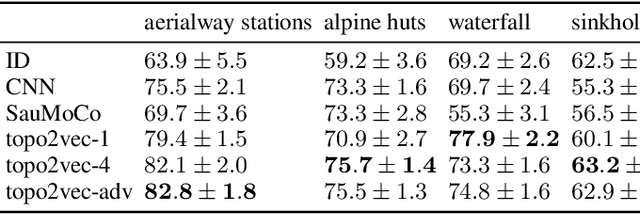
Recent advances in deep learning have transformed many fields by introducing generic embedding spaces, capable of achieving great predictive performance with minimal labeling effort. The geology field has not yet met such success. In this work, we introduce an extension for self-supervised learning techniques tailored for exploiting the fractal-effect in remote-sensing images. The fractal-effect assumes that the same structures (for example rivers, peaks and saddles) will appear in all scales. We demonstrate our method's effectiveness on elevation data, we also use the effect in inference. We perform an extensive analysis on several classification tasks and emphasize its effectiveness in detecting the same class on different scales. To the best of our knowledge, it is the first attempt to build a generic representation for topographic images.
AlephBERT:A Hebrew Large Pre-Trained Language Model to Start-off your Hebrew NLP Application With
Apr 08, 2021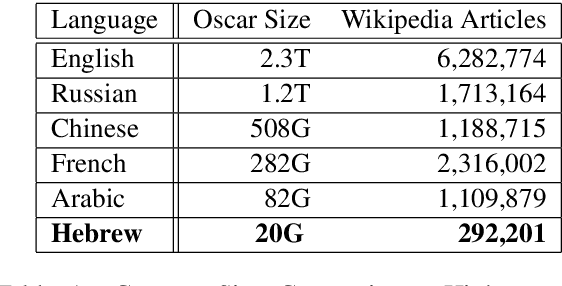
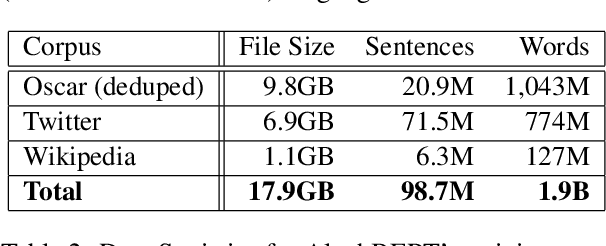

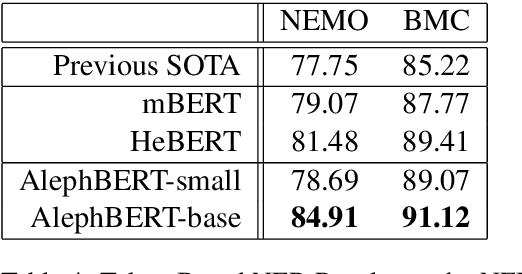
Large Pre-trained Language Models (PLMs) have become ubiquitous in the development of language understanding technology and lie at the heart of many artificial intelligence advances. While advances reported for English using PLMs are unprecedented, reported advances using PLMs in Hebrew are few and far between. The problem is twofold. First, Hebrew resources available for training NLP models are not at the same order of magnitude as their English counterparts. Second, there are no accepted tasks and benchmarks to evaluate the progress of Hebrew PLMs on. In this work we aim to remedy both aspects. First, we present AlephBERT, a large pre-trained language model for Modern Hebrew, which is trained on larger vocabulary and a larger dataset than any Hebrew PLM before. Second, using AlephBERT we present new state-of-the-art results on multiple Hebrew tasks and benchmarks, including: Segmentation, Part-of-Speech Tagging, full Morphological Tagging, Named-Entity Recognition and Sentiment Analysis. We make our AlephBERT model publicly available, providing a single point of entry for the development of Hebrew NLP applications.