 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite
Oct 24, 2025AI agents hold the potential to revolutionize scientific productivity by automating literature reviews, replicating experiments, analyzing data, and even proposing new directions of inquiry; indeed, there are now many such agents, ranging from general-purpose "deep research" systems to specialized science-specific agents, such as AI Scientist and AIGS. Rigorous evaluation of these agents is critical for progress. Yet existing benchmarks fall short on several fronts: they (1) fail to provide holistic, product-informed measures of real-world use cases such as science research; (2) lack reproducible agent tools necessary for a controlled comparison of core agentic capabilities; (3) do not account for confounding variables such as model cost and tool access; (4) do not provide standardized interfaces for quick agent prototyping and evaluation; and (5) lack comprehensive baseline agents necessary to identify true advances. In response, we define principles and tooling for more rigorously benchmarking agents. Using these, we present AstaBench, a suite that provides the first holistic measure of agentic ability to perform scientific research, comprising 2400+ problems spanning the entire scientific discovery process and multiple scientific domains, and including many problems inspired by actual user requests to deployed Asta agents. Our suite comes with the first scientific research environment with production-grade search tools that enable controlled, reproducible evaluation, better accounting for confounders. Alongside, we provide a comprehensive suite of nine science-optimized classes of Asta agents and numerous baselines. Our extensive evaluation of 57 agents across 22 agent classes reveals several interesting findings, most importantly that despite meaningful progress on certain individual aspects, AI remains far from solving the challenge of science research assistance.
ReasonIR: Training Retrievers for Reasoning Tasks
Apr 29, 2025We present ReasonIR-8B, the first retriever specifically trained for general reasoning tasks. Existing retrievers have shown limited gains on reasoning tasks, in part because existing training datasets focus on short factual queries tied to documents that straightforwardly answer them. We develop a synthetic data generation pipeline that, for each document, our pipeline creates a challenging and relevant query, along with a plausibly related but ultimately unhelpful hard negative. By training on a mixture of our synthetic data and existing public data, ReasonIR-8B achieves a new state-of-the-art of 29.9 nDCG@10 without reranker and 36.9 nDCG@10 with reranker on BRIGHT, a widely-used reasoning-intensive information retrieval (IR) benchmark. When applied to RAG tasks, ReasonIR-8B improves MMLU and GPQA performance by 6.4% and 22.6% respectively, relative to the closed-book baseline, outperforming other retrievers and search engines. In addition, ReasonIR-8B uses test-time compute more effectively: on BRIGHT, its performance consistently increases with longer and more information-rich rewritten queries; it continues to outperform other retrievers when combined with an LLM reranker. Our training recipe is general and can be easily extended to future LLMs; to this end, we open-source our code, data, and model.
Diffusion Guided Language Modeling
Aug 08, 2024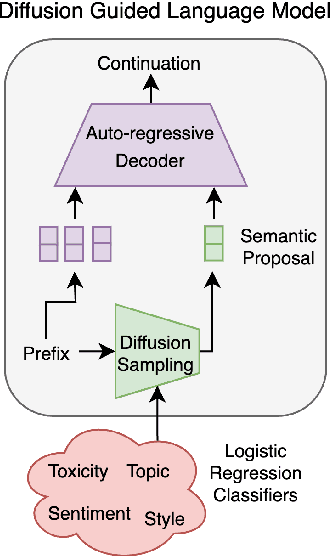



Current language models demonstrate remarkable proficiency in text generation. However, for many applications it is desirable to control attributes, such as sentiment, or toxicity, of the generated language -- ideally tailored towards each specific use case and target audience. For auto-regressive language models, existing guidance methods are prone to decoding errors that cascade during generation and degrade performance. In contrast, text diffusion models can easily be guided with, for example, a simple linear sentiment classifier -- however they do suffer from significantly higher perplexity than auto-regressive alternatives. In this paper we use a guided diffusion model to produce a latent proposal that steers an auto-regressive language model to generate text with desired properties. Our model inherits the unmatched fluency of the auto-regressive approach and the plug-and-play flexibility of diffusion. We show that it outperforms previous plug-and-play guidance methods across a wide range of benchmark data sets. Further, controlling a new attribute in our framework is reduced to training a single logistic regression classifier.
Correction with Backtracking Reduces Hallucination in Summarization
Oct 31, 2023
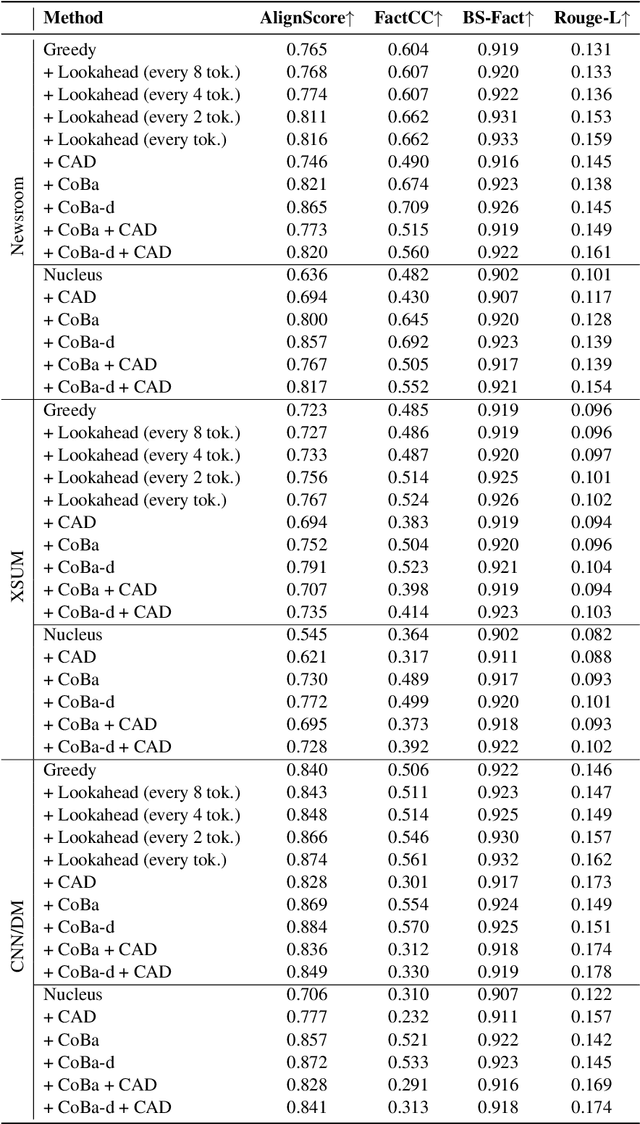


Abstractive summarization aims at generating natural language summaries of a source document that are succinct while preserving the important elements. Despite recent advances, neural text summarization models are known to be susceptible to hallucinating (or more correctly confabulating), that is to produce summaries with details that are not grounded in the source document. In this paper, we introduce a simple yet efficient technique, CoBa, to reduce hallucination in abstractive summarization. The approach is based on two steps: hallucination detection and mitigation. We show that the former can be achieved through measuring simple statistics about conditional word probabilities and distance to context words. Further, we demonstrate that straight-forward backtracking is surprisingly effective at mitigation. We thoroughly evaluate the proposed method with prior art on three benchmark datasets for text summarization. The results show that CoBa is effective and efficient in reducing hallucination, and offers great adaptability and flexibility.
IncDSI: Incrementally Updatable Document Retrieval
Jul 19, 2023Differentiable Search Index is a recently proposed paradigm for document retrieval, that encodes information about a corpus of documents within the parameters of a neural network and directly maps queries to corresponding documents. These models have achieved state-of-the-art performances for document retrieval across many benchmarks. These kinds of models have a significant limitation: it is not easy to add new documents after a model is trained. We propose IncDSI, a method to add documents in real time (about 20-50ms per document), without retraining the model on the entire dataset (or even parts thereof). Instead we formulate the addition of documents as a constrained optimization problem that makes minimal changes to the network parameters. Although orders of magnitude faster, our approach is competitive with re-training the model on the whole dataset and enables the development of document retrieval systems that can be updated with new information in real-time. Our code for IncDSI is available at https://github.com/varshakishore/IncDSI.
Learning Iterative Neural Optimizers for Image Steganography
Mar 27, 2023



Image steganography is the process of concealing secret information in images through imperceptible changes. Recent work has formulated this task as a classic constrained optimization problem. In this paper, we argue that image steganography is inherently performed on the (elusive) manifold of natural images, and propose an iterative neural network trained to perform the optimization steps. In contrast to classical optimization methods like L-BFGS or projected gradient descent, we train the neural network to also stay close to the manifold of natural images throughout the optimization. We show that our learned neural optimization is faster and more reliable than classical optimization approaches. In comparison to previous state-of-the-art encoder-decoder-based steganography methods, it reduces the recovery error rate by multiple orders of magnitude and achieves zero error up to 3 bits per pixel (bpp) without the need for error-correcting codes.
Latent Diffusion for Language Generation
Dec 19, 2022



Diffusion models have achieved great success in modeling continuous data modalities such as images, audio, and video, but have seen limited use in discrete domains such as language. Recent attempts to adapt diffusion to language have presented diffusion as an alternative to autoregressive language generation. We instead view diffusion as a complementary method that can augment the generative capabilities of existing pre-trained language models. We demonstrate that continuous diffusion models can be learned in the latent space of a pre-trained encoder-decoder model, enabling us to sample continuous latent representations that can be decoded into natural language with the pre-trained decoder. We show that our latent diffusion models are more effective at sampling novel text from data distributions than a strong autoregressive baseline and also enable controllable generation.
BERTScore: Evaluating Text Generation with BERT
Apr 21, 2019


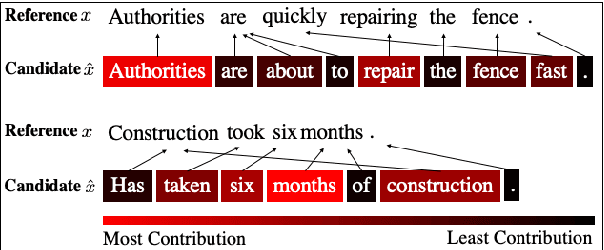
We propose BERTScore, an automatic evaluation metric for text generation. Analogous to common metrics, \method computes a similarity score for each token in the candidate sentence with each token in the reference. However, instead of looking for exact matches, we compute similarity using contextualized BERT embeddings. We evaluate on several machine translation and image captioning benchmarks, and show that BERTScore correlates better with human judgments than existing metrics, often significantly outperforming even task-specific supervised metrics.