 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multislice Electron Ptychography with a Generative Prior
Jul 23, 2025Multislice electron ptychography (MEP) is an inverse imaging technique that computationally reconstructs the highest-resolution images of atomic crystal structures from diffraction patterns. Available algorithms often solve this inverse problem iteratively but are both time consuming and produce suboptimal solutions due to their ill-posed nature. We develop MEP-Diffusion, a diffusion model trained on a large database of crystal structures specifically for MEP to augment existing iterative solvers. MEP-Diffusion is easily integrated as a generative prior into existing reconstruction methods via Diffusion Posterior Sampling (DPS). We find that this hybrid approach greatly enhances the quality of the reconstructed 3D volumes, achieving a 90.50% improvement in SSIM over existing methods.
Pre-training Large Memory Language Models with Internal and External Knowledge
May 21, 2025Neural language models are black-boxes -- both linguistic patterns and factual knowledge are distributed across billions of opaque parameters. This entangled encoding makes it difficult to reliably inspect, verify, or update specific facts. We propose a new class of language models, Large Memory Language Models (LMLM) with a pre-training recipe that stores factual knowledge in both internal weights and an external database. Our approach strategically masks externally retrieved factual values from the training loss, thereby teaching the model to perform targeted lookups rather than relying on memorization in model weights. Our experiments demonstrate that LMLMs achieve competitive performance compared to significantly larger, knowledge-dense LLMs on standard benchmarks, while offering the advantages of explicit, editable, and verifiable knowledge bases. This work represents a fundamental shift in how language models interact with and manage factual knowledge.
Sample-Efficient Diffusion for Text-To-Speech Synthesis
Sep 01, 2024



This work introduces Sample-Efficient Speech Diffusion (SESD), an algorithm for effective speech synthesis in modest data regimes through latent diffusion. It is based on a novel diffusion architecture, that we call U-Audio Transformer (U-AT), that efficiently scales to long sequences and operates in the latent space of a pre-trained audio autoencoder. Conditioned on character-aware language model representations, SESD achieves impressive results despite training on less than 1k hours of speech - far less than current state-of-the-art systems. In fact, it synthesizes more intelligible speech than the state-of-the-art auto-regressive model, VALL-E, while using less than 2% the training data.
Diffusion Guided Language Modeling
Aug 08, 2024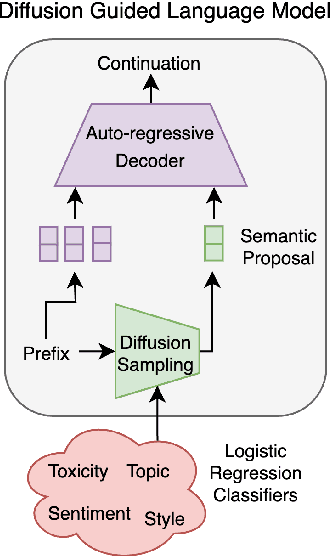



Current language models demonstrate remarkable proficiency in text generation. However, for many applications it is desirable to control attributes, such as sentiment, or toxicity, of the generated language -- ideally tailored towards each specific use case and target audience. For auto-regressive language models, existing guidance methods are prone to decoding errors that cascade during generation and degrade performance. In contrast, text diffusion models can easily be guided with, for example, a simple linear sentiment classifier -- however they do suffer from significantly higher perplexity than auto-regressive alternatives. In this paper we use a guided diffusion model to produce a latent proposal that steers an auto-regressive language model to generate text with desired properties. Our model inherits the unmatched fluency of the auto-regressive approach and the plug-and-play flexibility of diffusion. We show that it outperforms previous plug-and-play guidance methods across a wide range of benchmark data sets. Further, controlling a new attribute in our framework is reduced to training a single logistic regression classifier.
IncDSI: Incrementally Updatable Document Retrieval
Jul 19, 2023Differentiable Search Index is a recently proposed paradigm for document retrieval, that encodes information about a corpus of documents within the parameters of a neural network and directly maps queries to corresponding documents. These models have achieved state-of-the-art performances for document retrieval across many benchmarks. These kinds of models have a significant limitation: it is not easy to add new documents after a model is trained. We propose IncDSI, a method to add documents in real time (about 20-50ms per document), without retraining the model on the entire dataset (or even parts thereof). Instead we formulate the addition of documents as a constrained optimization problem that makes minimal changes to the network parameters. Although orders of magnitude faster, our approach is competitive with re-training the model on the whole dataset and enables the development of document retrieval systems that can be updated with new information in real-time. Our code for IncDSI is available at https://github.com/varshakishore/IncDSI.
Latent Diffusion for Language Generation
Dec 19, 2022



Diffusion models have achieved great success in modeling continuous data modalities such as images, audio, and video, but have seen limited use in discrete domains such as language. Recent attempts to adapt diffusion to language have presented diffusion as an alternative to autoregressive language generation. We instead view diffusion as a complementary method that can augment the generative capabilities of existing pre-trained language models. We demonstrate that continuous diffusion models can be learned in the latent space of a pre-trained encoder-decoder model, enabling us to sample continuous latent representations that can be decoded into natural language with the pre-trained decoder. We show that our latent diffusion models are more effective at sampling novel text from data distributions than a strong autoregressive baseline and also enable controllable generation.
Robust Knowledge Graph Completion with Stacked Convolutions and a Student Re-Ranking Network
Jun 11, 2021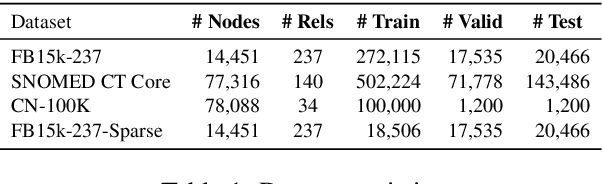
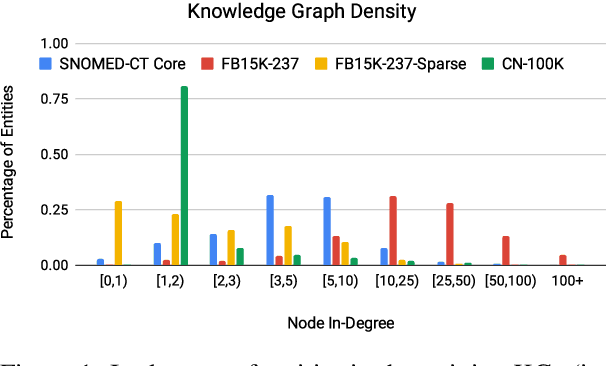
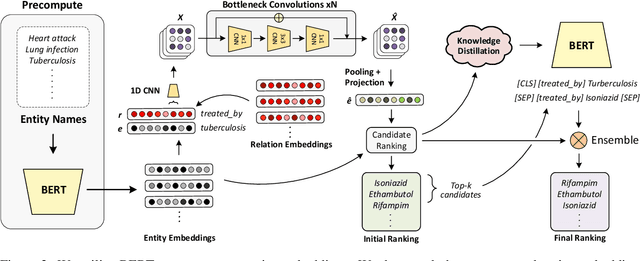

Knowledge Graph (KG) completion research usually focuses on densely connected benchmark datasets that are not representative of real KGs. We curate two KG datasets that include biomedical and encyclopedic knowledge and use an existing commonsense KG dataset to explore KG completion in the more realistic setting where dense connectivity is not guaranteed. We develop a deep convolutional network that utilizes textual entity representations and demonstrate that our model outperforms recent KG completion methods in this challenging setting. We find that our model's performance improvements stem primarily from its robustness to sparsity. We then distill the knowledge from the convolutional network into a student network that re-ranks promising candidate entities. This re-ranking stage leads to further improvements in performance and demonstrates the effectiveness of entity re-ranking for KG completion.
Dynamically Extracting Outcome-Specific Problem Lists from Clinical Notes with Guided Multi-Headed Attention
Jul 25, 2020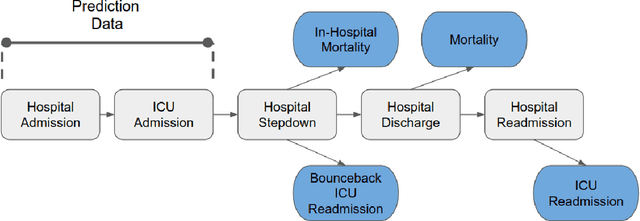
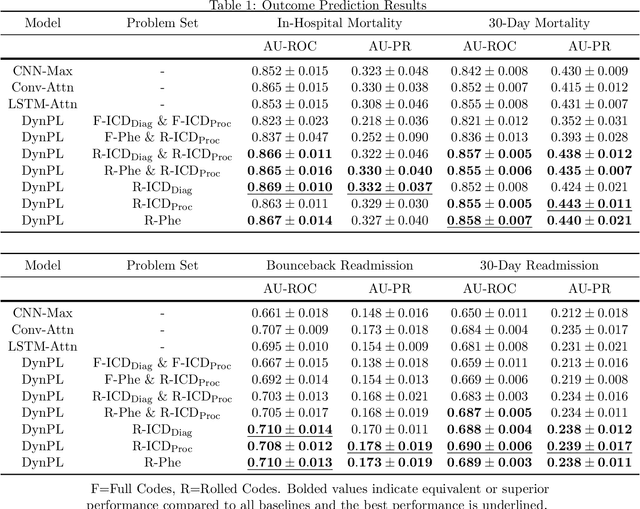


Problem lists are intended to provide clinicians with a relevant summary of patient medical issues and are embedded in many electronic health record systems. Despite their importance, problem lists are often cluttered with resolved or currently irrelevant conditions. In this work, we develop a novel end-to-end framework that first extracts diagnosis and procedure information from clinical notes and subsequently uses the extracted medical problems to predict patient outcomes. This framework is both more performant and more interpretable than existing models used within the domain, achieving an AU-ROC of 0.710 for bounceback readmission and 0.869 for in-hospital mortality occurring after ICU discharge. We identify risk factors for both readmission and mortality outcomes and demonstrate that our framework can be used to develop dynamic problem lists that present clinical problems along with their quantitative importance. We conduct a qualitative user study with medical experts and demonstrate that they view the lists produced by our framework favorably and find them to be a more effective clinical decision support tool than a strong baseline.