 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamically Extracting Outcome-Specific Problem Lists from Clinical Notes with Guided Multi-Headed Attention
Jul 25, 2020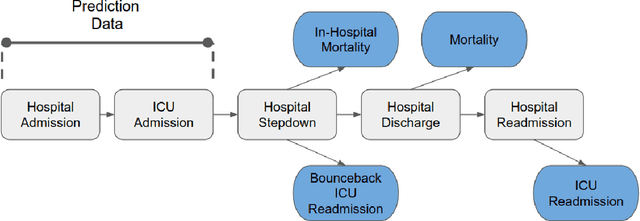
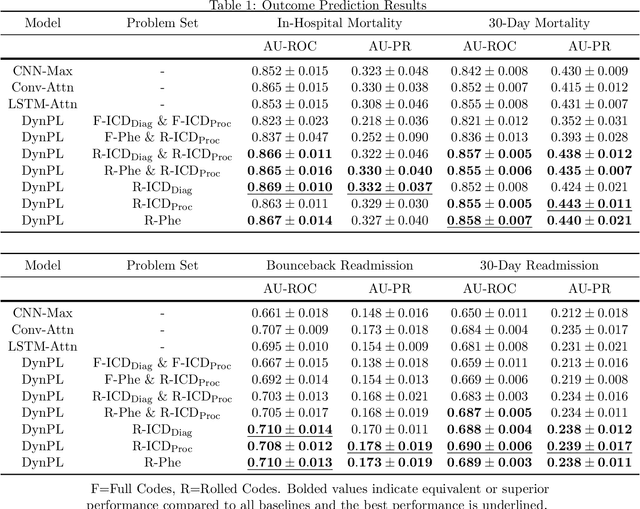


Problem lists are intended to provide clinicians with a relevant summary of patient medical issues and are embedded in many electronic health record systems. Despite their importance, problem lists are often cluttered with resolved or currently irrelevant conditions. In this work, we develop a novel end-to-end framework that first extracts diagnosis and procedure information from clinical notes and subsequently uses the extracted medical problems to predict patient outcomes. This framework is both more performant and more interpretable than existing models used within the domain, achieving an AU-ROC of 0.710 for bounceback readmission and 0.869 for in-hospital mortality occurring after ICU discharge. We identify risk factors for both readmission and mortality outcomes and demonstrate that our framework can be used to develop dynamic problem lists that present clinical problems along with their quantitative importance. We conduct a qualitative user study with medical experts and demonstrate that they view the lists produced by our framework favorably and find them to be a more effective clinical decision support tool than a strong baseline.
Explainable Prediction of Adverse Outcomes Using Clinical Notes
Nov 12, 2019



Clinical notes contain a large amount of clinically valuable information that is ignored in many clinical decision support systems due to the difficulty that comes with mining that information. Recent work has found success leveraging deep learning models for the prediction of clinical outcomes using clinical notes. However, these models fail to provide clinically relevant and interpretable information that clinicians can utilize for informed clinical care. In this work, we augment a popular convolutional model with an attention mechanism and apply it to unstructured clinical notes for the prediction of ICU readmission and mortality. We find that the addition of the attention mechanism leads to competitive performance while allowing for the straightforward interpretation of predictions. We develop clear visualizations to present important spans of text for both individual predictions and high-risk cohorts. We then conduct a qualitative analysis and demonstrate that our model is consistently attending to clinically meaningful portions of the narrative for all of the outcomes that we explore.
Visualization of Emergency Department Clinical Data for Interpretable Patient Phenotyping
Jul 05, 2019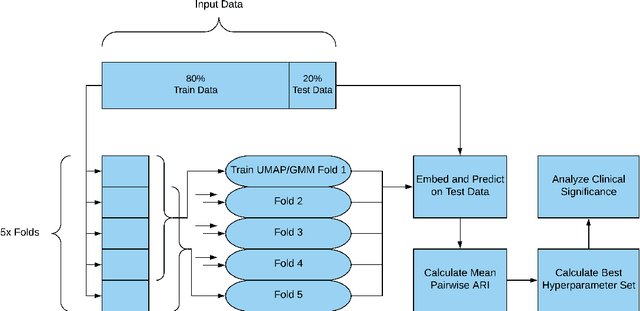
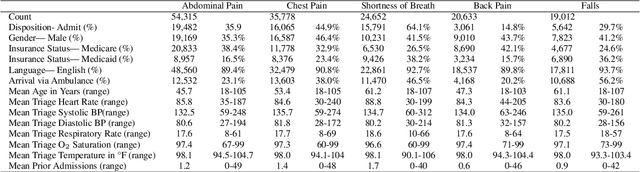


Visual summarization of clinical data collected on patients contained within the electronic health record (EHR) may enable precise and rapid triage at the time of patient presentation to an emergency department (ED). The triage process is critical in the appropriate allocation of resources and in anticipating eventual patient disposition, typically admission to the hospital or discharge home. EHR data are high-dimensional and complex, but offer the opportunity to discover and characterize underlying data-driven patient phenotypes. These phenotypes will enable improved, personalized therapeutic decision making and prognostication. In this work, we focus on the challenge of two-dimensional patient projections. A low dimensional embedding offers visual interpretability lost in higher dimensions. While linear dimensionality reduction techniques such as principal component analysis are often used towards this aim, they are insufficient to describe the variance of patient data. In this work, we employ the newly-described non-linear embedding technique called uniform manifold approximation and projection (UMAP). UMAP seeks to capture both local and global structures in high-dimensional data. We then use Gaussian mixture models to identify clusters in the embedded data and use the adjusted Rand index (ARI) to establish stability in the discovery of these clusters. This technique is applied to five common clinical chief complaints from a real-world ED EHR dataset, describing the emergent properties of discovered clusters. We observe clinically-relevant cluster attributes, suggesting that visual embeddings of EHR data using non-linear dimensionality reduction is a promising approach to reveal data-driven patient phenotypes. In the five chief complaints, we find between 2 and 6 clusters, with the peak mean pairwise ARI between subsequent training iterations to range from 0.35 to 0.74.