 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Backpropagation: The LM Head is a Gradient Bottleneck
Mar 10, 2026The last layer of neural language models (LMs) projects output features of dimension $D$ to logits in dimension $V$, the size of the vocabulary, where usually $D \ll V$. This mismatch is known to raise risks of limited expressivity in neural LMs, creating a so-called softmax bottleneck. We show the softmax bottleneck is not only an expressivity bottleneck but also an optimization bottleneck. Backpropagating $V$-dimensional gradients through a rank-$D$ linear layer induces unavoidable compression, which alters the training feedback provided to the vast majority of the parameters. We present a theoretical analysis of this phenomenon and measure empirically that 95-99% of the gradient norm is suppressed by the output layer, resulting in vastly suboptimal update directions. We conduct controlled pretraining experiments showing that the gradient bottleneck makes trivial patterns unlearnable, and drastically affects the training dynamics of LLMs. We argue that this inherent flaw contributes to training inefficiencies at scale independently of the model architecture, and raises the need for new LM head designs.
Simple Context Compression: Mean-Pooling and Multi-Ratio Training
Oct 23, 2025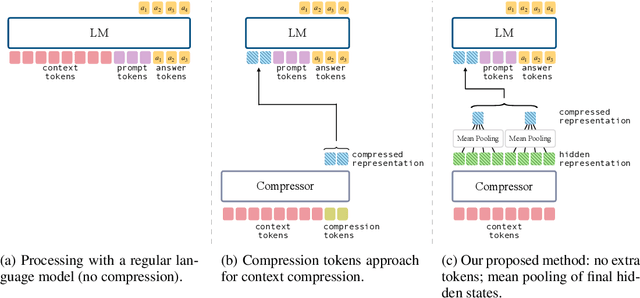
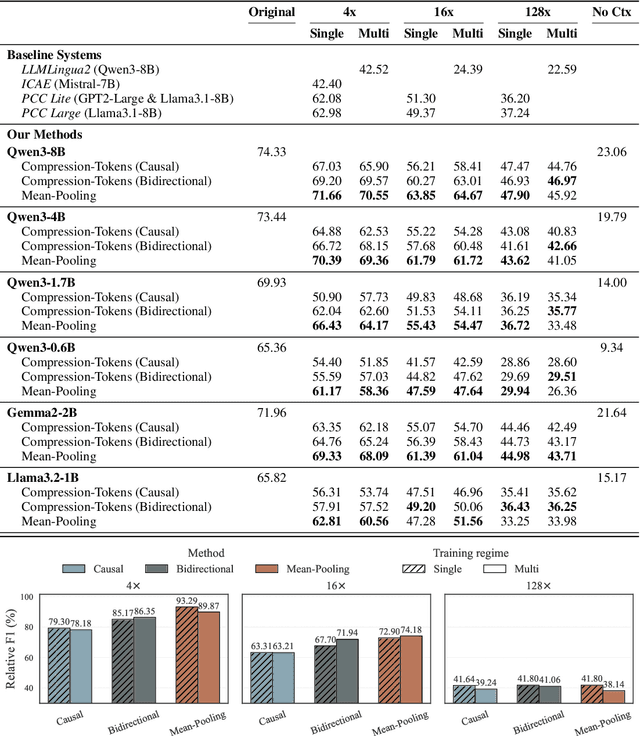
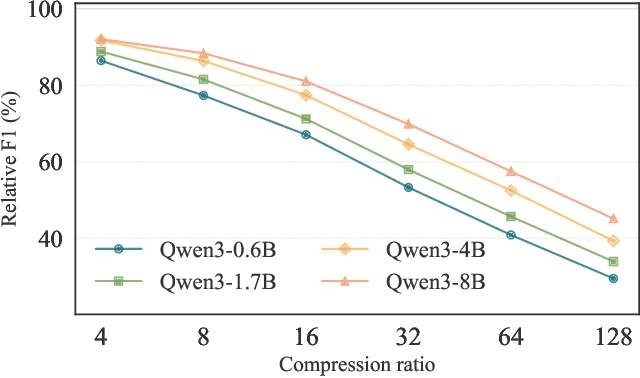
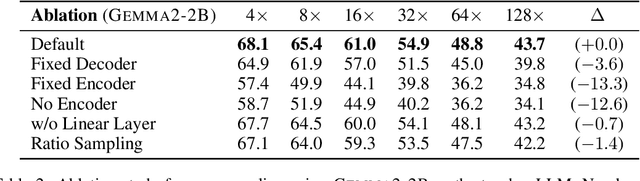
A common strategy to reduce the computational costs of using long contexts in retrieval-augmented generation (RAG) with large language models (LLMs) is soft context compression, where the input sequence is transformed into a shorter continuous representation. We develop a lightweight and simple mean-pooling approach that consistently outperforms the widely used compression-tokens architecture, and study training the same compressor to output multiple compression ratios. We conduct extensive experiments across in-domain and out-of-domain QA datasets, as well as across model families, scales, and compression ratios. Overall, our simple mean-pooling approach achieves the strongest performance, with a relatively small drop when training for multiple compression ratios. More broadly though, across architectures and training regimes the trade-offs are more nuanced, illustrating the complex landscape of compression methods.
Post-training for Efficient Communication via Convention Formation
Aug 08, 2025Humans communicate with increasing efficiency in multi-turn interactions, by adapting their language and forming ad-hoc conventions. In contrast, prior work shows that LLMs do not naturally show this behavior. We develop a post-training process to develop this ability through targeted fine-tuning on heuristically identified demonstrations of convention formation. We evaluate with two new benchmarks focused on this capability. First, we design a focused, cognitively-motivated interaction benchmark that consistently elicits strong convention formation trends in humans. Second, we create a new document-grounded reference completion task that reflects in-the-wild convention formation behavior. Our studies show significantly improved convention formation abilities in post-trained LLMs across the two evaluation methods.
Knot So Simple: A Minimalistic Environment for Spatial Reasoning
May 23, 2025We propose KnotGym, an interactive environment for complex, spatial reasoning and manipulation. KnotGym includes goal-oriented rope manipulation tasks with varying levels of complexity, all requiring acting from pure image observations. Tasks are defined along a clear and quantifiable axis of complexity based on the number of knot crossings, creating a natural generalization test. KnotGym has a simple observation space, allowing for scalable development, yet it highlights core challenges in integrating acute perception, spatial reasoning, and grounded manipulation. We evaluate methods of different classes, including model-based RL, model-predictive control, and chain-of-thought reasoning, and illustrate the challenges KnotGym presents. KnotGym is available at https://github.com/lil-lab/knotgym.
Pre-training Large Memory Language Models with Internal and External Knowledge
May 21, 2025Neural language models are black-boxes -- both linguistic patterns and factual knowledge are distributed across billions of opaque parameters. This entangled encoding makes it difficult to reliably inspect, verify, or update specific facts. We propose a new class of language models, Large Memory Language Models (LMLM) with a pre-training recipe that stores factual knowledge in both internal weights and an external database. Our approach strategically masks externally retrieved factual values from the training loss, thereby teaching the model to perform targeted lookups rather than relying on memorization in model weights. Our experiments demonstrate that LMLMs achieve competitive performance compared to significantly larger, knowledge-dense LLMs on standard benchmarks, while offering the advantages of explicit, editable, and verifiable knowledge bases. This work represents a fundamental shift in how language models interact with and manage factual knowledge.
Cancer Type, Stage and Prognosis Assessment from Pathology Reports using LLMs
Mar 03, 2025Large Language Models (LLMs) have shown significant promise across various natural language processing tasks. However, their application in the field of pathology, particularly for extracting meaningful insights from unstructured medical texts such as pathology reports, remains underexplored and not well quantified. In this project, we leverage state-of-the-art language models, including the GPT family, Mistral models, and the open-source Llama models, to evaluate their performance in comprehensively analyzing pathology reports. Specifically, we assess their performance in cancer type identification, AJCC stage determination, and prognosis assessment, encompassing both information extraction and higher-order reasoning tasks. Based on a detailed analysis of their performance metrics in a zero-shot setting, we developed two instruction-tuned models: Path-llama3.1-8B and Path-GPT-4o-mini-FT. These models demonstrated superior performance in zero-shot cancer type identification, staging, and prognosis assessment compared to the other models evaluated.
Imitation Learning from a Single Temporally Misaligned Video
Feb 08, 2025



We examine the problem of learning sequential tasks from a single visual demonstration. A key challenge arises when demonstrations are temporally misaligned due to variations in timing, differences in embodiment, or inconsistencies in execution. Existing approaches treat imitation as a distribution-matching problem, aligning individual frames between the agent and the demonstration. However, we show that such frame-level matching fails to enforce temporal ordering or ensure consistent progress. Our key insight is that matching should instead be defined at the level of sequences. We propose that perfect matching occurs when one sequence successfully covers all the subgoals in the same order as the other sequence. We present ORCA (ORdered Coverage Alignment), a dense per-timestep reward function that measures the probability of the agent covering demonstration frames in the correct order. On temporally misaligned demonstrations, we show that agents trained with the ORCA reward achieve $4.5$x improvement ($0.11 \rightarrow 0.50$ average normalized returns) for Meta-world tasks and $6.6$x improvement ($6.55 \rightarrow 43.3$ average returns) for Humanoid-v4 tasks compared to the best frame-level matching algorithms. We also provide empirical analysis showing that ORCA is robust to varying levels of temporal misalignment. Our code is available at https://github.com/portal-cornell/orca/
Retrospective Learning from Interactions
Oct 17, 2024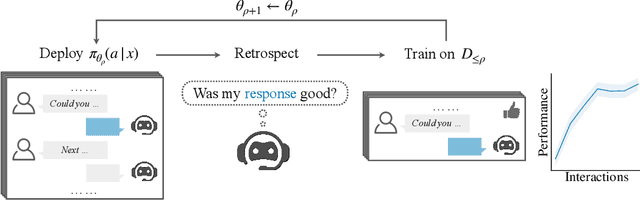


Multi-turn interactions between large language models (LLMs) and users naturally include implicit feedback signals. If an LLM responds in an unexpected way to an instruction, the user is likely to signal it by rephrasing the request, expressing frustration, or pivoting to an alternative task. Such signals are task-independent and occupy a relatively constrained subspace of language, allowing the LLM to identify them even if it fails on the actual task. This creates an avenue for continually learning from interactions without additional annotations. We introduce ReSpect, a method to learn from such signals in past interactions via retrospection. We deploy ReSpect in a new multimodal interaction scenario, where humans instruct an LLM to solve an abstract reasoning task with a combinatorial solution space. Through thousands of interactions with humans, we show how ReSpect gradually improves task completion rate from 31% to 82%, all without any external annotation.
LLMs Are In-Context Reinforcement Learners
Oct 07, 2024



Large Language Models (LLMs) can learn new tasks through in-context supervised learning (i.e., ICL). This work studies if this ability extends to in-context reinforcement learning (ICRL), where models are not given gold labels in context, but only their past predictions and rewards. We show that a naive application of ICRL fails miserably, and identify the root cause as a fundamental deficiency at exploration, which leads to quick model degeneration. We propose an algorithm to address this deficiency by increasing test-time compute, as well as a compute-bound approximation. We use several challenging classification tasks to empirically show that our ICRL algorithms lead to effective learning from rewards alone, and analyze the characteristics of this ability and our methods. Overall, our results reveal remarkable ICRL abilities in LLMs.
CoGen: Learning from Feedback with Coupled Comprehension and Generation
Aug 28, 2024Systems with both language comprehension and generation capabilities can benefit from the tight connection between the two. This work studies coupling comprehension and generation with focus on continually learning from interaction with users. We propose techniques to tightly integrate the two capabilities for both learning and inference. We situate our studies in two-player reference games, and deploy various models for thousands of interactions with human users, while learning from interaction feedback signals. We show dramatic improvements in performance over time, with comprehension-generation coupling leading to performance improvements up to 26% in absolute terms and up to 17% higher accuracies compared to a non-coupled system. Our analysis also shows coupling has substantial qualitative impact on the system's language, making it significantly more human-like.