 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Diffusion for Language Generation
Dec 19, 2022



Diffusion models have achieved great success in modeling continuous data modalities such as images, audio, and video, but have seen limited use in discrete domains such as language. Recent attempts to adapt diffusion to language have presented diffusion as an alternative to autoregressive language generation. We instead view diffusion as a complementary method that can augment the generative capabilities of existing pre-trained language models. We demonstrate that continuous diffusion models can be learned in the latent space of a pre-trained encoder-decoder model, enabling us to sample continuous latent representations that can be decoded into natural language with the pre-trained decoder. We show that our latent diffusion models are more effective at sampling novel text from data distributions than a strong autoregressive baseline and also enable controllable generation.
Understanding Decoupled and Early Weight Decay
Dec 27, 2020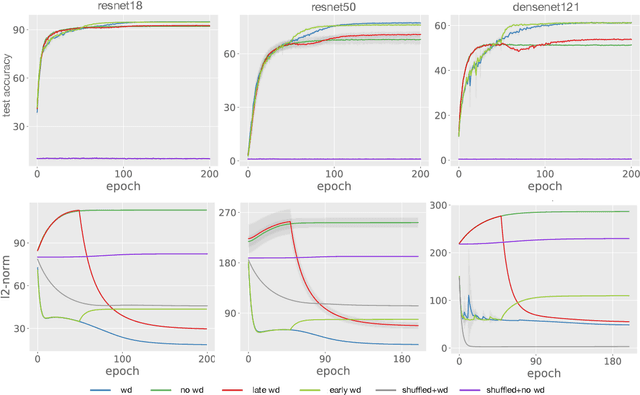
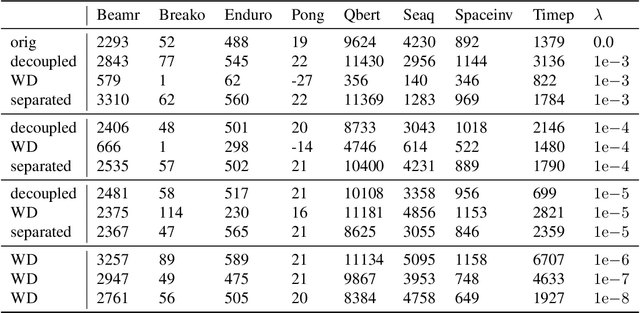
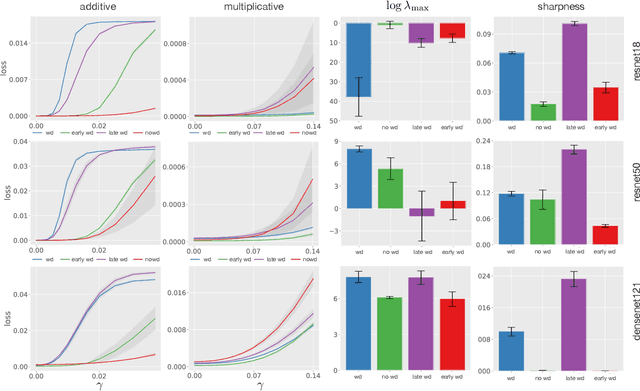
Weight decay (WD) is a traditional regularization technique in deep learning, but despite its ubiquity, its behavior is still an area of active research. Golatkar et al. have recently shown that WD only matters at the start of the training in computer vision, upending traditional wisdom. Loshchilov et al. show that for adaptive optimizers, manually decaying weights can outperform adding an $l_2$ penalty to the loss. This technique has become increasingly popular and is referred to as decoupled WD. The goal of this paper is to investigate these two recent empirical observations. We demonstrate that by applying WD only at the start, the network norm stays small throughout training. This has a regularizing effect as the effective gradient updates become larger. However, traditional generalizations metrics fail to capture this effect of WD, and we show how a simple scale-invariant metric can. We also show how the growth of network weights is heavily influenced by the dataset and its generalization properties. For decoupled WD, we perform experiments in NLP and RL where adaptive optimizers are the norm. We demonstrate that the primary issue that decoupled WD alleviates is the mixing of gradients from the objective function and the $l_2$ penalty in the buffers of Adam (which stores the estimates of the first-order moment). Adaptivity itself is not problematic and decoupled WD ensures that the gradients from the $l_2$ term cannot "drown out" the true objective, facilitating easier hyperparameter tuning.
Adversarial Deep Averaging Networks for Cross-Lingual Sentiment Classification
Aug 18, 2018In recent years great success has been achieved in sentiment classification for English, thanks in part to the availability of copious annotated resources. Unfortunately, most languages do not enjoy such an abundance of labeled data. To tackle the sentiment classification problem in low-resource languages without adequate annotated data, we propose an Adversarial Deep Averaging Network (ADAN) to transfer the knowledge learned from labeled data on a resource-rich source language to low-resource languages where only unlabeled data exists. ADAN has two discriminative branches: a sentiment classifier and an adversarial language discriminator. Both branches take input from a shared feature extractor to learn hidden representations that are simultaneously indicative for the classification task and invariant across languages. Experiments on Chinese and Arabic sentiment classification demonstrate that ADAN significantly outperforms state-of-the-art systems.
An empirical study on evaluation metrics of generative adversarial networks
Aug 17, 2018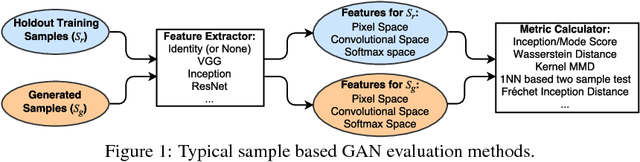

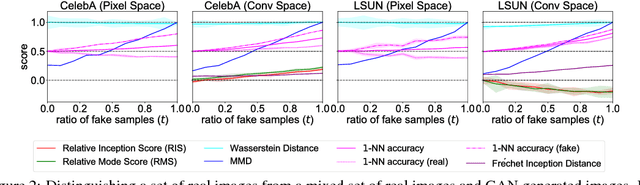
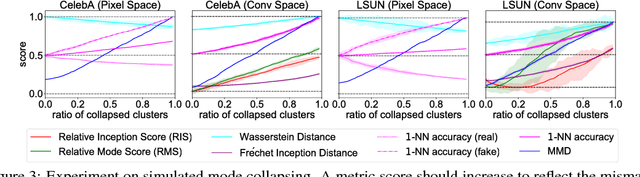
Evaluating generative adversarial networks (GANs) is inherently challenging. In this paper, we revisit several representative sample-based evaluation metrics for GANs, and address the problem of how to evaluate the evaluation metrics. We start with a few necessary conditions for metrics to produce meaningful scores, such as distinguishing real from generated samples, identifying mode dropping and mode collapsing, and detecting overfitting. With a series of carefully designed experiments, we comprehensively investigate existing sample-based metrics and identify their strengths and limitations in practical settings. Based on these results, we observe that kernel Maximum Mean Discrepancy (MMD) and the 1-Nearest-Neighbor (1-NN) two-sample test seem to satisfy most of the desirable properties, provided that the distances between samples are computed in a suitable feature space. Our experiments also unveil interesting properties about the behavior of several popular GAN models, such as whether they are memorizing training samples, and how far they are from learning the target distribution.
Fast Reading Comprehension with ConvNets
Nov 12, 2017
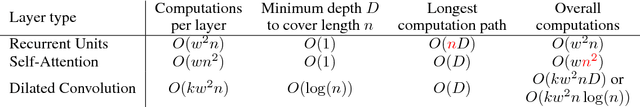

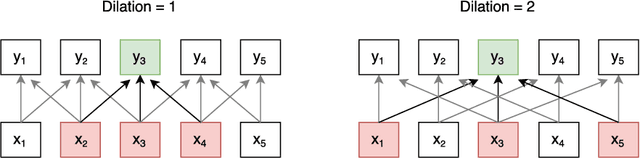
State-of-the-art deep reading comprehension models are dominated by recurrent neural nets. Their sequential nature is a natural fit for language, but it also precludes parallelization within an instances and often becomes the bottleneck for deploying such models to latency critical scenarios. This is particularly problematic for longer texts. Here we present a convolutional architecture as an alternative to these recurrent architectures. Using simple dilated convolutional units in place of recurrent ones, we achieve results comparable to the state of the art on two question answering tasks, while at the same time achieving up to two orders of magnitude speedups for question answering.
Deep Feature Interpolation for Image Content Changes
Jun 19, 2017
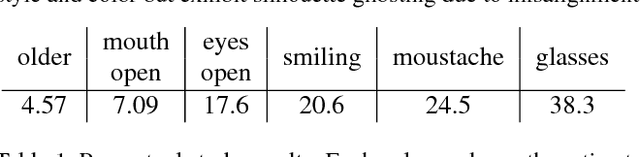

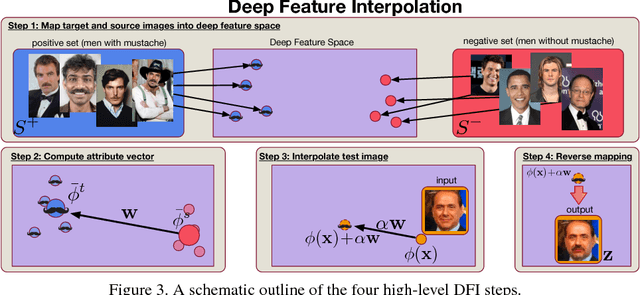
We propose Deep Feature Interpolation (DFI), a new data-driven baseline for automatic high-resolution image transformation. As the name suggests, it relies only on simple linear interpolation of deep convolutional features from pre-trained convnets. We show that despite its simplicity, DFI can perform high-level semantic transformations like "make older/younger", "make bespectacled", "add smile", among others, surprisingly well - sometimes even matching or outperforming the state-of-the-art. This is particularly unexpected as DFI requires no specialized network architecture or even any deep network to be trained for these tasks. DFI therefore can be used as a new baseline to evaluate more complex algorithms and provides a practical answer to the question of which image transformation tasks are still challenging in the rise of deep learning.
Deep Networks with Stochastic Depth
Jul 28, 2016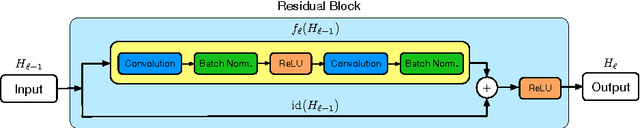
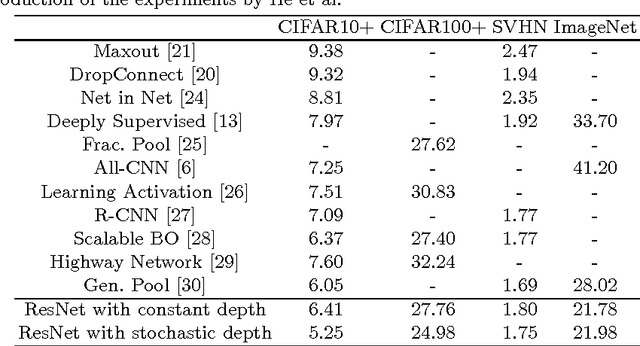
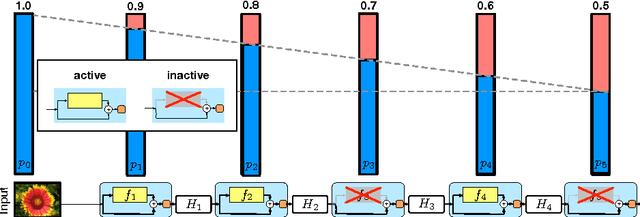
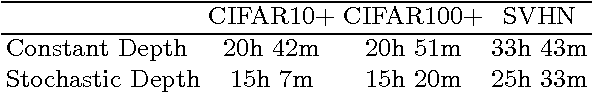
Very deep convolutional networks with hundreds of layers have led to significant reductions in error on competitive benchmarks. Although the unmatched expressiveness of the many layers can be highly desirable at test time, training very deep networks comes with its own set of challenges. The gradients can vanish, the forward flow often diminishes, and the training time can be painfully slow. To address these problems, we propose stochastic depth, a training procedure that enables the seemingly contradictory setup to train short networks and use deep networks at test time. We start with very deep networks but during training, for each mini-batch, randomly drop a subset of layers and bypass them with the identity function. This simple approach complements the recent success of residual networks. It reduces training time substantially and improves the test error significantly on almost all data sets that we used for evaluation. With stochastic depth we can increase the depth of residual networks even beyond 1200 layers and still yield meaningful improvements in test error (4.91% on CIFAR-10).
Marginalizing Corrupted Features
Feb 27, 2014
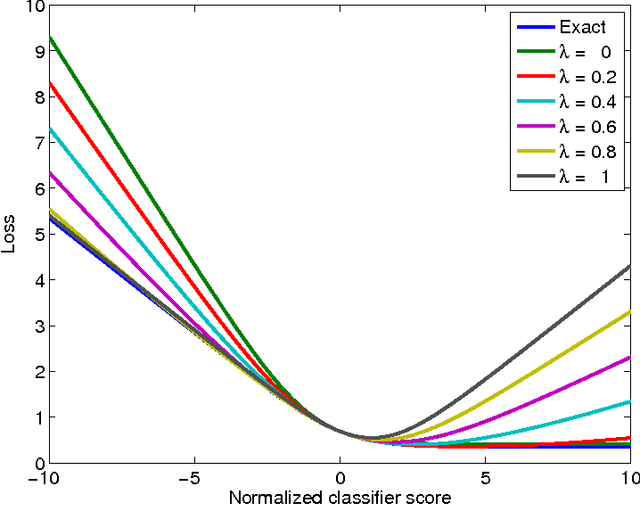
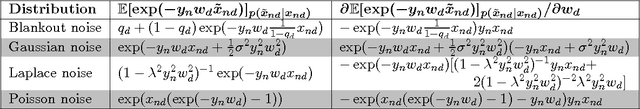
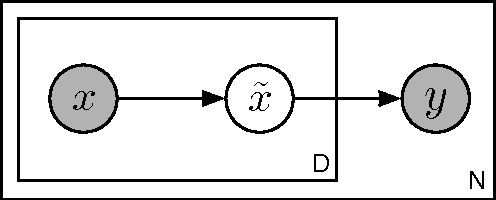
The goal of machine learning is to develop predictors that generalize well to test data. Ideally, this is achieved by training on an almost infinitely large training data set that captures all variations in the data distribution. In practical learning settings, however, we do not have infinite data and our predictors may overfit. Overfitting may be combatted, for example, by adding a regularizer to the training objective or by defining a prior over the model parameters and performing Bayesian inference. In this paper, we propose a third, alternative approach to combat overfitting: we extend the training set with infinitely many artificial training examples that are obtained by corrupting the original training data. We show that this approach is practical and efficient for a range of predictors and corruption models. Our approach, called marginalized corrupted features (MCF), trains robust predictors by minimizing the expected value of the loss function under the corruption model. We show empirically on a variety of data sets that MCF classifiers can be trained efficiently, may generalize substantially better to test data, and are also more robust to feature deletion at test time.
The Greedy Miser: Learning under Test-time Budgets
Jun 27, 2012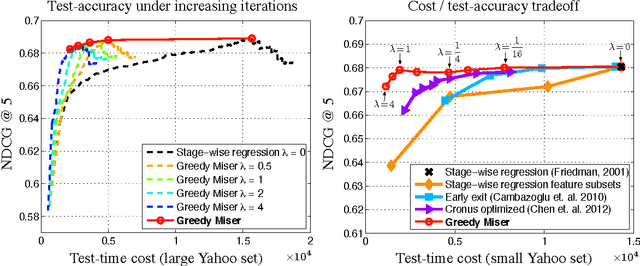
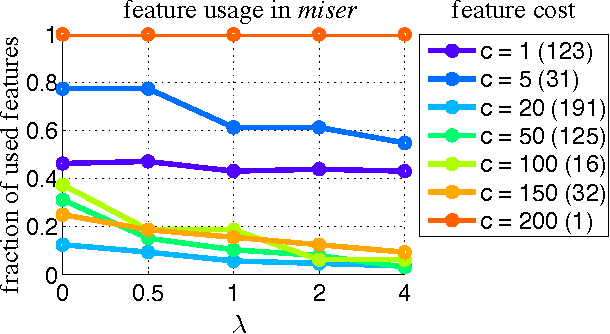
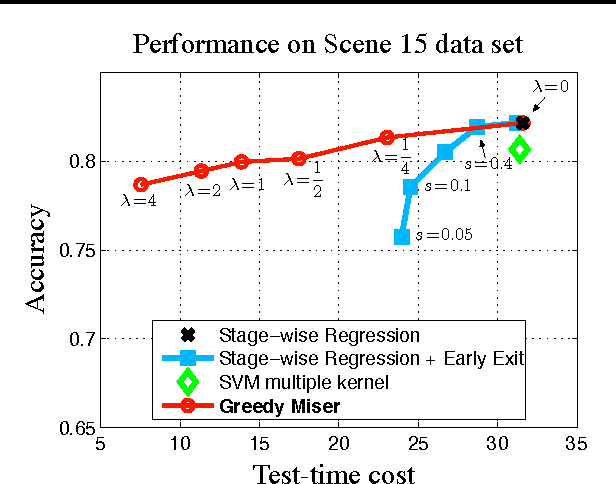

As machine learning algorithms enter applications in industrial settings, there is increased interest in controlling their cpu-time during testing. The cpu-time consists of the running time of the algorithm and the extraction time of the features. The latter can vary drastically when the feature set is diverse. In this paper, we propose an algorithm, the Greedy Miser, that incorporates the feature extraction cost during training to explicitly minimize the cpu-time during testing. The algorithm is a straightforward extension of stage-wise regression and is equally suitable for regression or multi-class classification. Compared to prior work, it is significantly more cost-effective and scales to larger data sets.
Marginalized Denoising Autoencoders for Domain Adaptation
Jun 18, 2012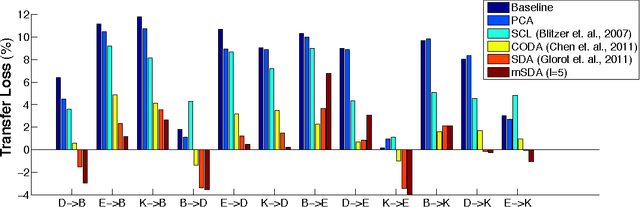
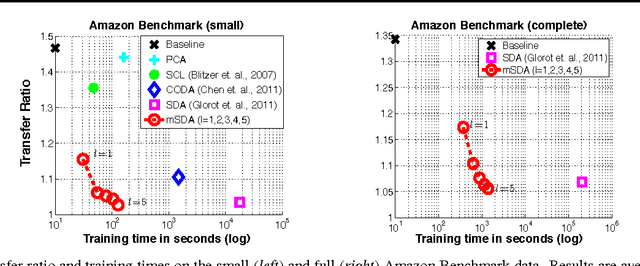
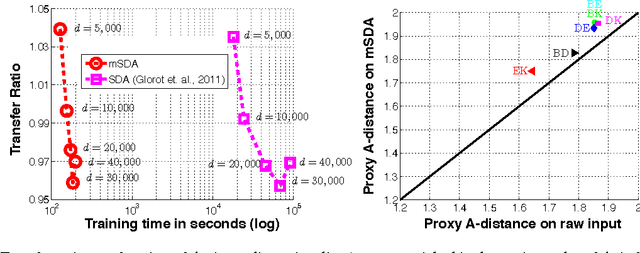
Stacked denoising autoencoders (SDAs) have been successfully used to learn new representations for domain adaptation. Recently, they have attained record accuracy on standard benchmark tasks of sentiment analysis across different text domains. SDAs learn robust data representations by reconstruction, recovering original features from data that are artificially corrupted with noise. In this paper, we propose marginalized SDA (mSDA) that addresses two crucial limitations of SDAs: high computational cost and lack of scalability to high-dimensional features. In contrast to SDAs, our approach of mSDA marginalizes noise and thus does not require stochastic gradient descent or other optimization algorithms to learn parameters ? in fact, they are computed in closed-form. Consequently, mSDA, which can be implemented in only 20 lines of MATLAB^{TM}, significantly speeds up SDAs by two orders of magnitude. Furthermore, the representations learnt by mSDA are as effective as the traditional SDAs, attaining almost identical accuracies in benchmark tasks.