 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-sensitive Learning for Utility Optimization in Online Advertising Auctions
Jul 12, 2017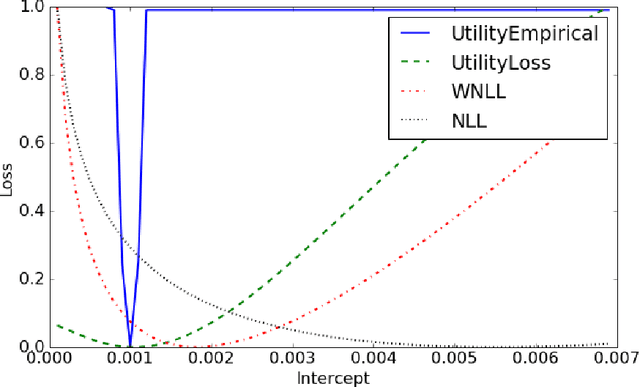


One of the most challenging problems in computational advertising is the prediction of click-through and conversion rates for bidding in online advertising auctions. An unaddressed problem in previous approaches is the existence of highly non-uniform misprediction costs. While for model evaluation these costs have been taken into account through recently proposed business-aware offline metrics -- such as the Utility metric which measures the impact on advertiser profit -- this is not the case when training the models themselves. In this paper, to bridge the gap, we formally analyze the relationship between optimizing the Utility metric and the log loss, which is considered as one of the state-of-the-art approaches in conversion modeling. Our analysis motivates the idea of weighting the log loss with the business value of the predicted outcome. We present and analyze a new cost weighting scheme and show that significant gains in offline and online performance can be achieved.
Field-aware Factorization Machines in a Real-world Online Advertising System
Feb 23, 2017


Predicting user response is one of the core machine learning tasks in computational advertising. Field-aware Factorization Machines (FFM) have recently been established as a state-of-the-art method for that problem and in particular won two Kaggle challenges. This paper presents some results from implementing this method in a production system that predicts click-through and conversion rates for display advertising and shows that this method it is not only effective to win challenges but is also valuable in a real-world prediction system. We also discuss some specific challenges and solutions to reduce the training time, namely the use of an innovative seeding algorithm and a distributed learning mechanism.
A Reliable Effective Terascale Linear Learning System
Jul 12, 2013We present a system and a set of techniques for learning linear predictors with convex losses on terascale datasets, with trillions of features, {The number of features here refers to the number of non-zero entries in the data matrix.} billions of training examples and millions of parameters in an hour using a cluster of 1000 machines. Individually none of the component techniques are new, but the careful synthesis required to obtain an efficient implementation is. The result is, up to our knowledge, the most scalable and efficient linear learning system reported in the literature (as of 2011 when our experiments were conducted). We describe and thoroughly evaluate the components of the system, showing the importance of the various design choices.
Distance Metric Learning for Kernel Machines
Jan 08, 2013
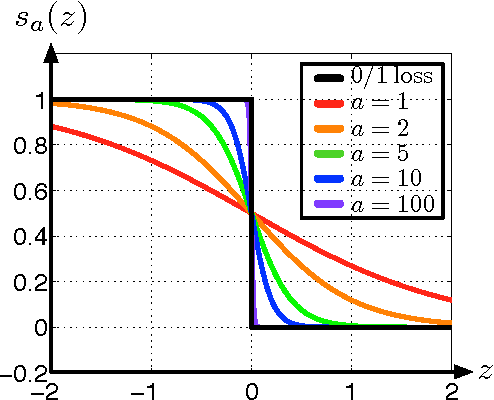

Recent work in metric learning has significantly improved the state-of-the-art in k-nearest neighbor classification. Support vector machines (SVM), particularly with RBF kernels, are amongst the most popular classification algorithms that uses distance metrics to compare examples. This paper provides an empirical analysis of the efficacy of three of the most popular Mahalanobis metric learning algorithms as pre-processing for SVM training. We show that none of these algorithms generate metrics that lead to particularly satisfying improvements for SVM-RBF classification. As a remedy we introduce support vector metric learning (SVML), a novel algorithm that seamlessly combines the learning of a Mahalanobis metric with the training of the RBF-SVM parameters. We demonstrate the capabilities of SVML on nine benchmark data sets of varying sizes and difficulties. In our study, SVML outperforms all alternative state-of-the-art metric learning algorithms in terms of accuracy and establishes itself as a serious alternative to the standard Euclidean metric with model selection by cross validation.
The Greedy Miser: Learning under Test-time Budgets
Jun 27, 2012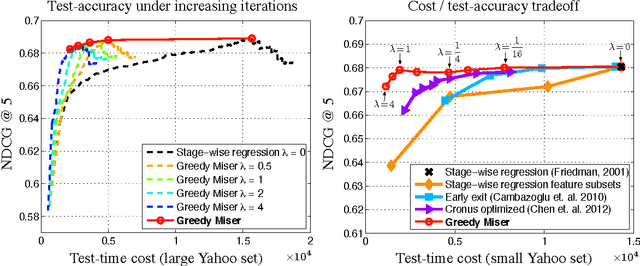
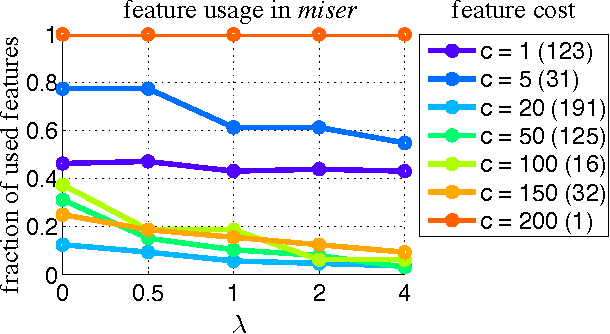
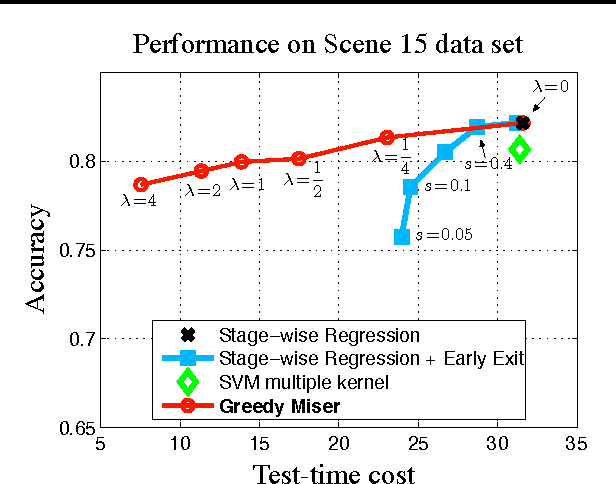

As machine learning algorithms enter applications in industrial settings, there is increased interest in controlling their cpu-time during testing. The cpu-time consists of the running time of the algorithm and the extraction time of the features. The latter can vary drastically when the feature set is diverse. In this paper, we propose an algorithm, the Greedy Miser, that incorporates the feature extraction cost during training to explicitly minimize the cpu-time during testing. The algorithm is a straightforward extension of stage-wise regression and is equally suitable for regression or multi-class classification. Compared to prior work, it is significantly more cost-effective and scales to larger data sets.