 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Search At LinkedIn
Feb 07, 2026Semantic search with large language models (LLMs) enables retrieval by meaning rather than keyword overlap, but scaling it requires major inference efficiency advances. We present LinkedIn's LLM-based semantic search framework for AI Job Search and AI People Search, combining an LLM relevance judge, embedding-based retrieval, and a compact Small Language Model trained via multi-teacher distillation to jointly optimize relevance and engagement. A prefill-oriented inference architecture co-designed with model pruning, context compression, and text-embedding hybrid interactions boosts ranking throughput by over 75x under a fixed latency constraint while preserving near-teacher-level NDCG, enabling one of the first production LLM-based ranking systems with efficiency comparable to traditional approaches and delivering significant gains in quality and user engagement.
Learning to Retrieve for Job Matching
Feb 21, 2024



Web-scale search systems typically tackle the scalability challenge with a two-step paradigm: retrieval and ranking. The retrieval step, also known as candidate selection, often involves extracting standardized entities, creating an inverted index, and performing term matching for retrieval. Such traditional methods require manual and time-consuming development of query models. In this paper, we discuss applying learning-to-retrieve technology to enhance LinkedIns job search and recommendation systems. In the realm of promoted jobs, the key objective is to improve the quality of applicants, thereby delivering value to recruiter customers. To achieve this, we leverage confirmed hire data to construct a graph that evaluates a seeker's qualification for a job, and utilize learned links for retrieval. Our learned model is easy to explain, debug, and adjust. On the other hand, the focus for organic jobs is to optimize seeker engagement. We accomplished this by training embeddings for personalized retrieval, fortified by a set of rules derived from the categorization of member feedback. In addition to a solution based on a conventional inverted index, we developed an on-GPU solution capable of supporting both KNN and term matching efficiently.
Field-aware Factorization Machines in a Real-world Online Advertising System
Feb 23, 2017


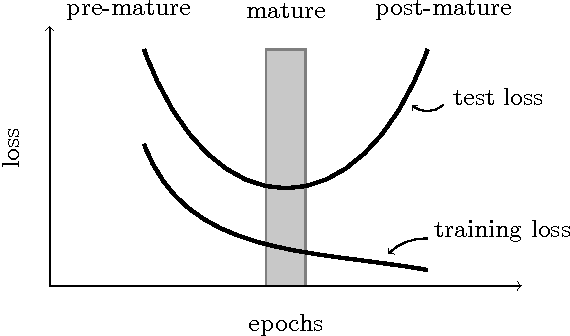
Predicting user response is one of the core machine learning tasks in computational advertising. Field-aware Factorization Machines (FFM) have recently been established as a state-of-the-art method for that problem and in particular won two Kaggle challenges. This paper presents some results from implementing this method in a production system that predicts click-through and conversion rates for display advertising and shows that this method it is not only effective to win challenges but is also valuable in a real-world prediction system. We also discuss some specific challenges and solutions to reduce the training time, namely the use of an innovative seeding algorithm and a distributed learning mechanism.