 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarginalizing Corrupted Features
Paper and Code
Feb 27, 2014
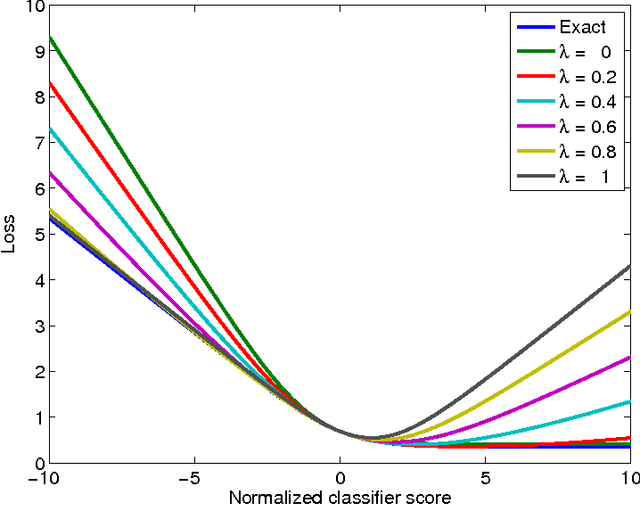
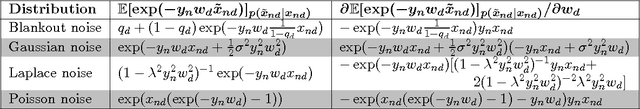
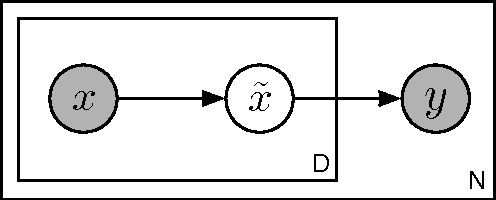
The goal of machine learning is to develop predictors that generalize well to test data. Ideally, this is achieved by training on an almost infinitely large training data set that captures all variations in the data distribution. In practical learning settings, however, we do not have infinite data and our predictors may overfit. Overfitting may be combatted, for example, by adding a regularizer to the training objective or by defining a prior over the model parameters and performing Bayesian inference. In this paper, we propose a third, alternative approach to combat overfitting: we extend the training set with infinitely many artificial training examples that are obtained by corrupting the original training data. We show that this approach is practical and efficient for a range of predictors and corruption models. Our approach, called marginalized corrupted features (MCF), trains robust predictors by minimizing the expected value of the loss function under the corruption model. We show empirically on a variety of data sets that MCF classifiers can be trained efficiently, may generalize substantially better to test data, and are also more robust to feature deletion at test time.