 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dense Material Segmentation Dataset for Indoor and Outdoor Scene Parsing
Jul 21, 2022

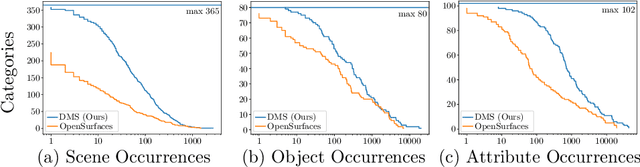

A key algorithm for understanding the world is material segmentation, which assigns a label (metal, glass, etc.) to each pixel. We find that a model trained on existing data underperforms in some settings and propose to address this with a large-scale dataset of 3.2 million dense segments on 44,560 indoor and outdoor images, which is 23x more segments than existing data. Our data covers a more diverse set of scenes, objects, viewpoints and materials, and contains a more fair distribution of skin types. We show that a model trained on our data outperforms a state-of-the-art model across datasets and viewpoints. We propose a large-scale scene parsing benchmark and baseline of 0.729 per-pixel accuracy, 0.585 mean class accuracy and 0.420 mean IoU across 46 materials.
Block Annotation: Better Image Annotation for Semantic Segmentation with Sub-Image Decomposition
Feb 16, 2020
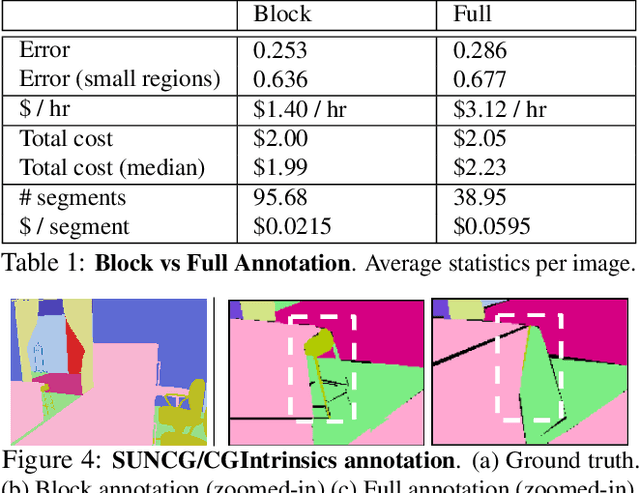

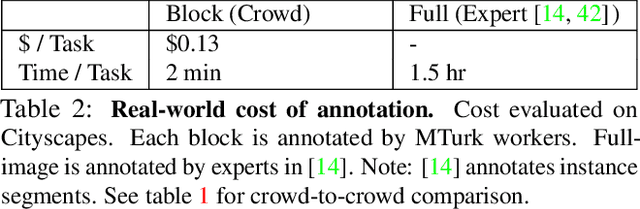
Image datasets with high-quality pixel-level annotations are valuable for semantic segmentation: labelling every pixel in an image ensures that rare classes and small objects are annotated. However, full-image annotations are expensive, with experts spending up to 90 minutes per image. We propose block sub-image annotation as a replacement for full-image annotation. Despite the attention cost of frequent task switching, we find that block annotations can be crowdsourced at higher quality compared to full-image annotation with equal monetary cost using existing annotation tools developed for full-image annotation. Surprisingly, we find that 50% pixels annotated with blocks allows semantic segmentation to achieve equivalent performance to 100% pixels annotated. Furthermore, as little as 12% of pixels annotated allows performance as high as 98% of the performance with dense annotation. In weakly-supervised settings, block annotation outperforms existing methods by 3-4% (absolute) given equivalent annotation time. To recover the necessary global structure for applications such as characterizing spatial context and affordance relationships, we propose an effective method to inpaint block-annotated images with high-quality labels without additional human effort. As such, fewer annotations can also be used for these applications compared to full-image annotation.
Deep Feature Interpolation for Image Content Changes
Jun 19, 2017
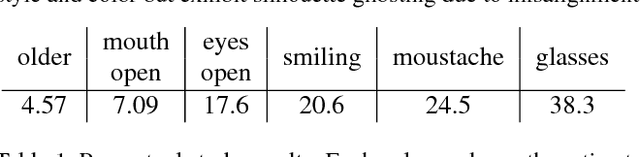

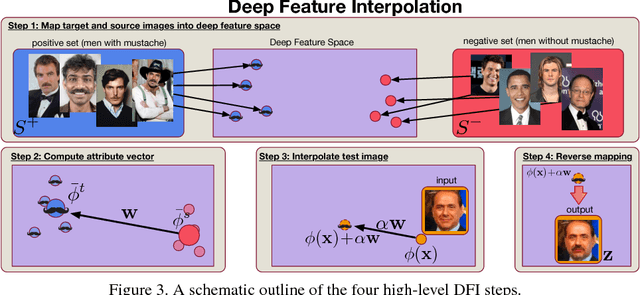
We propose Deep Feature Interpolation (DFI), a new data-driven baseline for automatic high-resolution image transformation. As the name suggests, it relies only on simple linear interpolation of deep convolutional features from pre-trained convnets. We show that despite its simplicity, DFI can perform high-level semantic transformations like "make older/younger", "make bespectacled", "add smile", among others, surprisingly well - sometimes even matching or outperforming the state-of-the-art. This is particularly unexpected as DFI requires no specialized network architecture or even any deep network to be trained for these tasks. DFI therefore can be used as a new baseline to evaluate more complex algorithms and provides a practical answer to the question of which image transformation tasks are still challenging in the rise of deep learning.
Deep Manifold Traversal: Changing Labels with Convolutional Features
Mar 17, 2016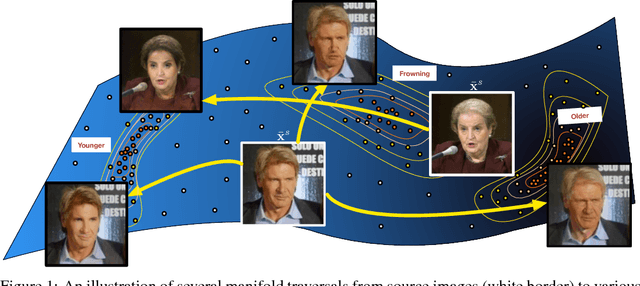
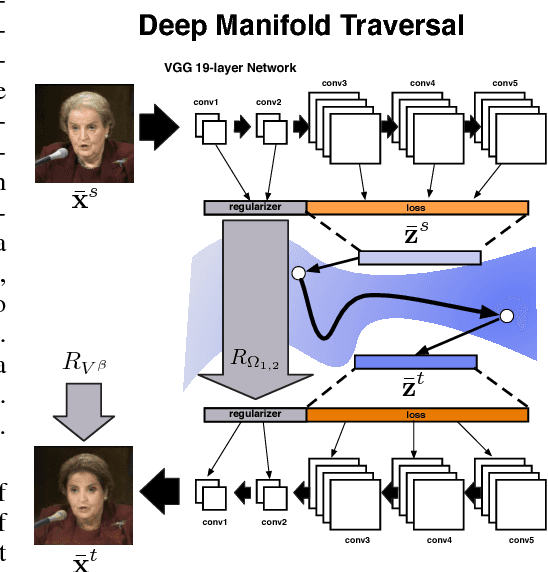


Many tasks in computer vision can be cast as a "label changing" problem, where the goal is to make a semantic change to the appearance of an image or some subject in an image in order to alter the class membership. Although successful task-specific methods have been developed for some label changing applications, to date no general purpose method exists. Motivated by this we propose deep manifold traversal, a method that addresses the problem in its most general form: it first approximates the manifold of natural images then morphs a test image along a traversal path away from a source class and towards a target class while staying near the manifold throughout. The resulting algorithm is surprisingly effective and versatile. It is completely data driven, requiring only an example set of images from the desired source and target domains. We demonstrate deep manifold traversal on highly diverse label changing tasks: changing an individual's appearance (age and hair color), changing the season of an outdoor image, and transforming a city skyline towards nighttime.
From A to Z: Supervised Transfer of Style and Content Using Deep Neural Network Generators
Mar 07, 2016
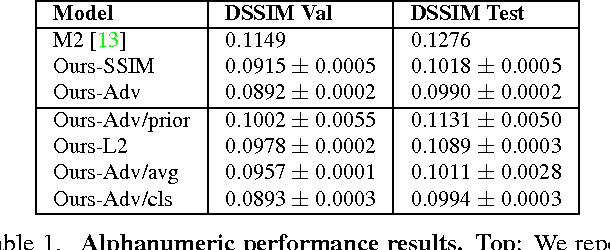
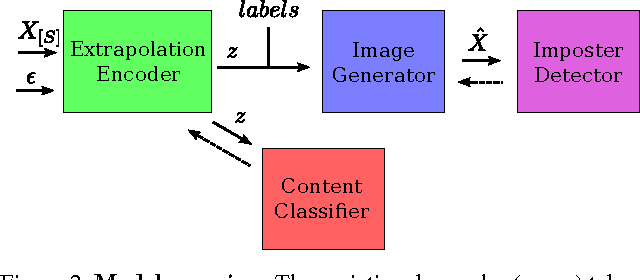

We propose a new neural network architecture for solving single-image analogies - the generation of an entire set of stylistically similar images from just a single input image. Solving this problem requires separating image style from content. Our network is a modified variational autoencoder (VAE) that supports supervised training of single-image analogies and in-network evaluation of outputs with a structured similarity objective that captures pixel covariances. On the challenging task of generating a 62-letter font from a single example letter we produce images with 22.4% lower dissimilarity to the ground truth than state-of-the-art.
Material Recognition in the Wild with the Materials in Context Database
Apr 14, 2015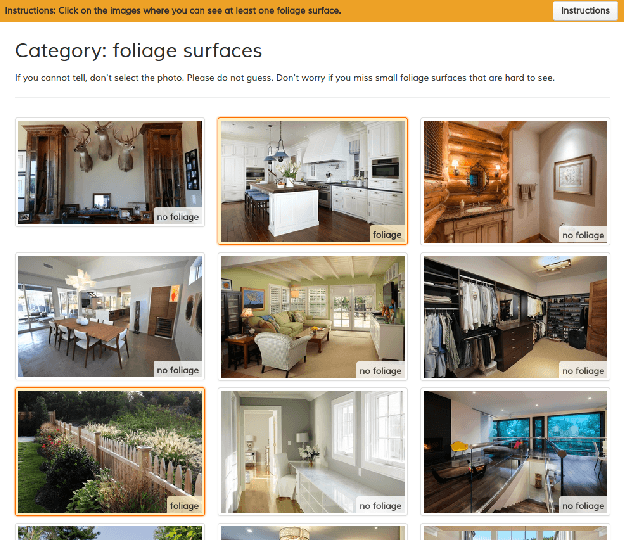
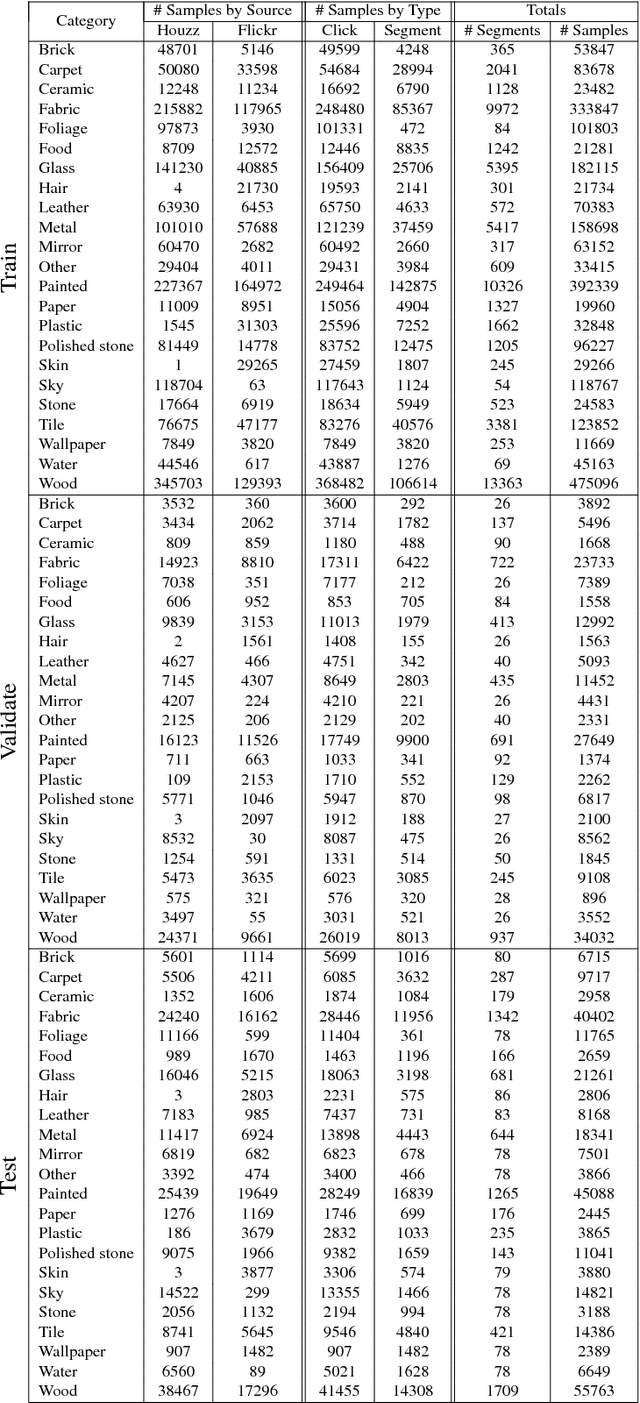

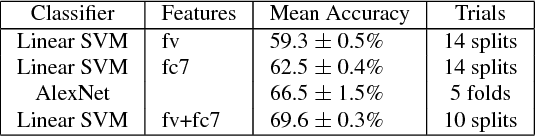
Recognizing materials in real-world images is a challenging task. Real-world materials have rich surface texture, geometry, lighting conditions, and clutter, which combine to make the problem particularly difficult. In this paper, we introduce a new, large-scale, open dataset of materials in the wild, the Materials in Context Database (MINC), and combine this dataset with deep learning to achieve material recognition and segmentation of images in the wild. MINC is an order of magnitude larger than previous material databases, while being more diverse and well-sampled across its 23 categories. Using MINC, we train convolutional neural networks (CNNs) for two tasks: classifying materials from patches, and simultaneous material recognition and segmentation in full images. For patch-based classification on MINC we found that the best performing CNN architectures can achieve 85.2% mean class accuracy. We convert these trained CNN classifiers into an efficient fully convolutional framework combined with a fully connected conditional random field (CRF) to predict the material at every pixel in an image, achieving 73.1% mean class accuracy. Our experiments demonstrate that having a large, well-sampled dataset such as MINC is crucial for real-world material recognition and segmentation.