Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom A to Z: Supervised Transfer of Style and Content Using Deep Neural Network Generators
Paper and Code
Mar 07, 2016
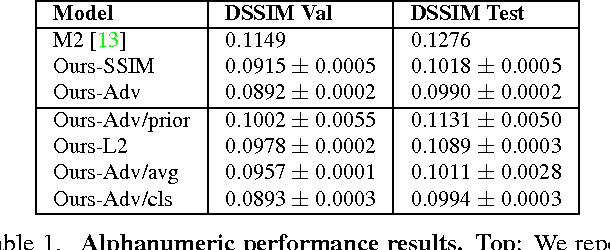
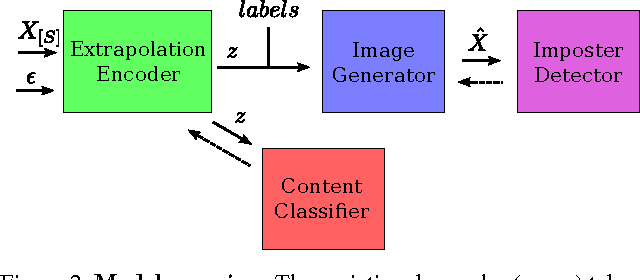

We propose a new neural network architecture for solving single-image analogies - the generation of an entire set of stylistically similar images from just a single input image. Solving this problem requires separating image style from content. Our network is a modified variational autoencoder (VAE) that supports supervised training of single-image analogies and in-network evaluation of outputs with a structured similarity objective that captures pixel covariances. On the challenging task of generating a 62-letter font from a single example letter we produce images with 22.4% lower dissimilarity to the ground truth than state-of-the-art.
View paper on