 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWOD-E2E: Waymo Open Dataset for End-to-End Driving in Challenging Long-tail Scenarios
Oct 30, 2025Vision-based end-to-end (E2E) driving has garnered significant interest in the research community due to its scalability and synergy with multimodal large language models (MLLMs). However, current E2E driving benchmarks primarily feature nominal scenarios, failing to adequately test the true potential of these systems. Furthermore, existing open-loop evaluation metrics often fall short in capturing the multi-modal nature of driving or effectively evaluating performance in long-tail scenarios. To address these gaps, we introduce the Waymo Open Dataset for End-to-End Driving (WOD-E2E). WOD-E2E contains 4,021 driving segments (approximately 12 hours), specifically curated for challenging long-tail scenarios that that are rare in daily life with an occurring frequency of less than 0.03%. Concretely, each segment in WOD-E2E includes the high-level routing information, ego states, and 360-degree camera views from 8 surrounding cameras. To evaluate the E2E driving performance on these long-tail situations, we propose a novel open-loop evaluation metric: Rater Feedback Score (RFS). Unlike conventional metrics that measure the distance between predicted way points and the logs, RFS measures how closely the predicted trajectory matches rater-annotated trajectory preference labels. We have released rater preference labels for all WOD-E2E validation set segments, while the held out test set labels have been used for the 2025 WOD-E2E Challenge. Through our work, we aim to foster state of the art research into generalizable, robust, and safe end-to-end autonomous driving agents capable of handling complex real-world situations.
S4-Driver: Scalable Self-Supervised Driving Multimodal Large Language Modelwith Spatio-Temporal Visual Representation
May 30, 2025

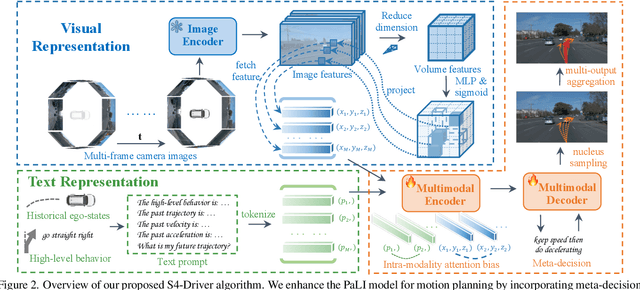

The latest advancements in multi-modal large language models (MLLMs) have spurred a strong renewed interest in end-to-end motion planning approaches for autonomous driving. Many end-to-end approaches rely on human annotations to learn intermediate perception and prediction tasks, while purely self-supervised approaches--which directly learn from sensor inputs to generate planning trajectories without human annotations often underperform the state of the art. We observe a key gap in the input representation space: end-to-end approaches built on MLLMs are often pretrained with reasoning tasks in 2D image space rather than the native 3D space in which autonomous vehicles plan. To this end, we propose S4-Driver, a scalable self-supervised motion planning algorithm with spatio-temporal visual representation, based on the popular PaLI multimodal large language model. S4-Driver uses a novel sparse volume strategy to seamlessly transform the strong visual representation of MLLMs from perspective view to 3D space without the need to finetune the vision encoder. This representation aggregates multi-view and multi-frame visual inputs and enables better prediction of planning trajectories in 3D space. To validate our method, we run experiments on both nuScenes and Waymo Open Motion Dataset (with in-house camera data). Results show that S4-Driver performs favorably against existing supervised multi-task approaches while requiring no human annotations. It also demonstrates great scalability when pretrained on large volumes of unannotated driving logs.
EMMA: End-to-End Multimodal Model for Autonomous Driving
Oct 30, 2024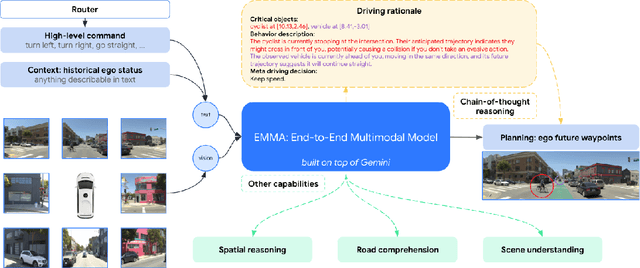
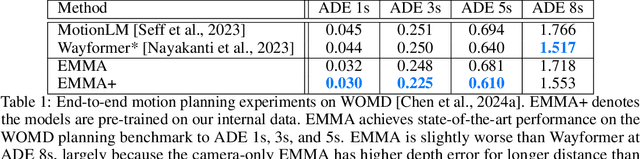
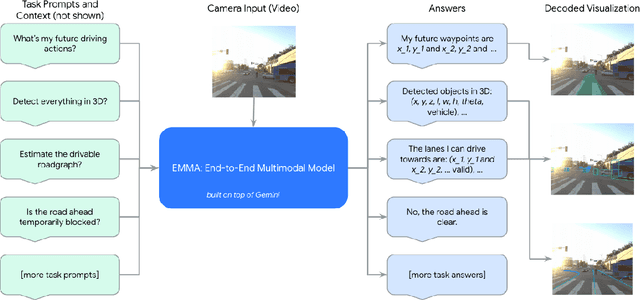
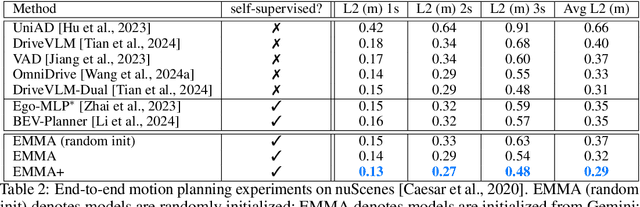
We introduce EMMA, an End-to-end Multimodal Model for Autonomous driving. Built on a multi-modal large language model foundation, EMMA directly maps raw camera sensor data into various driving-specific outputs, including planner trajectories, perception objects, and road graph elements. EMMA maximizes the utility of world knowledge from the pre-trained large language models, by representing all non-sensor inputs (e.g. navigation instructions and ego vehicle status) and outputs (e.g. trajectories and 3D locations) as natural language text. This approach allows EMMA to jointly process various driving tasks in a unified language space, and generate the outputs for each task using task-specific prompts. Empirically, we demonstrate EMMA's effectiveness by achieving state-of-the-art performance in motion planning on nuScenes as well as competitive results on the Waymo Open Motion Dataset (WOMD). EMMA also yields competitive results for camera-primary 3D object detection on the Waymo Open Dataset (WOD). We show that co-training EMMA with planner trajectories, object detection, and road graph tasks yields improvements across all three domains, highlighting EMMA's potential as a generalist model for autonomous driving applications. However, EMMA also exhibits certain limitations: it can process only a small amount of image frames, does not incorporate accurate 3D sensing modalities like LiDAR or radar and is computationally expensive. We hope that our results will inspire further research to mitigate these issues and to further evolve the state of the art in autonomous driving model architectures.
AutoPhoto: Aesthetic Photo Capture using Reinforcement Learning
Sep 21, 2021



The process of capturing a well-composed photo is difficult and it takes years of experience to master. We propose a novel pipeline for an autonomous agent to automatically capture an aesthetic photograph by navigating within a local region in a scene. Instead of classical optimization over heuristics such as the rule-of-thirds, we adopt a data-driven aesthetics estimator to assess photo quality. A reinforcement learning framework is used to optimize the model with respect to the learned aesthetics metric. We train our model in simulation with indoor scenes, and we demonstrate that our system can capture aesthetic photos in both simulation and real world environments on a ground robot. To our knowledge, this is the first system that can automatically explore an environment to capture an aesthetic photo with respect to a learned aesthetic estimator.
What Can Style Transfer and Paintings Do For Model Robustness?
Nov 30, 2020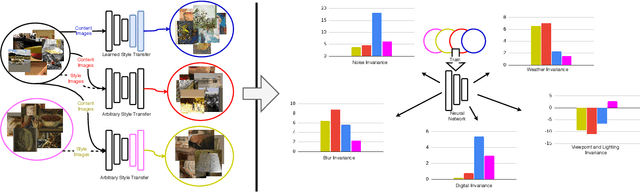
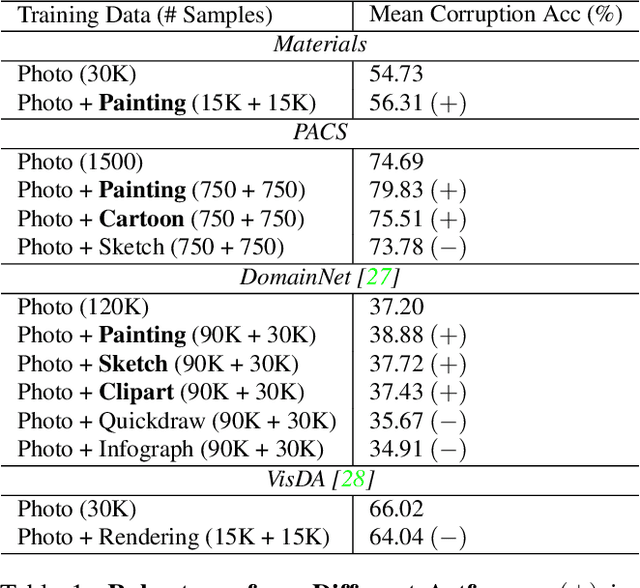
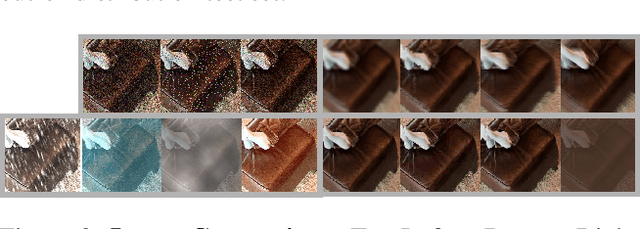
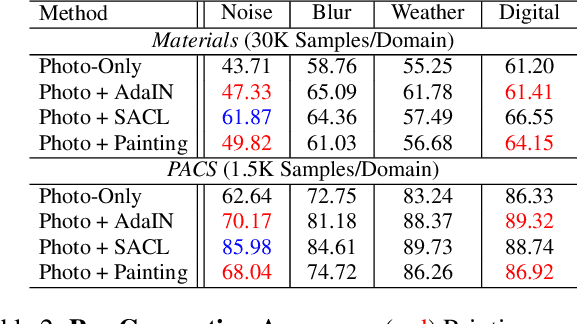
A common strategy for improving model robustness is through data augmentations. Data augmentations encourage models to learn desired invariances, such as invariance to horizontal flipping or small changes in color. Recent work has shown that arbitrary style transfer can be used as a form of data augmentation to encourage invariance to textures by creating painting-like images from photographs. However, a stylized photograph is not quite the same as an artist-created painting. Artists depict perceptually meaningful cues in paintings so that humans can recognize salient components in scenes, an emphasis which is not enforced in style transfer. Therefore, we study how style transfer and paintings differ in their impact on model robustness. First, we investigate the role of paintings as style images for stylization-based data augmentation. We find that style transfer functions well even without paintings as style images. Second, we show that learning from paintings as a form of perceptual data augmentation can improve model robustness. Finally, we investigate the invariances learned from stylization and from paintings, and show that models learn different invariances from these differing forms of data. Our results provide insights into how stylization improves model robustness, and provide evidence that artist-created paintings can be a valuable source of data for model robustness.
Insights From A Large-Scale Database of Material Depictions In Paintings
Nov 24, 2020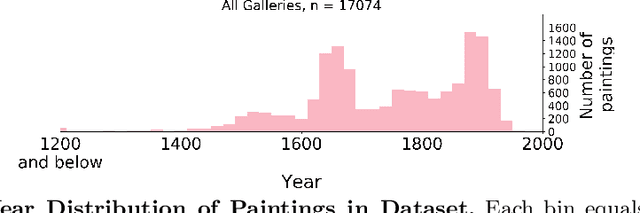
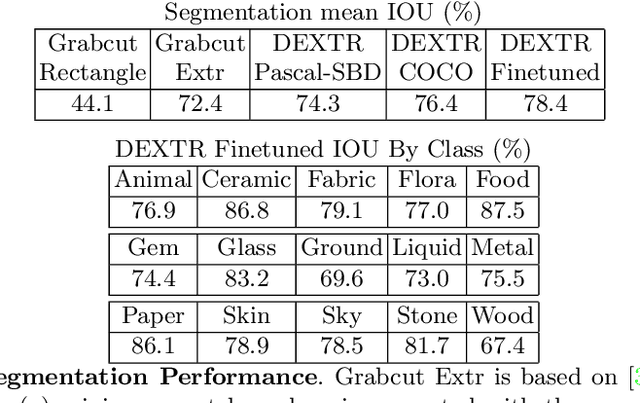

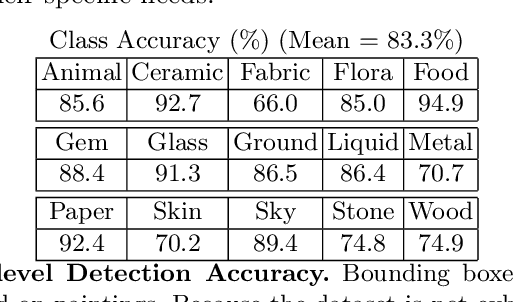
Deep learning has paved the way for strong recognition systems which are often both trained on and applied to natural images. In this paper, we examine the give-and-take relationship between such visual recognition systems and the rich information available in the fine arts. First, we find that visual recognition systems designed for natural images can work surprisingly well on paintings. In particular, we find that interactive segmentation tools can be used to cleanly annotate polygonal segments within paintings, a task which is time consuming to undertake by hand. We also find that FasterRCNN, a model which has been designed for object recognition in natural scenes, can be quickly repurposed for detection of materials in paintings. Second, we show that learning from paintings can be beneficial for neural networks that are intended to be used on natural images. We find that training on paintings instead of natural images can improve the quality of learned features and we further find that a large number of paintings can be a valuable source of test data for evaluating domain adaptation algorithms. Our experiments are based on a novel large-scale annotated database of material depictions in paintings which we detail in a separate manuscript.
DeepSemanticHPPC: Hypothesis-based Planning over Uncertain Semantic Point Clouds
Mar 06, 2020



Planning in unstructured environments is challenging -- it relies on sensing, perception, scene reconstruction, and reasoning about various uncertainties. We propose DeepSemanticHPPC, a novel uncertainty-aware hypothesis-based planner for unstructured environments. Our algorithmic pipeline consists of: a deep Bayesian neural network which segments surfaces with uncertainty estimates; a flexible point cloud scene representation; a next-best-view planner which minimizes the uncertainty of scene semantics using sparse visual measurements; and a hypothesis-based path planner that proposes multiple kinematically feasible paths with evolving safety confidences given next-best-view measurements. Our pipeline iteratively decreases semantic uncertainty along planned paths, filtering out unsafe paths with high confidence. We show that our framework plans safe paths in real-world environments where existing path planners typically fail.
Block Annotation: Better Image Annotation for Semantic Segmentation with Sub-Image Decomposition
Feb 16, 2020
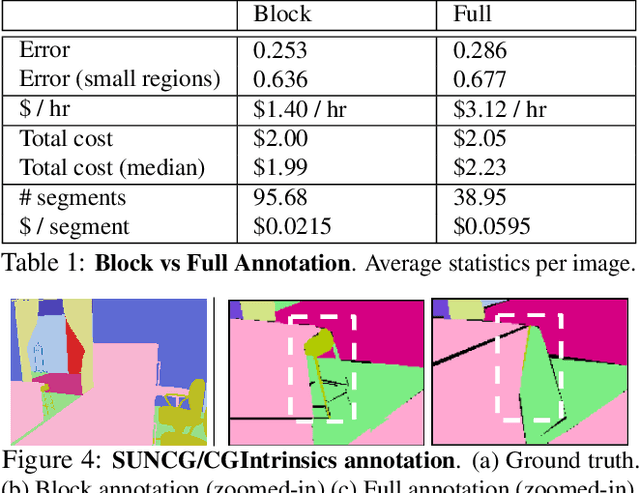

Image datasets with high-quality pixel-level annotations are valuable for semantic segmentation: labelling every pixel in an image ensures that rare classes and small objects are annotated. However, full-image annotations are expensive, with experts spending up to 90 minutes per image. We propose block sub-image annotation as a replacement for full-image annotation. Despite the attention cost of frequent task switching, we find that block annotations can be crowdsourced at higher quality compared to full-image annotation with equal monetary cost using existing annotation tools developed for full-image annotation. Surprisingly, we find that 50% pixels annotated with blocks allows semantic segmentation to achieve equivalent performance to 100% pixels annotated. Furthermore, as little as 12% of pixels annotated allows performance as high as 98% of the performance with dense annotation. In weakly-supervised settings, block annotation outperforms existing methods by 3-4% (absolute) given equivalent annotation time. To recover the necessary global structure for applications such as characterizing spatial context and affordance relationships, we propose an effective method to inpaint block-annotated images with high-quality labels without additional human effort. As such, fewer annotations can also be used for these applications compared to full-image annotation.
Learning Material-Aware Local Descriptors for 3D Shapes
Oct 20, 2018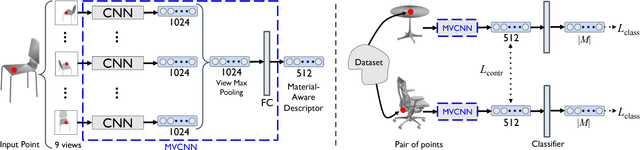
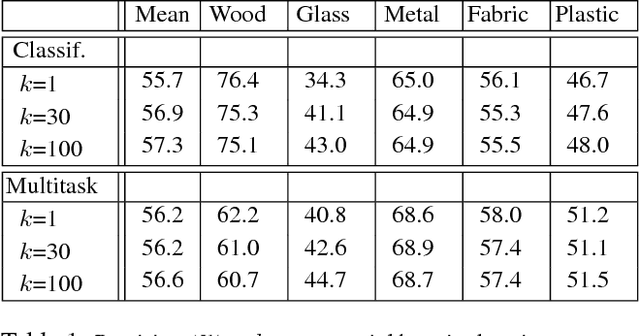
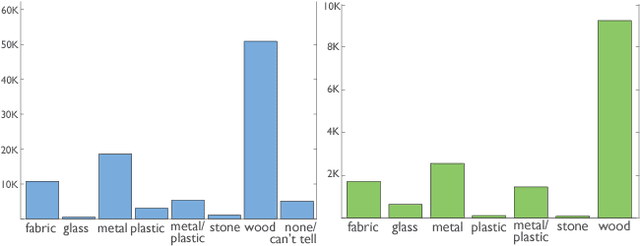
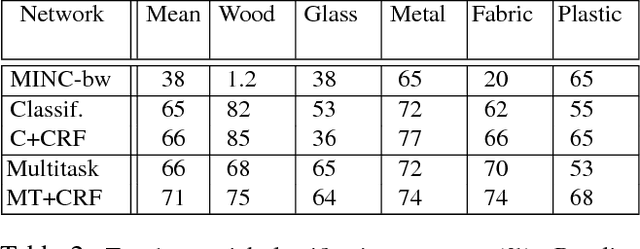
Material understanding is critical for design, geometric modeling, and analysis of functional objects. We enable material-aware 3D shape analysis by employing a projective convolutional neural network architecture to learn material- aware descriptors from view-based representations of 3D points for point-wise material classification or material- aware retrieval. Unfortunately, only a small fraction of shapes in 3D repositories are labeled with physical mate- rials, posing a challenge for learning methods. To address this challenge, we crowdsource a dataset of 3080 3D shapes with part-wise material labels. We focus on furniture models which exhibit interesting structure and material variabil- ity. In addition, we also contribute a high-quality expert- labeled benchmark of 115 shapes from Herman-Miller and IKEA for evaluation. We further apply a mesh-aware con- ditional random field, which incorporates rotational and reflective symmetries, to smooth our local material predic- tions across neighboring surface patches. We demonstrate the effectiveness of our learned descriptors for automatic texturing, material-aware retrieval, and physical simulation. The dataset and code will be publicly available.