 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Material-Aware Local Descriptors for 3D Shapes
Oct 20, 2018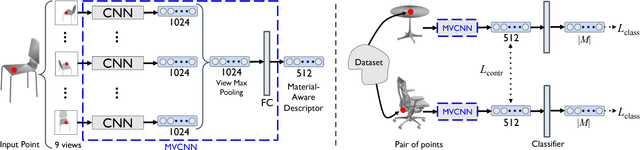
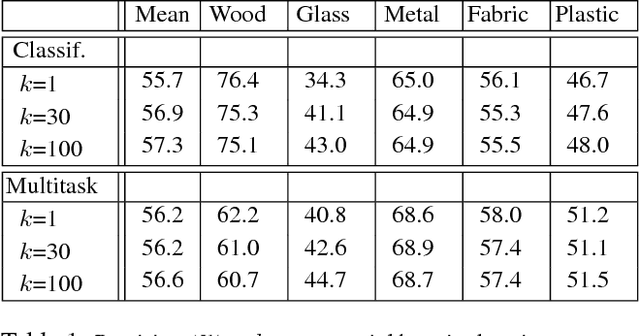
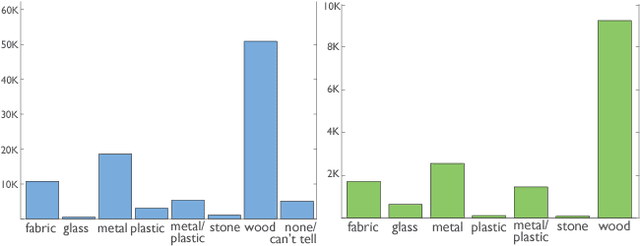
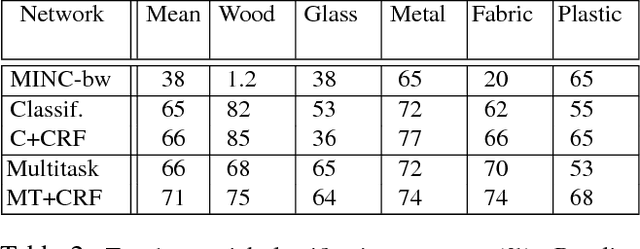
Material understanding is critical for design, geometric modeling, and analysis of functional objects. We enable material-aware 3D shape analysis by employing a projective convolutional neural network architecture to learn material- aware descriptors from view-based representations of 3D points for point-wise material classification or material- aware retrieval. Unfortunately, only a small fraction of shapes in 3D repositories are labeled with physical mate- rials, posing a challenge for learning methods. To address this challenge, we crowdsource a dataset of 3080 3D shapes with part-wise material labels. We focus on furniture models which exhibit interesting structure and material variabil- ity. In addition, we also contribute a high-quality expert- labeled benchmark of 115 shapes from Herman-Miller and IKEA for evaluation. We further apply a mesh-aware con- ditional random field, which incorporates rotational and reflective symmetries, to smooth our local material predic- tions across neighboring surface patches. We demonstrate the effectiveness of our learned descriptors for automatic texturing, material-aware retrieval, and physical simulation. The dataset and code will be publicly available.
Shading Annotations in the Wild
May 02, 2017
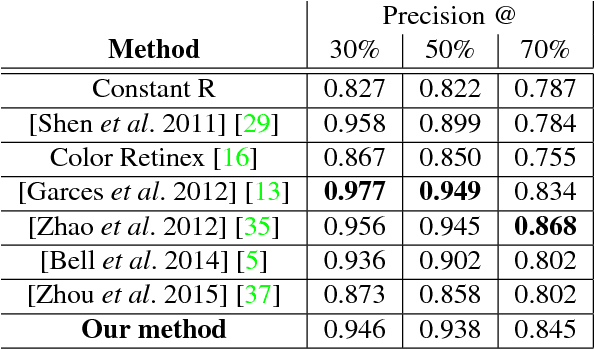


Understanding shading effects in images is critical for a variety of vision and graphics problems, including intrinsic image decomposition, shadow removal, image relighting, and inverse rendering. As is the case with other vision tasks, machine learning is a promising approach to understanding shading - but there is little ground truth shading data available for real-world images. We introduce Shading Annotations in the Wild (SAW), a new large-scale, public dataset of shading annotations in indoor scenes, comprised of multiple forms of shading judgments obtained via crowdsourcing, along with shading annotations automatically generated from RGB-D imagery. We use this data to train a convolutional neural network to predict per-pixel shading information in an image. We demonstrate the value of our data and network in an application to intrinsic images, where we can reduce decomposition artifacts produced by existing algorithms. Our database is available at http://opensurfaces.cs.cornell.edu/saw/.
Learning Visual Clothing Style with Heterogeneous Dyadic Co-occurrences
Sep 24, 2015
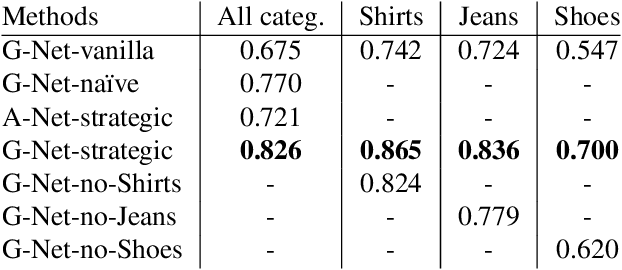
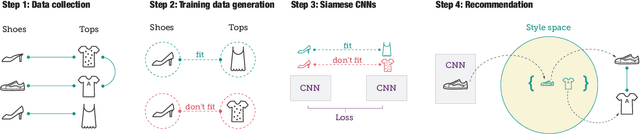

With the rapid proliferation of smart mobile devices, users now take millions of photos every day. These include large numbers of clothing and accessory images. We would like to answer questions like `What outfit goes well with this pair of shoes?' To answer these types of questions, one has to go beyond learning visual similarity and learn a visual notion of compatibility across categories. In this paper, we propose a novel learning framework to help answer these types of questions. The main idea of this framework is to learn a feature transformation from images of items into a latent space that expresses compatibility. For the feature transformation, we use a Siamese Convolutional Neural Network (CNN) architecture, where training examples are pairs of items that are either compatible or incompatible. We model compatibility based on co-occurrence in large-scale user behavior data; in particular co-purchase data from Amazon.com. To learn cross-category fit, we introduce a strategic method to sample training data, where pairs of items are heterogeneous dyads, i.e., the two elements of a pair belong to different high-level categories. While this approach is applicable to a wide variety of settings, we focus on the representative problem of learning compatible clothing style. Our results indicate that the proposed framework is capable of learning semantic information about visual style and is able to generate outfits of clothes, with items from different categories, that go well together.