 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurfR: Surface Reconstruction with Multi-scale Attention
Jun 10, 2025We propose a fast and accurate surface reconstruction algorithm for unorganized point clouds using an implicit representation. Recent learning methods are either single-object representations with small neural models that allow for high surface details but require per-object training or generalized representations that require larger models and generalize to newer shapes but lack details, and inference is slow. We propose a new implicit representation for general 3D shapes that is faster than all the baselines at their optimum resolution, with only a marginal loss in performance compared to the state-of-the-art. We achieve the best accuracy-speed trade-off using three key contributions. Many implicit methods extract features from the point cloud to classify whether a query point is inside or outside the object. First, to speed up the reconstruction, we show that this feature extraction does not need to use the query point at an early stage (lazy query). Second, we use a parallel multi-scale grid representation to develop robust features for different noise levels and input resolutions. Finally, we show that attention across scales can provide improved reconstruction results.
* Accepted in 3DV 2025
SSDNeRF: Semantic Soft Decomposition of Neural Radiance Fields
Dec 07, 2022



Neural Radiance Fields (NeRFs) encode the radiance in a scene parameterized by the scene's plenoptic function. This is achieved by using an MLP together with a mapping to a higher-dimensional space, and has been proven to capture scenes with a great level of detail. Naturally, the same parameterization can be used to encode additional properties of the scene, beyond just its radiance. A particularly interesting property in this regard is the semantic decomposition of the scene. We introduce a novel technique for semantic soft decomposition of neural radiance fields (named SSDNeRF) which jointly encodes semantic signals in combination with radiance signals of a scene. Our approach provides a soft decomposition of the scene into semantic parts, enabling us to correctly encode multiple semantic classes blending along the same direction -- an impossible feat for existing methods. Not only does this lead to a detailed, 3D semantic representation of the scene, but we also show that the regularizing effects of the MLP used for encoding help to improve the semantic representation. We show state-of-the-art segmentation and reconstruction results on a dataset of common objects and demonstrate how the proposed approach can be applied for high quality temporally consistent video editing and re-compositing on a dataset of casually captured selfie videos.
Mapping of Sparse 3D Data using Alternating Projection
Oct 09, 2020



We propose a novel technique to register sparse 3D scans in the absence of texture. While existing methods such as KinectFusion or Iterative Closest Points (ICP) heavily rely on dense point clouds, this task is particularly challenging under sparse conditions without RGB data. Sparse texture-less data does not come with high-quality boundary signal, and this prohibits the use of correspondences from corners, junctions, or boundary lines. Moreover, in the case of sparse data, it is incorrect to assume that the same point will be captured in two consecutive scans. We take a different approach and first re-parameterize the point-cloud using a large number of line segments. In this re-parameterized data, there exists a large number of line intersection (and not correspondence) constraints that allow us to solve the registration task. We propose the use of a two-step alternating projection algorithm by formulating the registration as the simultaneous satisfaction of intersection and rigidity constraints. The proposed approach outperforms other top-scoring algorithms on both Kinect and LiDAR datasets. In Kinect, we can use 100X downsampled sparse data and still outperform competing methods operating on full-resolution data.
PoseNet3D: Unsupervised 3D Human Shape and Pose Estimation
Mar 07, 2020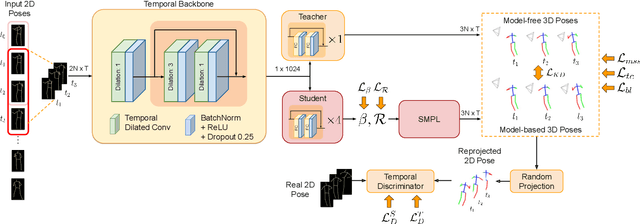
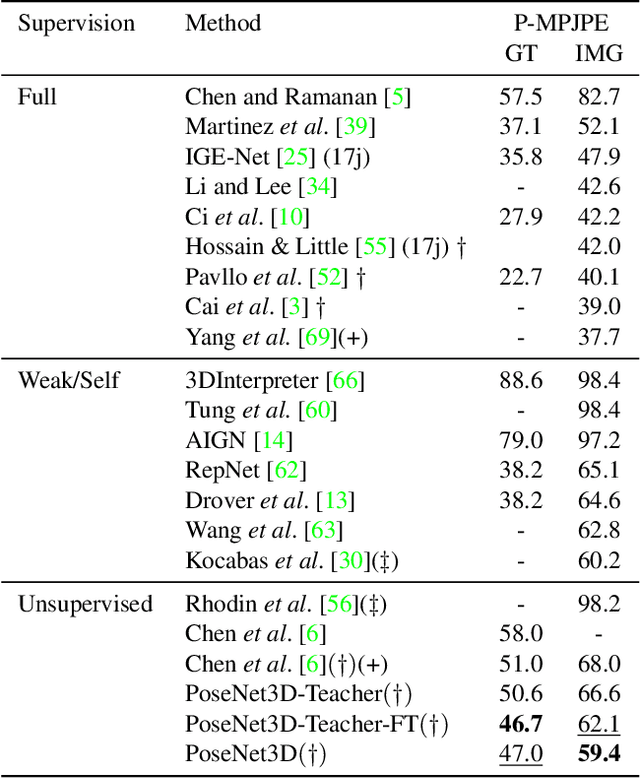
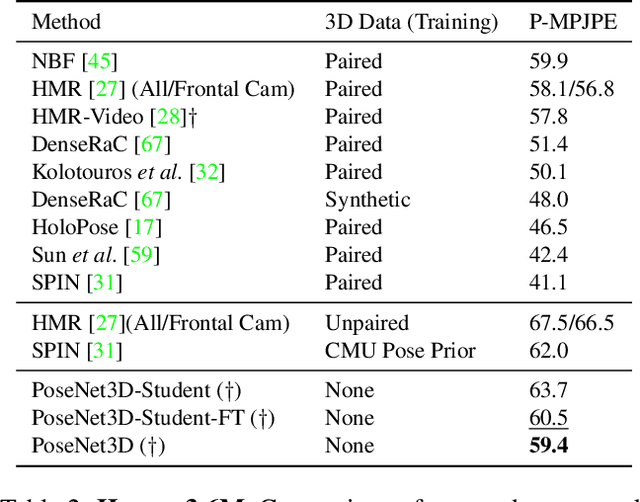
Recovering 3D human pose from 2D joints is a highly unconstrained problem. We propose a novel neural network framework, PoseNet3D, that takes 2D joints as input and outputs 3D skeletons and SMPL body model parameters. By casting our learning approach in a student-teacher framework, we avoid using any 3D data such as paired/unpaired 3D data, motion capture sequences, depth images or multi-view images during training. We first train a teacher network that outputs 3D skeletons, using only 2D poses for training. The teacher network distills its knowledge to a student network that predicts 3D pose in SMPL representation. Finally, both the teacher and the student networks are jointly fine-tuned in an end-to-end manner using temporal, self-consistency and adversarial losses, improving the accuracy of each individual network. Results on Human3.6M dataset for 3D human pose estimation demonstrate that our approach reduces the 3D joint prediction error by 18\% compared to previous unsupervised methods. Qualitative results on in-the-wild datasets show that the recovered 3D poses and meshes are natural, realistic, and flow smoothly over consecutive frames.
Can generalised relative pose estimation solve sparse 3D registration?
Jun 13, 2019
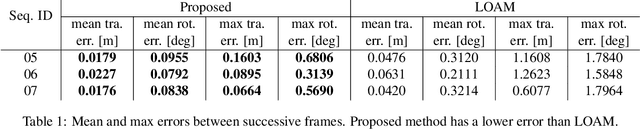

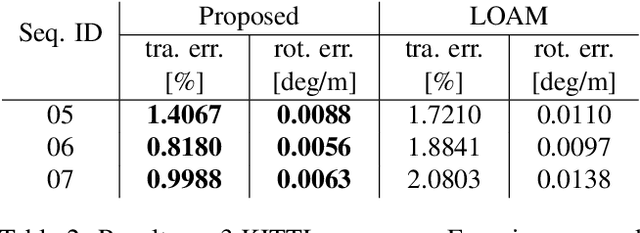
Popular 3D scan registration projects, such as Stanford digital Michelangelo or KinectFusion, exploit the high-resolution sensor data for scan alignment. It is particularly challenging to solve the registration of sparse 3D scans in the absence of RGB components. In this case, we can not establish point correspondences since the same 3D point cannot be captured in two successive scans. In contrast to correspondence based methods, we take a different viewpoint and formulate the sparse 3D registration problem based on the constraints from the intersection of line segments from adjacent scans. We obtain the line segments by modeling every horizontal and vertical scan-line as piece-wise linear segments. We propose a new alternating projection algorithm for solving the scan alignment problem using line intersection constraints. We develop two new minimal solvers for scan alignment in the presence of plane correspondences: 1) 3 line intersections and 1 plane correspondence, and 2) 1 line intersection and 2 plane correspondences. We outperform other competing methods on Kinect and LiDAR datasets.
Learning Material-Aware Local Descriptors for 3D Shapes
Oct 20, 2018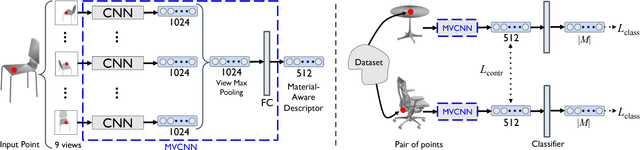
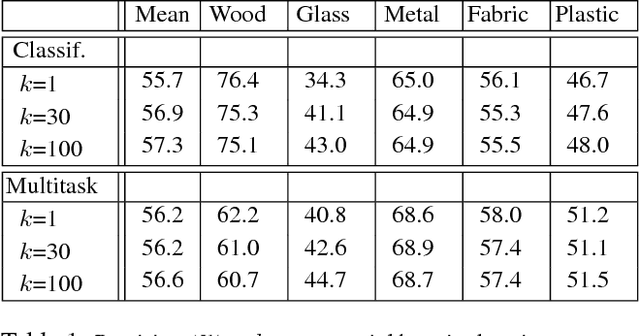
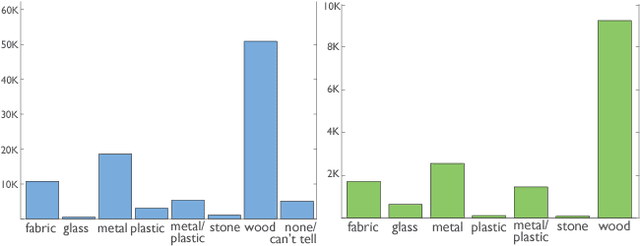
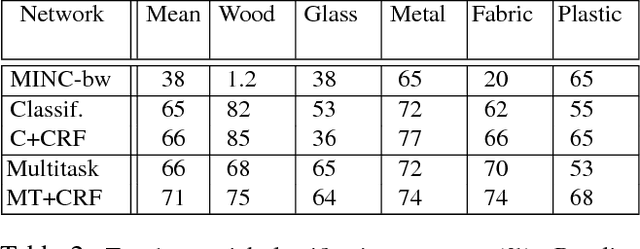
Material understanding is critical for design, geometric modeling, and analysis of functional objects. We enable material-aware 3D shape analysis by employing a projective convolutional neural network architecture to learn material- aware descriptors from view-based representations of 3D points for point-wise material classification or material- aware retrieval. Unfortunately, only a small fraction of shapes in 3D repositories are labeled with physical mate- rials, posing a challenge for learning methods. To address this challenge, we crowdsource a dataset of 3080 3D shapes with part-wise material labels. We focus on furniture models which exhibit interesting structure and material variabil- ity. In addition, we also contribute a high-quality expert- labeled benchmark of 115 shapes from Herman-Miller and IKEA for evaluation. We further apply a mesh-aware con- ditional random field, which incorporates rotational and reflective symmetries, to smooth our local material predic- tions across neighboring surface patches. We demonstrate the effectiveness of our learned descriptors for automatic texturing, material-aware retrieval, and physical simulation. The dataset and code will be publicly available.
Novel Single View Constraints for Manhattan 3D Line Reconstruction
Oct 08, 2018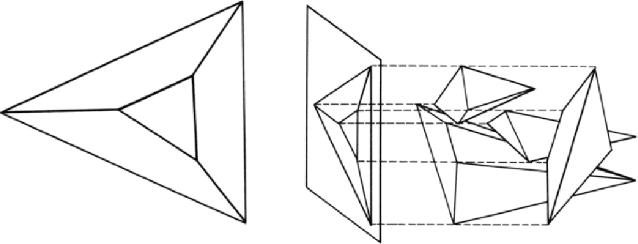

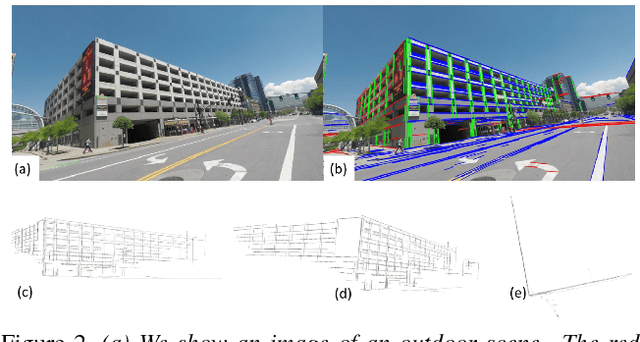

This paper proposes a novel and exact method to reconstruct line-based 3D structure from a single image using Manhattan world assumption. This problem is a distinctly unsolved problem because there can be multiple 3D reconstructions from a single image. Thus, we are often forced to look for priors like Manhattan world assumption and common scene structures. In addition to the standard orthogonality, perspective projection, and parallelism constraints, we investigate a few novel constraints based on the physical realizability of the 3D scene structure. We treat the line segments in the image to be part of a graph similar to straws and connectors game, where the goal is to back-project the line segments in 3D space and while ensuring that some of these 3D line segments connect with each other (i.e., truly intersect in 3D space) to form the 3D structure. We consider three sets of novel constraints while solving the reconstruction: (1) constraints on a series of Manhattan line intersections that form cycles, but are not all physically realizable, (2) constraints on true and false intersections in the case of nearby lines lying on the same Manhattan plane, and (3) constraints from the intersections on boundary and non-boundary line segments. The reconstruction is achieved using mixed integer linear programming (MILP), and we show compelling results on real images. Along with this paper, we will release a challenging Single View Line Reconstruction dataset with ground truth 3D line models for research purposes.