 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseNet3D: Unsupervised 3D Human Shape and Pose Estimation
Paper and Code
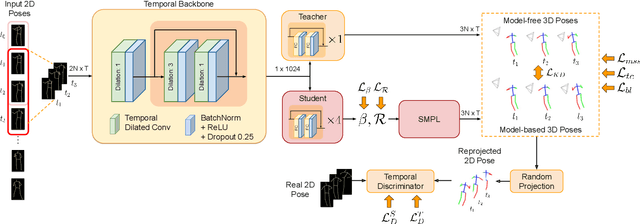
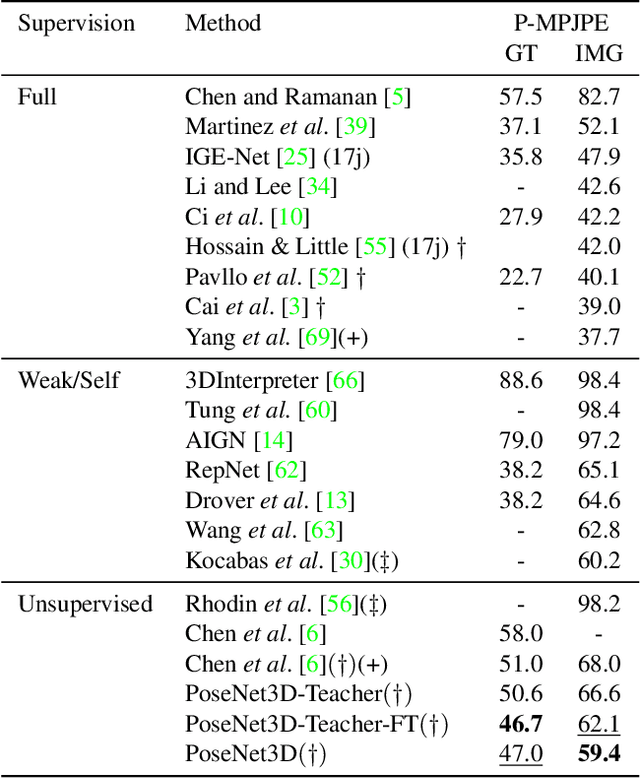
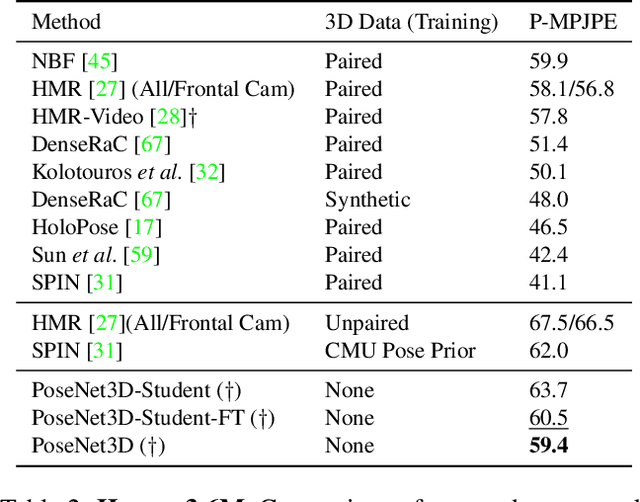
Recovering 3D human pose from 2D joints is a highly unconstrained problem. We propose a novel neural network framework, PoseNet3D, that takes 2D joints as input and outputs 3D skeletons and SMPL body model parameters. By casting our learning approach in a student-teacher framework, we avoid using any 3D data such as paired/unpaired 3D data, motion capture sequences, depth images or multi-view images during training. We first train a teacher network that outputs 3D skeletons, using only 2D poses for training. The teacher network distills its knowledge to a student network that predicts 3D pose in SMPL representation. Finally, both the teacher and the student networks are jointly fine-tuned in an end-to-end manner using temporal, self-consistency and adversarial losses, improving the accuracy of each individual network. Results on Human3.6M dataset for 3D human pose estimation demonstrate that our approach reduces the 3D joint prediction error by 18\% compared to previous unsupervised methods. Qualitative results on in-the-wild datasets show that the recovered 3D poses and meshes are natural, realistic, and flow smoothly over consecutive frames.