 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePix2Poly: A Sequence Prediction Method for End-to-end Polygonal Building Footprint Extraction from Remote Sensing Imagery
Dec 10, 2024



Extraction of building footprint polygons from remotely sensed data is essential for several urban understanding tasks such as reconstruction, navigation, and mapping. Despite significant progress in the area, extracting accurate polygonal building footprints remains an open problem. In this paper, we introduce Pix2Poly, an attention-based end-to-end trainable and differentiable deep neural network capable of directly generating explicit high-quality building footprints in a ring graph format. Pix2Poly employs a generative encoder-decoder transformer to produce a sequence of graph vertex tokens whose connectivity information is learned by an optimal matching network. Compared to previous graph learning methods, ours is a truly end-to-end trainable approach that extracts high-quality building footprints and road networks without requiring complicated, computationally intensive raster loss functions and intricate training pipelines. Upon evaluating Pix2Poly on several complex and challenging datasets, we report that Pix2Poly outperforms state-of-the-art methods in several vector shape quality metrics while being an entirely explicit method. Our code is available at https://github.com/yeshwanth95/Pix2Poly.
ShapeWords: Guiding Text-to-Image Synthesis with 3D Shape-Aware Prompts
Dec 03, 2024



We introduce ShapeWords, an approach for synthesizing images based on 3D shape guidance and text prompts. ShapeWords incorporates target 3D shape information within specialized tokens embedded together with the input text, effectively blending 3D shape awareness with textual context to guide the image synthesis process. Unlike conventional shape guidance methods that rely on depth maps restricted to fixed viewpoints and often overlook full 3D structure or textual context, ShapeWords generates diverse yet consistent images that reflect both the target shape's geometry and the textual description. Experimental results show that ShapeWords produces images that are more text-compliant, aesthetically plausible, while also maintaining 3D shape awareness.
GEM3D: GEnerative Medial Abstractions for 3D Shape Synthesis
Feb 26, 2024



We introduce GEM3D -- a new deep, topology-aware generative model of 3D shapes. The key ingredient of our method is a neural skeleton-based representation encoding information on both shape topology and geometry. Through a denoising diffusion probabilistic model, our method first generates skeleton-based representations following the Medial Axis Transform (MAT), then generates surfaces through a skeleton-driven neural implicit formulation. The neural implicit takes into account the topological and geometric information stored in the generated skeleton representations to yield surfaces that are more topologically and geometrically accurate compared to previous neural field formulations. We discuss applications of our method in shape synthesis and point cloud reconstruction tasks, and evaluate our method both qualitatively and quantitatively. We demonstrate significantly more faithful surface reconstruction and diverse shape generation results compared to the state-of-the-art, also involving challenging scenarios of reconstructing and synthesizing structurally complex, high-genus shape surfaces from Thingi10K and ShapeNet.
FacadeNet: Conditional Facade Synthesis via Selective Editing
Nov 03, 2023



We introduce FacadeNet, a deep learning approach for synthesizing building facade images from diverse viewpoints. Our method employs a conditional GAN, taking a single view of a facade along with the desired viewpoint information and generates an image of the facade from the distinct viewpoint. To precisely modify view-dependent elements like windows and doors while preserving the structure of view-independent components such as walls, we introduce a selective editing module. This module leverages image embeddings extracted from a pre-trained vision transformer. Our experiments demonstrated state-of-the-art performance on building facade generation, surpassing alternative methods.
Efficient Deduplication and Leakage Detection in Large Scale Image Datasets with a focus on the CrowdAI Mapping Challenge Dataset
Apr 05, 2023



Recent advancements in deep learning and computer vision have led to widespread use of deep neural networks to extract building footprints from remote-sensing imagery. The success of such methods relies on the availability of large databases of high-resolution remote sensing images with high-quality annotations. The CrowdAI Mapping Challenge Dataset is one of these datasets that has been used extensively in recent years to train deep neural networks. This dataset consists of $ \sim\ $280k training images and $ \sim\ $60k testing images, with polygonal building annotations for all images. However, issues such as low-quality and incorrect annotations, extensive duplication of image samples, and data leakage significantly reduce the utility of deep neural networks trained on the dataset. Therefore, it is an imperative pre-condition to adopt a data validation pipeline that evaluates the quality of the dataset prior to its use. To this end, we propose a drop-in pipeline that employs perceptual hashing techniques for efficient de-duplication of the dataset and identification of instances of data leakage between training and testing splits. In our experiments, we demonstrate that nearly 250k($ \sim\ $90%) images in the training split were identical. Moreover, our analysis on the validation split demonstrates that roughly 56k of the 60k images also appear in the training split, resulting in a data leakage of 93%. The source code used for the analysis and de-duplication of the CrowdAI Mapping Challenge dataset is publicly available at https://github.com/yeshwanth95/CrowdAI_Hash_and_search .
Projective Urban Texturing
Feb 04, 2022

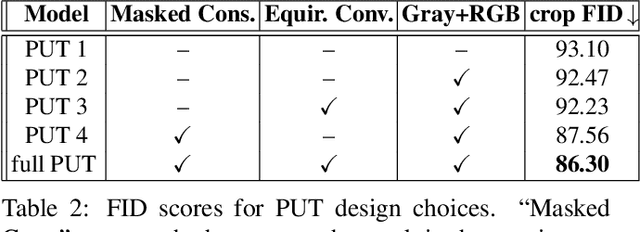

This paper proposes a method for automatic generation of textures for 3D city meshes in immersive urban environments. Many recent pipelines capture or synthesize large quantities of city geometry using scanners or procedural modeling pipelines. Such geometry is intricate and realistic, however the generation of photo-realistic textures for such large scenes remains a problem. We propose to generate textures for input target 3D meshes driven by the textural style present in readily available datasets of panoramic photos capturing urban environments. Re-targeting such 2D datasets to 3D geometry is challenging because the underlying shape, size, and layout of the urban structures in the photos do not correspond to the ones in the target meshes. Photos also often have objects (e.g., trees, vehicles) that may not even be present in the target geometry. To address these issues we present a method, called Projective Urban Texturing (PUT), which re-targets textural style from real-world panoramic images to unseen urban meshes. PUT relies on contrastive and adversarial training of a neural architecture designed for unpaired image-to-texture translation. The generated textures are stored in a texture atlas applied to the target 3D mesh geometry. To promote texture consistency, PUT employs an iterative procedure in which texture synthesis is conditioned on previously generated, adjacent textures. We demonstrate both quantitative and qualitative evaluation of the generated textures.
BuildingNet: Learning to Label 3D Buildings
Oct 11, 2021

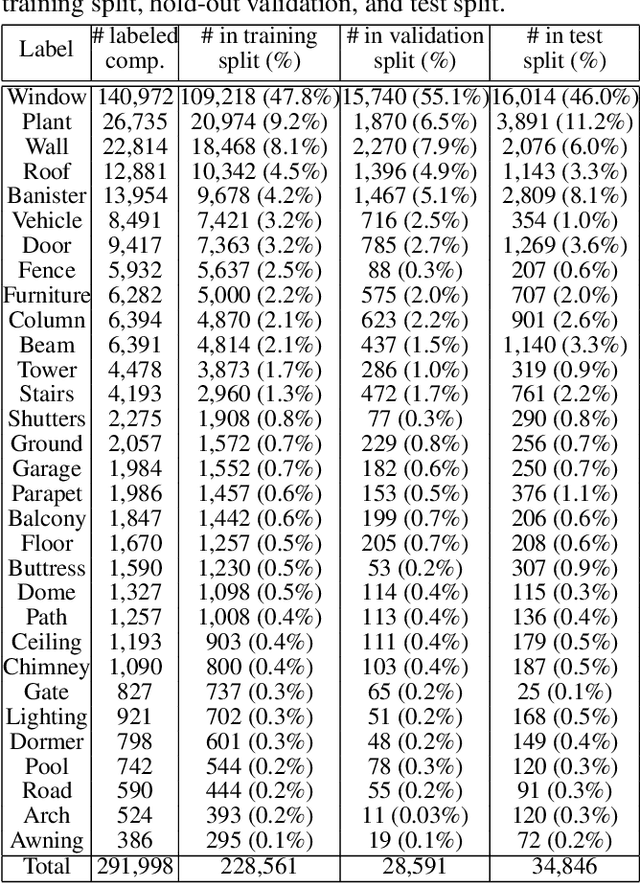
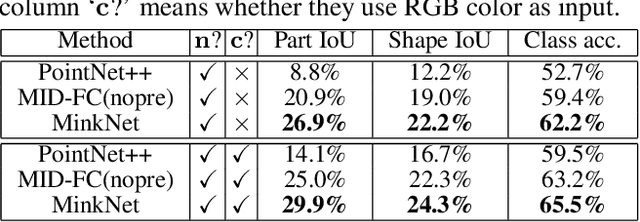
We introduce BuildingNet: (a) a large-scale dataset of 3D building models whose exteriors are consistently labeled, (b) a graph neural network that labels building meshes by analyzing spatial and structural relations of their geometric primitives. To create our dataset, we used crowdsourcing combined with expert guidance, resulting in 513K annotated mesh primitives, grouped into 292K semantic part components across 2K building models. The dataset covers several building categories, such as houses, churches, skyscrapers, town halls, libraries, and castles. We include a benchmark for evaluating mesh and point cloud labeling. Buildings have more challenging structural complexity compared to objects in existing benchmarks (e.g., ShapeNet, PartNet), thus, we hope that our dataset can nurture the development of algorithms that are able to cope with such large-scale geometric data for both vision and graphics tasks e.g., 3D semantic segmentation, part-based generative models, correspondences, texturing, and analysis of point cloud data acquired from real-world buildings. Finally, we show that our mesh-based graph neural network significantly improves performance over several baselines for labeling 3D meshes.
Learning Part Boundaries from 3D Point Clouds
Jul 15, 2020
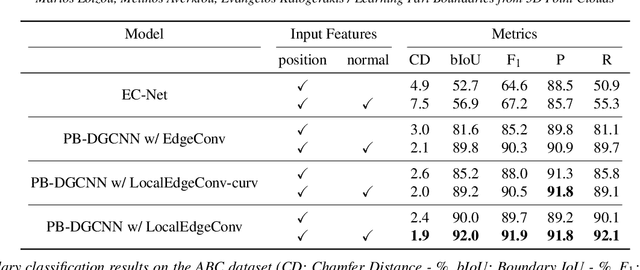
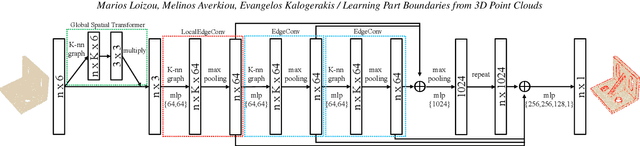

We present a method that detects boundaries of parts in 3D shapes represented as point clouds. Our method is based on a graph convolutional network architecture that outputs a probability for a point to lie in an area that separates two or more parts in a 3D shape. Our boundary detector is quite generic: it can be trained to localize boundaries of semantic parts or geometric primitives commonly used in 3D modeling. Our experiments demonstrate that our method can extract more accurate boundaries that are closer to ground-truth ones compared to alternatives. We also demonstrate an application of our network to fine-grained semantic shape segmentation, where we also show improvements in terms of part labeling performance.
Learning Material-Aware Local Descriptors for 3D Shapes
Oct 20, 2018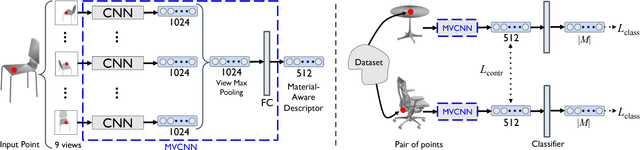
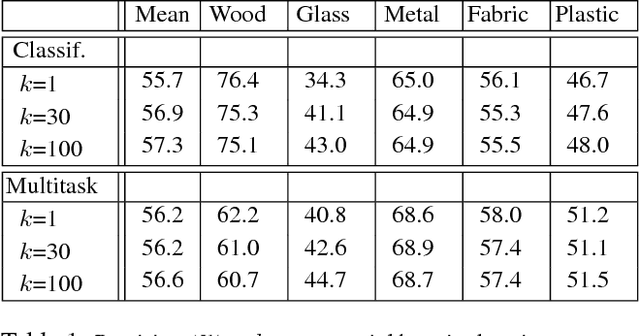
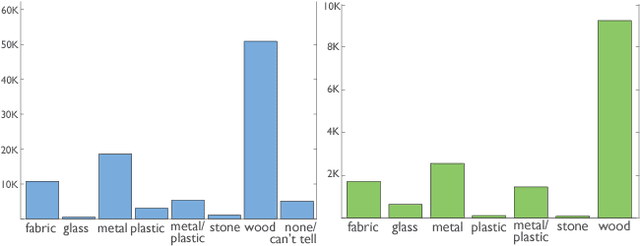
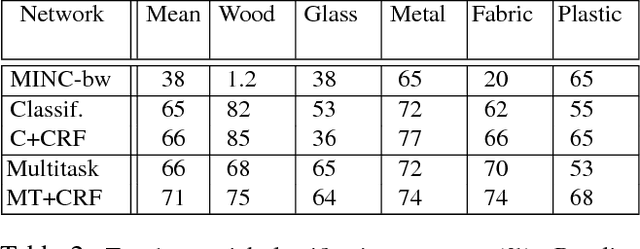
Material understanding is critical for design, geometric modeling, and analysis of functional objects. We enable material-aware 3D shape analysis by employing a projective convolutional neural network architecture to learn material- aware descriptors from view-based representations of 3D points for point-wise material classification or material- aware retrieval. Unfortunately, only a small fraction of shapes in 3D repositories are labeled with physical mate- rials, posing a challenge for learning methods. To address this challenge, we crowdsource a dataset of 3080 3D shapes with part-wise material labels. We focus on furniture models which exhibit interesting structure and material variabil- ity. In addition, we also contribute a high-quality expert- labeled benchmark of 115 shapes from Herman-Miller and IKEA for evaluation. We further apply a mesh-aware con- ditional random field, which incorporates rotational and reflective symmetries, to smooth our local material predic- tions across neighboring surface patches. We demonstrate the effectiveness of our learned descriptors for automatic texturing, material-aware retrieval, and physical simulation. The dataset and code will be publicly available.
3D Shape Segmentation with Projective Convolutional Networks
Nov 13, 2017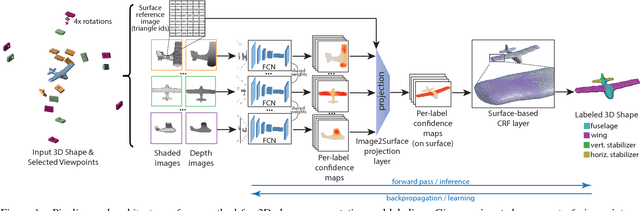

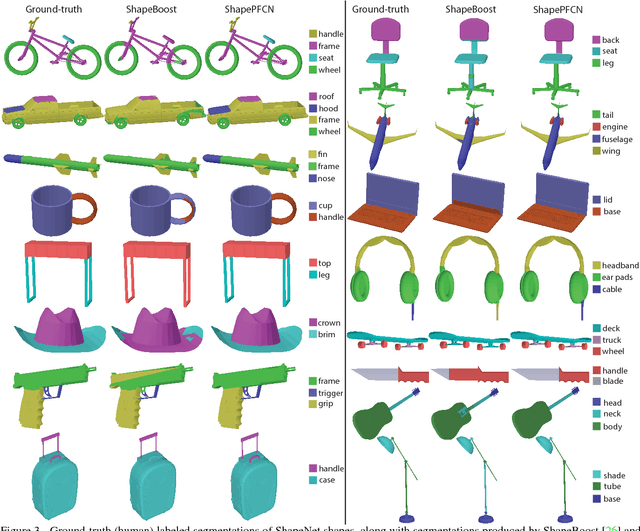
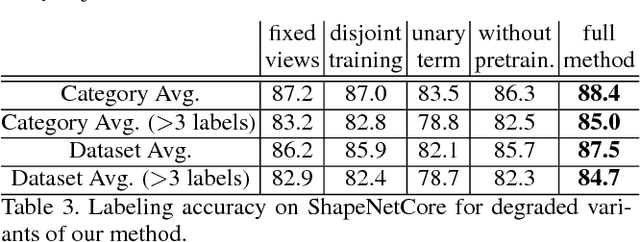
This paper introduces a deep architecture for segmenting 3D objects into their labeled semantic parts. Our architecture combines image-based Fully Convolutional Networks (FCNs) and surface-based Conditional Random Fields (CRFs) to yield coherent segmentations of 3D shapes. The image-based FCNs are used for efficient view-based reasoning about 3D object parts. Through a special projection layer, FCN outputs are effectively aggregated across multiple views and scales, then are projected onto the 3D object surfaces. Finally, a surface-based CRF combines the projected outputs with geometric consistency cues to yield coherent segmentations. The whole architecture (multi-view FCNs and CRF) is trained end-to-end. Our approach significantly outperforms the existing state-of-the-art methods in the currently largest segmentation benchmark (ShapeNet). Finally, we demonstrate promising segmentation results on noisy 3D shapes acquired from consumer-grade depth cameras.