 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacadeNet: Conditional Facade Synthesis via Selective Editing
Nov 03, 2023



We introduce FacadeNet, a deep learning approach for synthesizing building facade images from diverse viewpoints. Our method employs a conditional GAN, taking a single view of a facade along with the desired viewpoint information and generates an image of the facade from the distinct viewpoint. To precisely modify view-dependent elements like windows and doors while preserving the structure of view-independent components such as walls, we introduce a selective editing module. This module leverages image embeddings extracted from a pre-trained vision transformer. Our experiments demonstrated state-of-the-art performance on building facade generation, surpassing alternative methods.
SurFit: Learning to Fit Surfaces Improves Few Shot Learning on Point Clouds
Dec 27, 2021

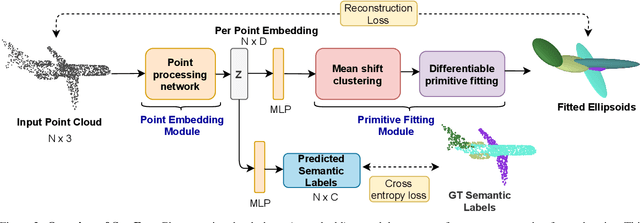
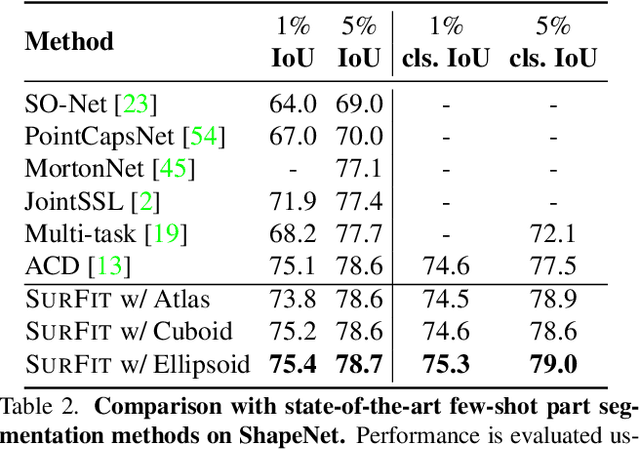
We present SurFit, a simple approach for label efficient learning of 3D shape segmentation networks. SurFit is based on a self-supervised task of decomposing the surface of a 3D shape into geometric primitives. It can be readily applied to existing network architectures for 3D shape segmentation and improves their performance in the few-shot setting, as we demonstrate in the widely used ShapeNet and PartNet benchmarks. SurFit outperforms the prior state-of-the-art in this setting, suggesting that decomposability into primitives is a useful prior for learning representations predictive of semantic parts. We present a number of experiments varying the choice of geometric primitives and downstream tasks to demonstrate the effectiveness of the method.
BuildingNet: Learning to Label 3D Buildings
Oct 11, 2021

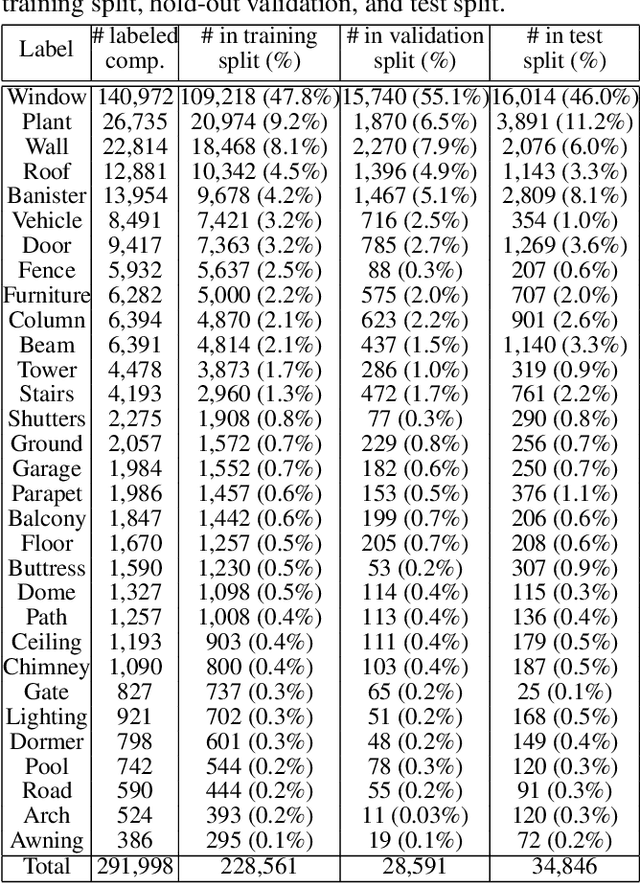
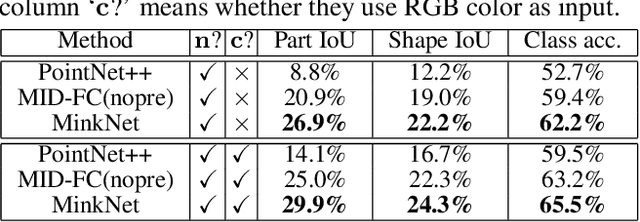
We introduce BuildingNet: (a) a large-scale dataset of 3D building models whose exteriors are consistently labeled, (b) a graph neural network that labels building meshes by analyzing spatial and structural relations of their geometric primitives. To create our dataset, we used crowdsourcing combined with expert guidance, resulting in 513K annotated mesh primitives, grouped into 292K semantic part components across 2K building models. The dataset covers several building categories, such as houses, churches, skyscrapers, town halls, libraries, and castles. We include a benchmark for evaluating mesh and point cloud labeling. Buildings have more challenging structural complexity compared to objects in existing benchmarks (e.g., ShapeNet, PartNet), thus, we hope that our dataset can nurture the development of algorithms that are able to cope with such large-scale geometric data for both vision and graphics tasks e.g., 3D semantic segmentation, part-based generative models, correspondences, texturing, and analysis of point cloud data acquired from real-world buildings. Finally, we show that our mesh-based graph neural network significantly improves performance over several baselines for labeling 3D meshes.
Learning Part Boundaries from 3D Point Clouds
Jul 15, 2020
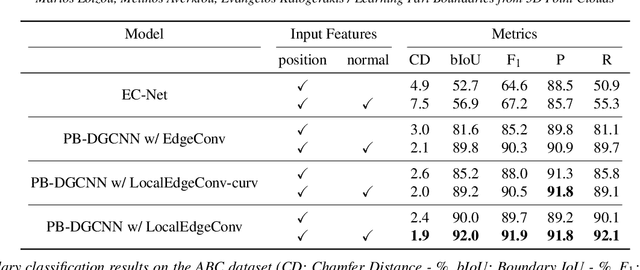
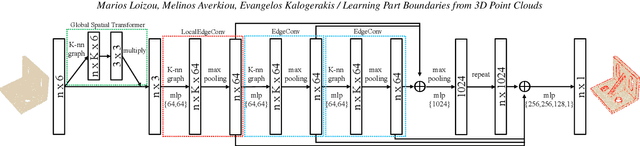

We present a method that detects boundaries of parts in 3D shapes represented as point clouds. Our method is based on a graph convolutional network architecture that outputs a probability for a point to lie in an area that separates two or more parts in a 3D shape. Our boundary detector is quite generic: it can be trained to localize boundaries of semantic parts or geometric primitives commonly used in 3D modeling. Our experiments demonstrate that our method can extract more accurate boundaries that are closer to ground-truth ones compared to alternatives. We also demonstrate an application of our network to fine-grained semantic shape segmentation, where we also show improvements in terms of part labeling performance.