 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Deduplication and Leakage Detection in Large Scale Image Datasets with a focus on the CrowdAI Mapping Challenge Dataset
Apr 05, 2023



Recent advancements in deep learning and computer vision have led to widespread use of deep neural networks to extract building footprints from remote-sensing imagery. The success of such methods relies on the availability of large databases of high-resolution remote sensing images with high-quality annotations. The CrowdAI Mapping Challenge Dataset is one of these datasets that has been used extensively in recent years to train deep neural networks. This dataset consists of $ \sim\ $280k training images and $ \sim\ $60k testing images, with polygonal building annotations for all images. However, issues such as low-quality and incorrect annotations, extensive duplication of image samples, and data leakage significantly reduce the utility of deep neural networks trained on the dataset. Therefore, it is an imperative pre-condition to adopt a data validation pipeline that evaluates the quality of the dataset prior to its use. To this end, we propose a drop-in pipeline that employs perceptual hashing techniques for efficient de-duplication of the dataset and identification of instances of data leakage between training and testing splits. In our experiments, we demonstrate that nearly 250k($ \sim\ $90%) images in the training split were identical. Moreover, our analysis on the validation split demonstrates that roughly 56k of the 60k images also appear in the training split, resulting in a data leakage of 93%. The source code used for the analysis and de-duplication of the CrowdAI Mapping Challenge dataset is publicly available at https://github.com/yeshwanth95/CrowdAI_Hash_and_search .
Semantic Segmentation from Remote Sensor Data and the Exploitation of Latent Learning for Classification of Auxiliary Tasks
Dec 19, 2019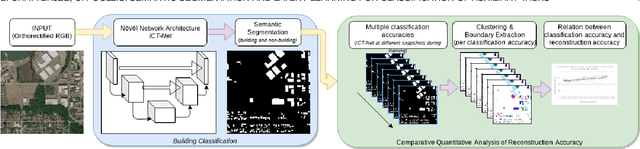

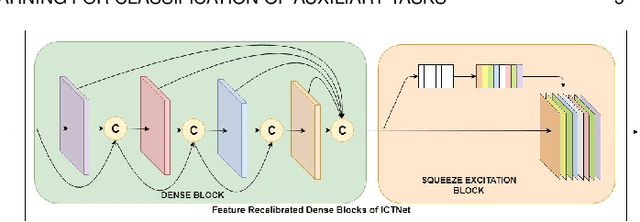

In this paper we address three different aspects of semantic segmentation from remote sensor data using deep neural networks. Firstly, we focus on the semantic segmentation of buildings from remote sensor data and propose ICT-Net. The proposed network has been tested on the INRIA and AIRS benchmark datasets and is shown to outperform all other state of the art by more than 1.5% and 1.8% on the Jaccard index, respectively. Secondly, as the building classification is typically the first step of the reconstruction process, we investigate the relationship of the classification accuracy to the reconstruction accuracy. Finally, we present the simple yet compelling concept of latent learning and the implications it carries within the context of deep learning. We posit that a network trained on a primary task (i.e. building classification) is unintentionally learning about auxiliary tasks (e.g. the classification of road, tree, etc) which are complementary to the primary task. We extensively tested the proposed technique on the ISPRS benchmark dataset which contains multi-label ground truth, and report an average classification accuracy (F1 score) of 54.29% (SD=17.03) for roads, 10.15% (SD=2.54) for cars, 24.11% (SD=5.25) for trees, 42.74% (SD=6.62) for low vegetation, and 18.30% (SD=16.08) for clutter. The source code and supplemental material is publicly available at http://www.theICTlab.org/lp/2019ICT-Net/.