 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Fatigue-Aware VR Interfaces via Biomechanical Models
Mar 27, 2026Prolonged mid-air interaction in virtual reality (VR) causes arm fatigue and discomfort, negatively affecting user experience. Incorporating ergonomic considerations into VR user interface (UI) design typically requires extensive human-in-the-loop evaluation. Although biomechanical models have been used to simulate human behavior in HCI tasks, their application as surrogate users for ergonomic VR UI design remains underexplored. We propose a hierarchical reinforcement learning framework that leverages biomechanical user models to evaluate and optimize VR interfaces for mid-air interaction. A motion agent is trained to perform button-press tasks in VR under sequential conditions, using realistic movement strategies and estimating muscle-level effort via a validated three-compartment control with recovery (3CC-r) fatigue model. The simulated fatigue output serves as feedback for a UI agent that optimizes UI element layout via reinforcement learning (RL) to minimize fatigue. We compare the RL-optimized layout against a manually-designed centered baseline and a Bayesian optimized baseline. Results show that fatigue trends from the biomechanical model align with human user data. Moreover, the RL-optimized layout using simulated fatigue feedback produced significantly lower perceived fatigue in a follow-up human study. We further demonstrate the framework's extensibility via a simulated case study on longer sequential tasks with non-uniform interaction frequencies. To our knowledge, this is the first work using simulated biomechanical muscle fatigue as a direct optimization signal for VR UI layout design. Our findings highlight the potential of biomechanical user models as effective surrogate tools for ergonomic VR interface design, enabling efficient early-stage iteration with less reliance on extensive human participation.
Distill3R: A Pipeline for Democratizing 3D Foundation Models on Commodity Hardware
Jan 31, 2026While multi-view 3D reconstruction has shifted toward large-scale foundation models capable of inferring globally consistent geometry, their reliance on massive computational clusters for training has created a significant barrier to entry for most academic laboratories. To bridge this compute divide, we introduce Distill3R, a framework designed to distill the geometric reasoning of 3D foundation models into compact students fully trainable on a single workstation. Our methodology centers on two primary innovations: (1) an offline caching pipeline that decouples heavy teacher inference from the training loop through compressed supervision signals, and (2) a confidence-aware distillation loss that leverages teacher uncertainty to enable training on commodity hardware. We propose a 72M-parameter student model which achieves a 9x reduction in parameters and a 5x inference speedup compared to its 650M-parameter teacher. The student is fully trainable in under 3 days on a single workstation, whereas its teacher requires massive GPU clusters for up to a week. We demonstrate that the student preserves the structural consistency and qualitative geometric understanding required for functional 3D awareness. By providing a reproducible, single-workstation training recipe, Distill3R serves as an exploratory entry point for democratized 3D vision research and efficient edge deployment. This work is not intended to compete with state-of-the-art foundation models, but to provide an accessible research baseline for laboratories without access to large-scale compute to train and specialize models on their own domain-specific data at minimal cost.
DSV-LFS: Unifying LLM-Driven Semantic Cues with Visual Features for Robust Few-Shot Segmentation
Mar 06, 2025Few-shot semantic segmentation (FSS) aims to enable models to segment novel/unseen object classes using only a limited number of labeled examples. However, current FSS methods frequently struggle with generalization due to incomplete and biased feature representations, especially when support images do not capture the full appearance variability of the target class. To improve the FSS pipeline, we propose a novel framework that utilizes large language models (LLMs) to adapt general class semantic information to the query image. Furthermore, the framework employs dense pixel-wise matching to identify similarities between query and support images, resulting in enhanced FSS performance. Inspired by reasoning-based segmentation frameworks, our method, named DSV-LFS, introduces an additional token into the LLM vocabulary, allowing a multimodal LLM to generate a "semantic prompt" from class descriptions. In parallel, a dense matching module identifies visual similarities between the query and support images, generating a "visual prompt". These prompts are then jointly employed to guide the prompt-based decoder for accurate segmentation of the query image. Comprehensive experiments on the benchmark datasets Pascal-$5^{i}$ and COCO-$20^{i}$ demonstrate that our framework achieves state-of-the-art performance-by a significant margin-demonstrating superior generalization to novel classes and robustness across diverse scenarios. The source code is available at \href{https://github.com/aminpdik/DSV-LFS}{https://github.com/aminpdik/DSV-LFS}
Pix2Poly: A Sequence Prediction Method for End-to-end Polygonal Building Footprint Extraction from Remote Sensing Imagery
Dec 10, 2024



Extraction of building footprint polygons from remotely sensed data is essential for several urban understanding tasks such as reconstruction, navigation, and mapping. Despite significant progress in the area, extracting accurate polygonal building footprints remains an open problem. In this paper, we introduce Pix2Poly, an attention-based end-to-end trainable and differentiable deep neural network capable of directly generating explicit high-quality building footprints in a ring graph format. Pix2Poly employs a generative encoder-decoder transformer to produce a sequence of graph vertex tokens whose connectivity information is learned by an optimal matching network. Compared to previous graph learning methods, ours is a truly end-to-end trainable approach that extracts high-quality building footprints and road networks without requiring complicated, computationally intensive raster loss functions and intricate training pipelines. Upon evaluating Pix2Poly on several complex and challenging datasets, we report that Pix2Poly outperforms state-of-the-art methods in several vector shape quality metrics while being an entirely explicit method. Our code is available at https://github.com/yeshwanth95/Pix2Poly.
Neural Real-Time Recalibration for Infrared Multi-Camera Systems
Oct 18, 2024



Currently, there are no learning-free or neural techniques for real-time recalibration of infrared multi-camera systems. In this paper, we address the challenge of real-time, highly-accurate calibration of multi-camera infrared systems, a critical task for time-sensitive applications. Unlike traditional calibration techniques that lack adaptability and struggle with on-the-fly recalibrations, we propose a neural network-based method capable of dynamic real-time calibration. The proposed method integrates a differentiable projection model that directly correlates 3D geometries with their 2D image projections and facilitates the direct optimization of both intrinsic and extrinsic camera parameters. Key to our approach is the dynamic camera pose synthesis with perturbations in camera parameters, emulating realistic operational challenges to enhance model robustness. We introduce two model variants: one designed for multi-camera systems with onboard processing of 2D points, utilizing the direct 2D projections of 3D fiducials, and another for image-based systems, employing color-coded projected points for implicitly establishing correspondence. Through rigorous experimentation, we demonstrate our method is more accurate than traditional calibration techniques with or without perturbations while also being real-time, marking a significant leap in the field of real-time multi-camera system calibration. The source code can be found at https://github.com/theICTlab/neural-recalibration
TransGlow: Attention-augmented Transduction model based on Graph Neural Networks for Water Flow Forecasting
Dec 10, 2023



The hydrometric prediction of water quantity is useful for a variety of applications, including water management, flood forecasting, and flood control. However, the task is difficult due to the dynamic nature and limited data of water systems. Highly interconnected water systems can significantly affect hydrometric forecasting. Consequently, it is crucial to develop models that represent the relationships between other system components. In recent years, numerous hydrological applications have been studied, including streamflow prediction, flood forecasting, and water quality prediction. Existing methods are unable to model the influence of adjacent regions between pairs of variables. In this paper, we propose a spatiotemporal forecasting model that augments the hidden state in Graph Convolution Recurrent Neural Network (GCRN) encoder-decoder using an efficient version of the attention mechanism. The attention layer allows the decoder to access different parts of the input sequence selectively. Since water systems are interconnected and the connectivity information between the stations is implicit, the proposed model leverages a graph learning module to extract a sparse graph adjacency matrix adaptively based on the data. Spatiotemporal forecasting relies on historical data. In some regions, however, historical data may be limited or incomplete, making it difficult to accurately predict future water conditions. Further, we present a new benchmark dataset of water flow from a network of Canadian stations on rivers, streams, and lakes. Experimental results demonstrate that our proposed model TransGlow significantly outperforms baseline methods by a wide margin.
Efficient Deduplication and Leakage Detection in Large Scale Image Datasets with a focus on the CrowdAI Mapping Challenge Dataset
Apr 05, 2023



Recent advancements in deep learning and computer vision have led to widespread use of deep neural networks to extract building footprints from remote-sensing imagery. The success of such methods relies on the availability of large databases of high-resolution remote sensing images with high-quality annotations. The CrowdAI Mapping Challenge Dataset is one of these datasets that has been used extensively in recent years to train deep neural networks. This dataset consists of $ \sim\ $280k training images and $ \sim\ $60k testing images, with polygonal building annotations for all images. However, issues such as low-quality and incorrect annotations, extensive duplication of image samples, and data leakage significantly reduce the utility of deep neural networks trained on the dataset. Therefore, it is an imperative pre-condition to adopt a data validation pipeline that evaluates the quality of the dataset prior to its use. To this end, we propose a drop-in pipeline that employs perceptual hashing techniques for efficient de-duplication of the dataset and identification of instances of data leakage between training and testing splits. In our experiments, we demonstrate that nearly 250k($ \sim\ $90%) images in the training split were identical. Moreover, our analysis on the validation split demonstrates that roughly 56k of the 60k images also appear in the training split, resulting in a data leakage of 93%. The source code used for the analysis and de-duplication of the CrowdAI Mapping Challenge dataset is publicly available at https://github.com/yeshwanth95/CrowdAI_Hash_and_search .
End-to-End Multi-View Structure-from-Motion with Hypercorrelation Volumes
Sep 14, 2022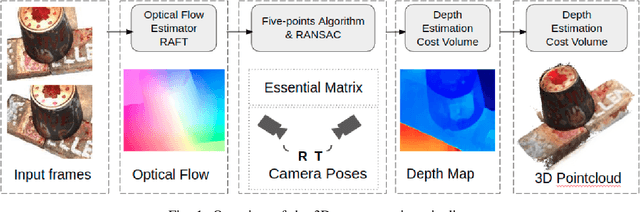


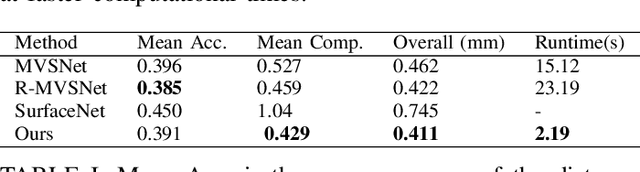
Image-based 3D reconstruction is one of the most important tasks in Computer Vision with many solutions proposed over the last few decades. The objective is to extract metric information i.e. the geometry of scene objects directly from images. These can then be used in a wide range of applications such as film, games, virtual reality, etc. Recently, deep learning techniques have been proposed to tackle this problem. They rely on training on vast amounts of data to learn to associate features between images through deep convolutional neural networks and have been shown to outperform traditional procedural techniques. In this paper, we improve on the state-of-the-art two-view structure-from-motion(SfM) approach of [11] by incorporating 4D correlation volume for more accurate feature matching and reconstruction. Furthermore, we extend it to the general multi-view case and evaluate it on the complex benchmark dataset DTU [4]. Quantitative evaluations and comparisons with state-of-the-art multi-view 3D reconstruction methods demonstrate its superiority in terms of the accuracy of reconstructions.
Simpler is better: Multilevel Abstraction with Graph Convolutional Recurrent Neural Network Cells for Traffic Prediction
Sep 08, 2022
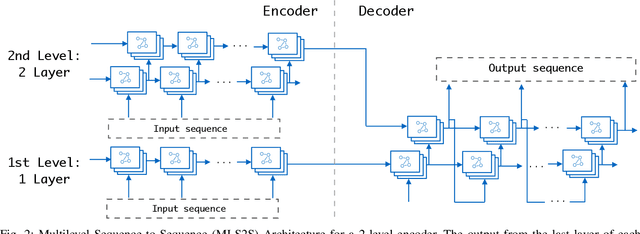
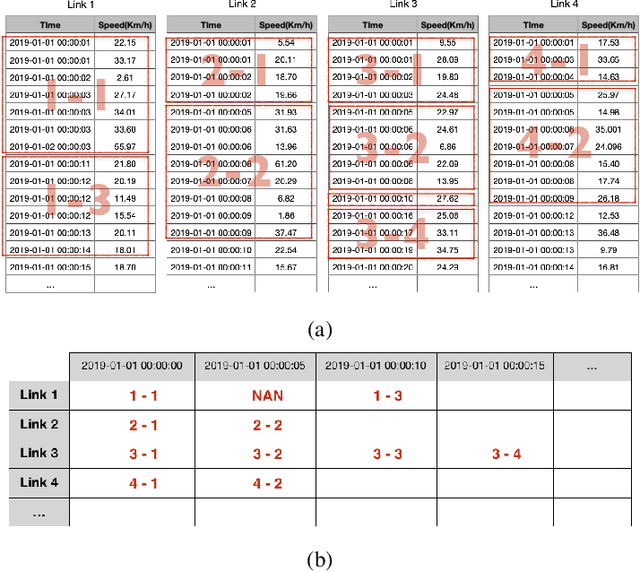
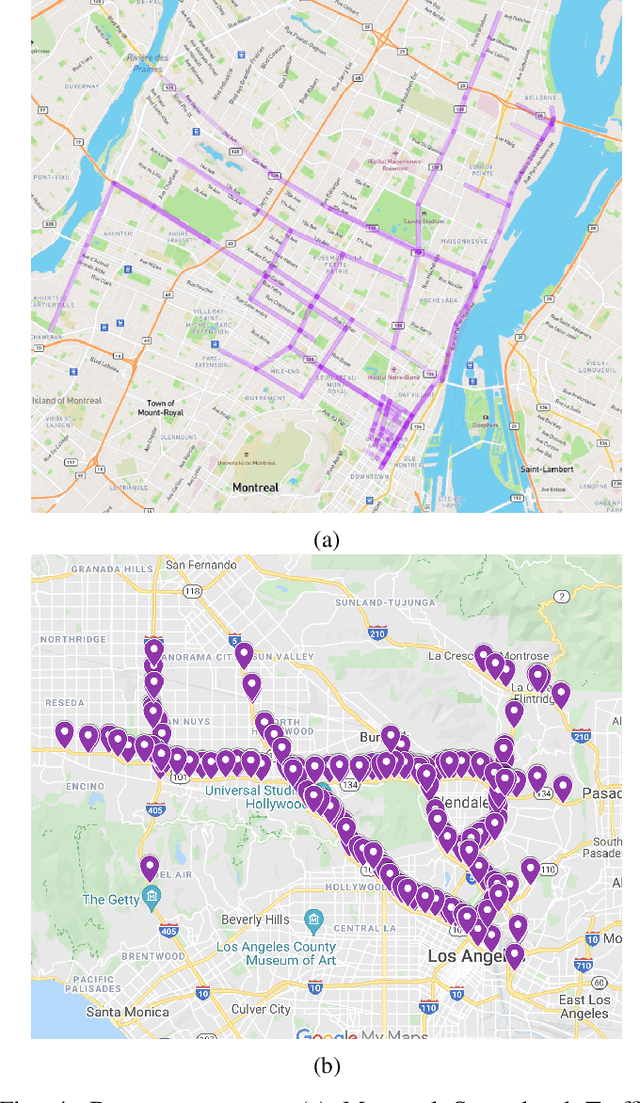
In recent years, graph neural networks (GNNs) combined with variants of recurrent neural networks (RNNs) have reached state-of-the-art performance in spatiotemporal forecasting tasks. This is particularly the case for traffic forecasting, where GNN models use the graph structure of road networks to account for spatial correlation between links and nodes. Recent solutions are either based on complex graph operations or avoiding predefined graphs. This paper proposes a new sequence-to-sequence architecture to extract the spatiotemporal correlation at multiple levels of abstraction using GNN-RNN cells with sparse architecture to decrease training time compared to more complex designs. Encoding the same input sequence through multiple encoders, with an incremental increase in encoder layers, enables the network to learn general and detailed information through multilevel abstraction. We further present a new benchmark dataset of street-level segment traffic data from Montreal, Canada. Unlike highways, urban road segments are cyclic and characterized by complicated spatial dependencies. Experimental results on the METR-LA benchmark highway and our MSLTD street-level segment datasets demonstrate that our model improves performance by more than 7% for one-hour prediction compared to the baseline methods while reducing computing resource requirements by more than half compared to other competing methods.
Unsupervised Structure-Consistent Image-to-Image Translation
Aug 24, 2022
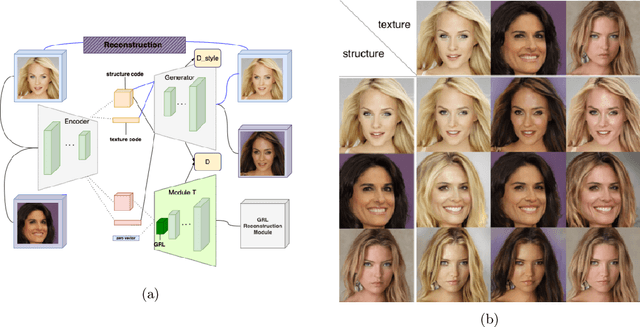


The Swapping Autoencoder achieved state-of-the-art performance in deep image manipulation and image-to-image translation. We improve this work by introducing a simple yet effective auxiliary module based on gradient reversal layers. The auxiliary module's loss forces the generator to learn to reconstruct an image with an all-zero texture code, encouraging better disentanglement between the structure and texture information. The proposed attribute-based transfer method enables refined control in style transfer while preserving structural information without using a semantic mask. To manipulate an image, we encode both the geometry of the objects and the general style of the input images into two latent codes with an additional constraint that enforces structure consistency. Moreover, due to the auxiliary loss, training time is significantly reduced. The superiority of the proposed model is demonstrated in complex domains such as satellite images where state-of-the-art are known to fail. Lastly, we show that our model improves the quality metrics for a wide range of datasets while achieving comparable results with multi-modal image generation techniques.