 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Knowledge Decomposition based Online Distillation for Biomarker Prediction in Breast Cancer Histopathology
Aug 24, 2025Immunohistochemical (IHC) biomarker prediction benefits from multi-modal data fusion analysis. However, the simultaneous acquisition of multi-modal data, such as genomic and pathological information, is often challenging due to cost or technical limitations. To address this challenge, we propose an online distillation approach based on Multi-modal Knowledge Decomposition (MKD) to enhance IHC biomarker prediction in haematoxylin and eosin (H\&E) stained histopathology images. This method leverages paired genomic-pathology data during training while enabling inference using either pathology slides alone or both modalities. Two teacher and one student models are developed to extract modality-specific and modality-general features by minimizing the MKD loss. To maintain the internal structural relationships between samples, Similarity-preserving Knowledge Distillation (SKD) is applied. Additionally, Collaborative Learning for Online Distillation (CLOD) facilitates mutual learning between teacher and student models, encouraging diverse and complementary learning dynamics. Experiments on the TCGA-BRCA and in-house QHSU datasets demonstrate that our approach achieves superior performance in IHC biomarker prediction using uni-modal data. Our code is available at https://github.com/qiyuanzz/MICCAI2025_MKD.
Coupled Input-Output Dimension Reduction: Application to Goal-oriented Bayesian Experimental Design and Global Sensitivity Analysis
Jun 19, 2024We introduce a new method to jointly reduce the dimension of the input and output space of a high-dimensional function. Choosing a reduced input subspace influences which output subspace is relevant and vice versa. Conventional methods focus on reducing either the input or output space, even though both are often reduced simultaneously in practice. Our coupled approach naturally supports goal-oriented dimension reduction, where either an input or output quantity of interest is prescribed. We consider, in particular, goal-oriented sensor placement and goal-oriented sensitivity analysis, which can be viewed as dimension reduction where the most important output or, respectively, input components are chosen. Both applications present difficult combinatorial optimization problems with expensive objectives such as the expected information gain and Sobol indices. By optimizing gradient-based bounds, we can determine the most informative sensors and most sensitive parameters as the largest diagonal entries of some diagnostic matrices, thus bypassing the combinatorial optimization and objective evaluation.
End-to-End Multi-View Structure-from-Motion with Hypercorrelation Volumes
Sep 14, 2022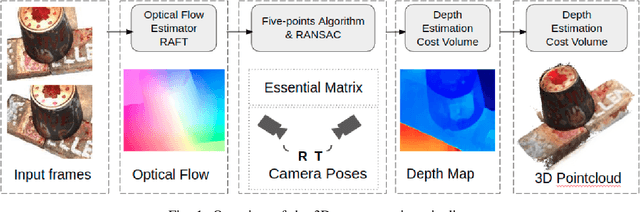


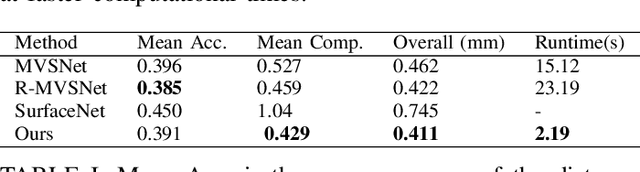
Image-based 3D reconstruction is one of the most important tasks in Computer Vision with many solutions proposed over the last few decades. The objective is to extract metric information i.e. the geometry of scene objects directly from images. These can then be used in a wide range of applications such as film, games, virtual reality, etc. Recently, deep learning techniques have been proposed to tackle this problem. They rely on training on vast amounts of data to learn to associate features between images through deep convolutional neural networks and have been shown to outperform traditional procedural techniques. In this paper, we improve on the state-of-the-art two-view structure-from-motion(SfM) approach of [11] by incorporating 4D correlation volume for more accurate feature matching and reconstruction. Furthermore, we extend it to the general multi-view case and evaluate it on the complex benchmark dataset DTU [4]. Quantitative evaluations and comparisons with state-of-the-art multi-view 3D reconstruction methods demonstrate its superiority in terms of the accuracy of reconstructions.
Motion Estimation for Large Displacements and Deformations
Jun 24, 2022



Large displacement optical flow is an integral part of many computer vision tasks. Variational optical flow techniques based on a coarse-to-fine scheme interpolate sparse matches and locally optimize an energy model conditioned on colour, gradient and smoothness, making them sensitive to noise in the sparse matches, deformations, and arbitrarily large displacements. This paper addresses this problem and presents HybridFlow, a variational motion estimation framework for large displacements and deformations. A multi-scale hybrid matching approach is performed on the image pairs. Coarse-scale clusters formed by classifying pixels according to their feature descriptors are matched using the clusters' context descriptors. We apply a multi-scale graph matching on the finer-scale superpixels contained within each matched pair of coarse-scale clusters. Small clusters that cannot be further subdivided are matched using localized feature matching. Together, these initial matches form the flow, which is propagated by an edge-preserving interpolation and variational refinement. Our approach does not require training and is robust to substantial displacements and rigid and non-rigid transformations due to motion in the scene, making it ideal for large-scale imagery such as Wide-Area Motion Imagery (WAMI). More notably, HybridFlow works on directed graphs of arbitrary topology representing perceptual groups, which improves motion estimation in the presence of significant deformations. We demonstrate HybridFlow's superior performance to state-of-the-art variational techniques on two benchmark datasets and report comparable results with state-of-the-art deep-learning-based techniques.