 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Planning in Interactive Environments via Iterative Policy Updates and Adversarially Robust Conformal Prediction
Nov 13, 2025Safe planning of an autonomous agent in interactive environments -- such as the control of a self-driving vehicle among pedestrians and human-controlled vehicles -- poses a major challenge as the behavior of the environment is unknown and reactive to the behavior of the autonomous agent. This coupling gives rise to interaction-driven distribution shifts where the autonomous agent's control policy may change the environment's behavior, thereby invalidating safety guarantees in existing work. Indeed, recent works have used conformal prediction (CP) to generate distribution-free safety guarantees using observed data of the environment. However, CP's assumption on data exchangeability is violated in interactive settings due to a circular dependency where a control policy update changes the environment's behavior, and vice versa. To address this gap, we propose an iterative framework that robustly maintains safety guarantees across policy updates by quantifying the potential impact of a planned policy update on the environment's behavior. We realize this via adversarially robust CP where we perform a regular CP step in each episode using observed data under the current policy, but then transfer safety guarantees across policy updates by analytically adjusting the CP result to account for distribution shifts. This adjustment is performed based on a policy-to-trajectory sensitivity analysis, resulting in a safe, episodic open-loop planner. We further conduct a contraction analysis of the system providing conditions under which both the CP results and the policy updates are guaranteed to converge. We empirically demonstrate these safety and convergence guarantees on a two-dimensional car-pedestrian case study. To the best of our knowledge, these are the first results that provide valid safety guarantees in such interactive settings.
Strategic Usage in a Multi-Learner Setting
Jan 29, 2024Real-world systems often involve some pool of users choosing between a set of services. With the increase in popularity of online learning algorithms, these services can now self-optimize, leveraging data collected on users to maximize some reward such as service quality. On the flipside, users may strategically choose which services to use in order to pursue their own reward functions, in the process wielding power over which services can see and use their data. Extensive prior research has been conducted on the effects of strategic users in single-service settings, with strategic behavior manifesting in the manipulation of observable features to achieve a desired classification; however, this can often be costly or unattainable for users and fails to capture the full behavior of multi-service dynamic systems. As such, we analyze a setting in which strategic users choose among several available services in order to pursue positive classifications, while services seek to minimize loss functions on their observations. We focus our analysis on realizable settings, and show that naive retraining can still lead to oscillation even if all users are observed at different times; however, if this retraining uses memory of past observations, convergent behavior can be guaranteed for certain loss function classes. We provide results obtained from synthetic and real-world data to empirically validate our theoretical findings.
Latent Diffusion for Language Generation
Dec 19, 2022



Diffusion models have achieved great success in modeling continuous data modalities such as images, audio, and video, but have seen limited use in discrete domains such as language. Recent attempts to adapt diffusion to language have presented diffusion as an alternative to autoregressive language generation. We instead view diffusion as a complementary method that can augment the generative capabilities of existing pre-trained language models. We demonstrate that continuous diffusion models can be learned in the latent space of a pre-trained encoder-decoder model, enabling us to sample continuous latent representations that can be decoded into natural language with the pre-trained decoder. We show that our latent diffusion models are more effective at sampling novel text from data distributions than a strong autoregressive baseline and also enable controllable generation.
Online Missing Value Imputation and Correlation Change Detection for Mixed-type Data via Gaussian Copula
Sep 25, 2020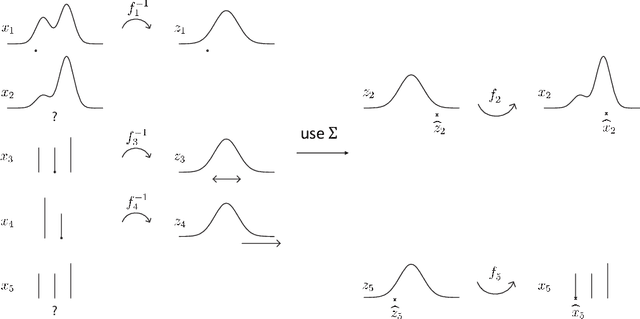
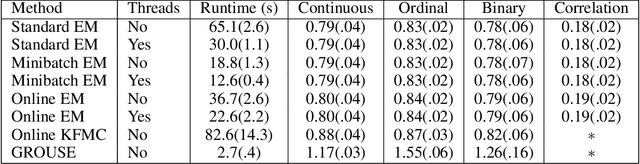
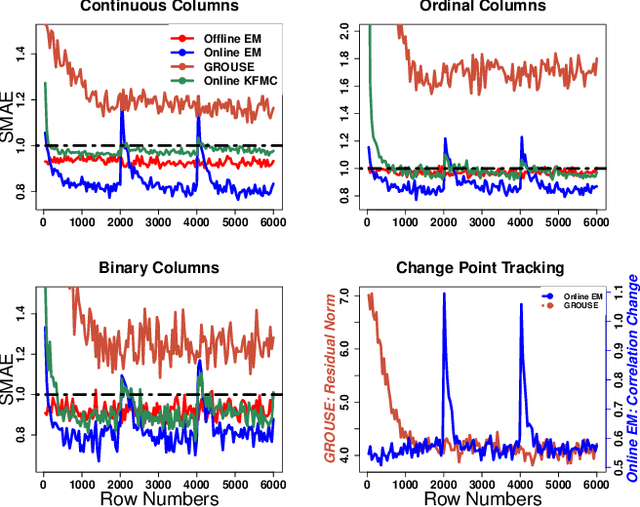
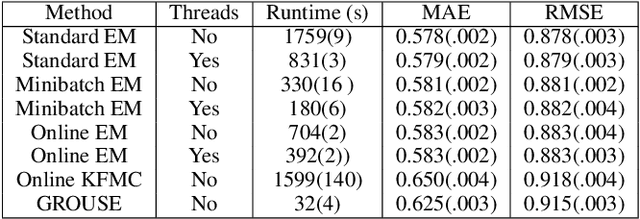
Most data science algorithms require complete observations, yet many datasets contain missing values. Hence missing value imputation is crucial for real-world data science workflows. For practical applications, imputation algorithms should produce imputations that match the true data distribution, handle mixed data containing ordinal, boolean, and continuous variables, and scale to large datasets. In this work we develop a new online imputation algorithm for mixed data using the Gaussian copula. The online Gaussian copula model produces meets all the desiderata: its imputations match the data distribution even for mixed data, and it scales well, achieving up to an order of magnitude speedup over its offline counterpart. The online algorithm can handle streaming or sequential data and can adapt to a changing data distribution. By fitting the copula model to online data, we also provide a new method to detect a change in the correlational structure of multivariate mixed data with missing values. Experimental results on synthetic and real world data validate the performance of the proposed methods.