 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Knowledge Graph Completion with Stacked Convolutions and a Student Re-Ranking Network
Jun 11, 2021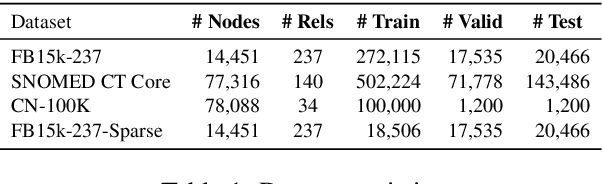
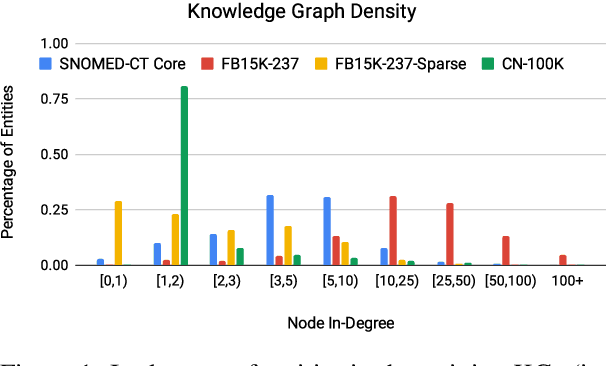
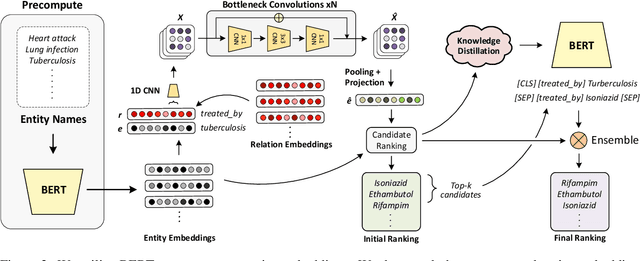

Knowledge Graph (KG) completion research usually focuses on densely connected benchmark datasets that are not representative of real KGs. We curate two KG datasets that include biomedical and encyclopedic knowledge and use an existing commonsense KG dataset to explore KG completion in the more realistic setting where dense connectivity is not guaranteed. We develop a deep convolutional network that utilizes textual entity representations and demonstrate that our model outperforms recent KG completion methods in this challenging setting. We find that our model's performance improvements stem primarily from its robustness to sparsity. We then distill the knowledge from the convolutional network into a student network that re-ranks promising candidate entities. This re-ranking stage leads to further improvements in performance and demonstrates the effectiveness of entity re-ranking for KG completion.
Translational NLP: A New Paradigm and General Principles for Natural Language Processing Research
Apr 16, 2021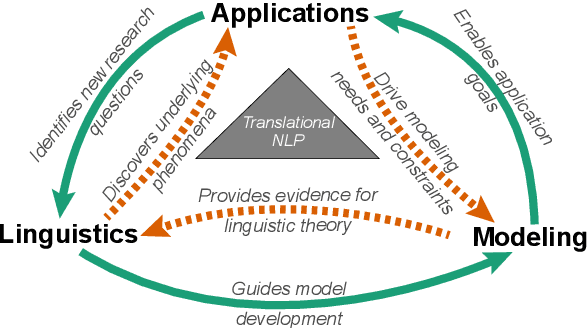

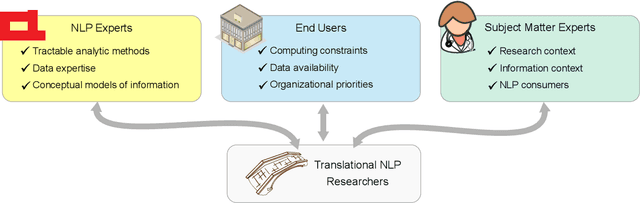
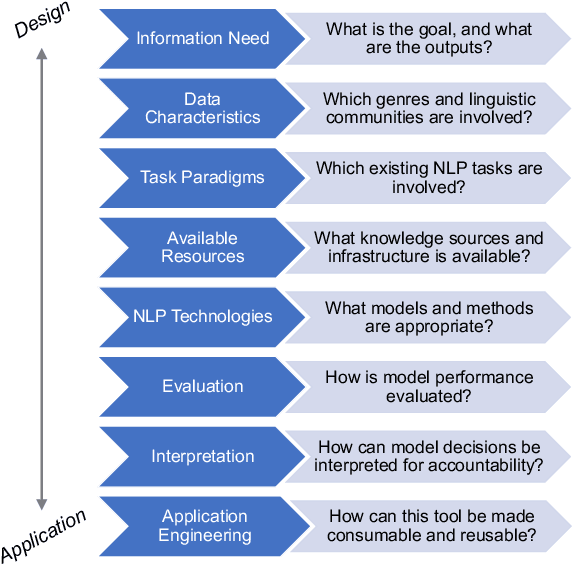
Natural language processing (NLP) research combines the study of universal principles, through basic science, with applied science targeting specific use cases and settings. However, the process of exchange between basic NLP and applications is often assumed to emerge naturally, resulting in many innovations going unapplied and many important questions left unstudied. We describe a new paradigm of Translational NLP, which aims to structure and facilitate the processes by which basic and applied NLP research inform one another. Translational NLP thus presents a third research paradigm, focused on understanding the challenges posed by application needs and how these challenges can drive innovation in basic science and technology design. We show that many significant advances in NLP research have emerged from the intersection of basic principles with application needs, and present a conceptual framework outlining the stakeholders and key questions in translational research. Our framework provides a roadmap for developing Translational NLP as a dedicated research area, and identifies general translational principles to facilitate exchange between basic and applied research.
MedFilter: Improving Extraction of Task-relevant Utterances through Integration of Discourse Structure and Ontological Knowledge
Oct 07, 2020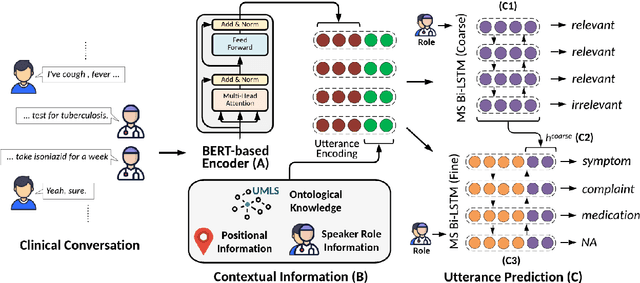
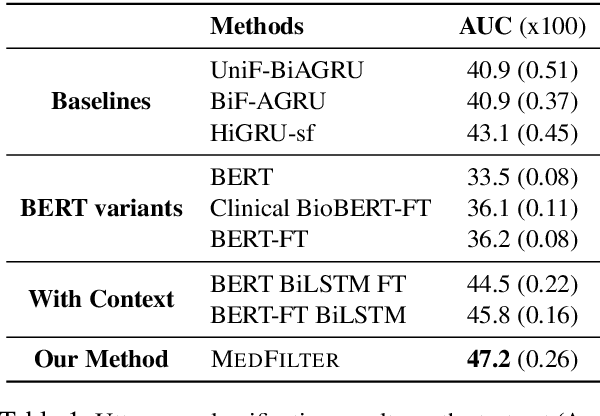
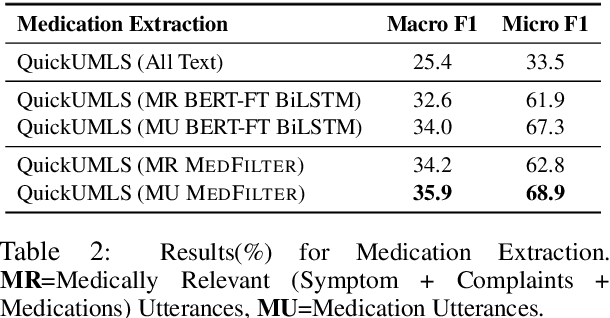
Information extraction from conversational data is particularly challenging because the task-centric nature of conversation allows for effective communication of implicit information by humans, but is challenging for machines. The challenges may differ between utterances depending on the role of the speaker within the conversation, especially when relevant expertise is distributed asymmetrically across roles. Further, the challenges may also increase over the conversation as more shared context is built up through information communicated implicitly earlier in the dialogue. In this paper, we propose the novel modeling approach MedFilter, which addresses these insights in order to increase performance at identifying and categorizing task-relevant utterances, and in so doing, positively impacts performance at a downstream information extraction task. We evaluate this approach on a corpus of nearly 7,000 doctor-patient conversations where MedFilter is used to identify medically relevant contributions to the discussion (achieving a 10% improvement over SOTA baselines in terms of area under the PR curve). Identifying task-relevant utterances benefits downstream medical processing, achieving improvements of 15%, 105%, and 23% respectively for the extraction of symptoms, medications, and complaints.