 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartEditBench: Evaluating Grounded Multi-Turn Chart Editing in Multimodal Language Models
Feb 17, 2026While Multimodal Large Language Models (MLLMs) perform strongly on single-turn chart generation, their ability to support real-world exploratory data analysis remains underexplored. In practice, users iteratively refine visualizations through multi-turn interactions that require maintaining common ground, tracking prior edits, and adapting to evolving preferences. We introduce ChartEditBench, a benchmark for incremental, visually grounded chart editing via code, comprising 5,000 difficulty-controlled modification chains and a rigorously human-verified subset. Unlike prior one-shot benchmarks, ChartEditBench evaluates sustained, context-aware editing. We further propose a robust evaluation framework that mitigates limitations of LLM-as-a-Judge metrics by integrating execution-based fidelity checks, pixel-level visual similarity, and logical code verification. Experiments with state-of-the-art MLLMs reveal substantial degradation in multi-turn settings due to error accumulation and breakdowns in shared context, with strong performance on stylistic edits but frequent execution failures on data-centric transformations. ChartEditBench, establishes a challenging testbed for grounded, intent-aware multimodal programming.
Estimating Agreement by Chance for Sequence Annotation
Jul 16, 2024



In the field of natural language processing, correction of performance assessment for chance agreement plays a crucial role in evaluating the reliability of annotations. However, there is a notable dearth of research focusing on chance correction for assessing the reliability of sequence annotation tasks, despite their widespread prevalence in the field. To address this gap, this paper introduces a novel model for generating random annotations, which serves as the foundation for estimating chance agreement in sequence annotation tasks. Utilizing the proposed randomization model and a related comparison approach, we successfully derive the analytical form of the distribution, enabling the computation of the probable location of each annotated text segment and subsequent chance agreement estimation. Through a combination simulation and corpus-based evaluation, we successfully assess its applicability and validate its accuracy and efficacy.
Translational NLP: A New Paradigm and General Principles for Natural Language Processing Research
Apr 16, 2021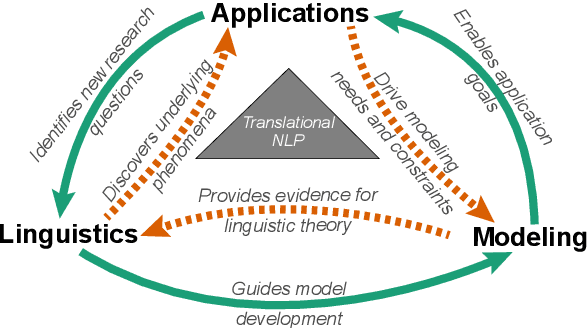

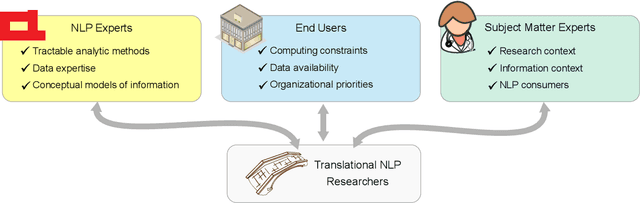
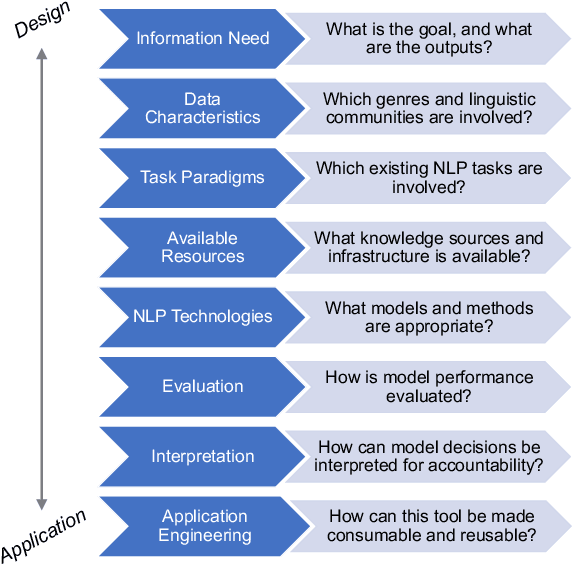
Natural language processing (NLP) research combines the study of universal principles, through basic science, with applied science targeting specific use cases and settings. However, the process of exchange between basic NLP and applications is often assumed to emerge naturally, resulting in many innovations going unapplied and many important questions left unstudied. We describe a new paradigm of Translational NLP, which aims to structure and facilitate the processes by which basic and applied NLP research inform one another. Translational NLP thus presents a third research paradigm, focused on understanding the challenges posed by application needs and how these challenges can drive innovation in basic science and technology design. We show that many significant advances in NLP research have emerged from the intersection of basic principles with application needs, and present a conceptual framework outlining the stakeholders and key questions in translational research. Our framework provides a roadmap for developing Translational NLP as a dedicated research area, and identifies general translational principles to facilitate exchange between basic and applied research.
Towards Open Domain Event Trigger Identification using Adversarial Domain Adaptation
May 22, 2020


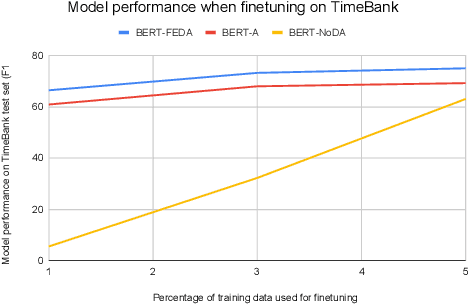
We tackle the task of building supervised event trigger identification models which can generalize better across domains. Our work leverages the adversarial domain adaptation (ADA) framework to introduce domain-invariance. ADA uses adversarial training to construct representations that are predictive for trigger identification, but not predictive of the example's domain. It requires no labeled data from the target domain, making it completely unsupervised. Experiments with two domains (English literature and news) show that ADA leads to an average F1 score improvement of 3.9 on out-of-domain data. Our best performing model (BERT-A) reaches 44-49 F1 across both domains, using no labeled target data. Preliminary experiments reveal that finetuning on 1% labeled data, followed by self-training leads to substantial improvement, reaching 51.5 and 67.2 F1 on literature and news respectively.