 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Transfer Learning for RSV Case Detection
Feb 03, 2024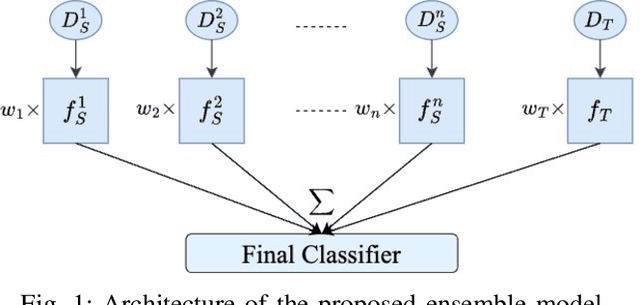



Transfer learning has become a pivotal technique in machine learning, renowned for its effectiveness in various real-world applications. However, a significant challenge arises when applying this approach to sequential epidemiological data, often characterized by a scarcity of labeled information. To address this challenge, we introduce Predictive Volume-Adaptive Weighting (PVAW), a novel online multi-source transfer learning method. PVAW innovatively implements a dynamic weighting mechanism within an ensemble model, allowing for the automatic adjustment of weights based on the relevance and contribution of each source and target model. We demonstrate the effectiveness of PVAW through its application in analyzing Respiratory Syncytial Virus (RSV) data, collected over multiple seasons at the University of Pittsburgh Medical Center. Our method showcases significant improvements in model performance over existing baselines, highlighting the potential of online transfer learning in handling complex, sequential data. This study not only underscores the adaptability and sophistication of transfer learning in healthcare but also sets a new direction for future research in creating advanced predictive models.
Alternative models: Critical examination of disability definitions in the development of artificial intelligence technologies
Jun 16, 2022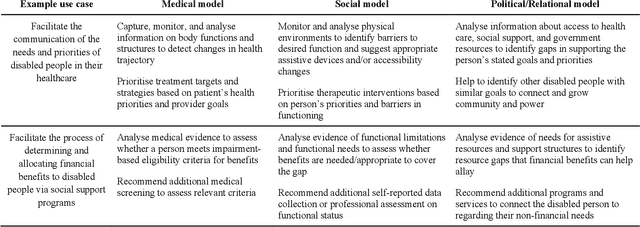
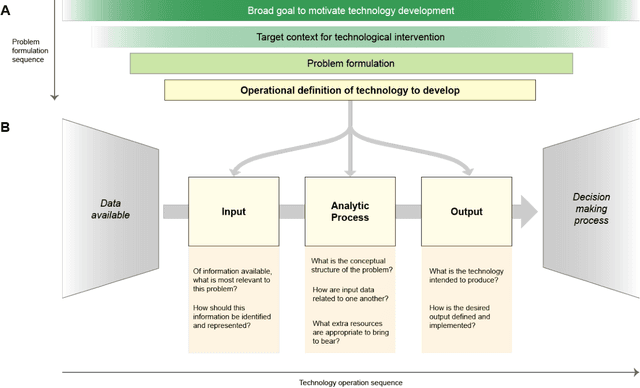
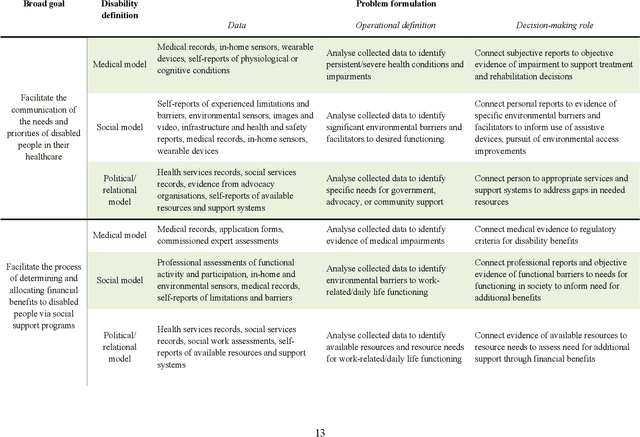
Disabled people are subject to a wide variety of complex decision-making processes in diverse areas such as healthcare, employment, and government policy. These contexts, which are already often opaque to the people they affect and lack adequate representation of disabled perspectives, are rapidly adopting artificial intelligence (AI) technologies for data analytics to inform decision making, creating an increased risk of harm due to inappropriate or inequitable algorithms. This article presents a framework for critically examining AI data analytics technologies through a disability lens and investigates how the definition of disability chosen by the designers of an AI technology affects its impact on disabled subjects of analysis. We consider three conceptual models of disability: the medical model, the social model, and the relational model; and show how AI technologies designed under each of these models differ so significantly as to be incompatible with and contradictory to one another. Through a discussion of common use cases for AI analytics in healthcare and government disability benefits, we illustrate specific considerations and decision points in the technology design process that affect power dynamics and inclusion in these settings and help determine their orientation towards marginalisation or support. The framework we present can serve as a foundation for in-depth critical examination of AI technologies and the development of a design praxis for disability-related AI analytics.
Translational NLP: A New Paradigm and General Principles for Natural Language Processing Research
Apr 16, 2021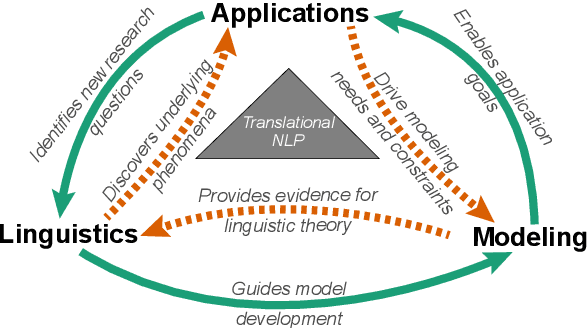

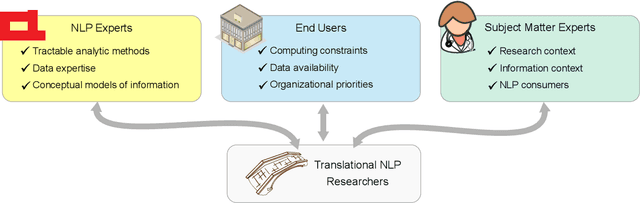
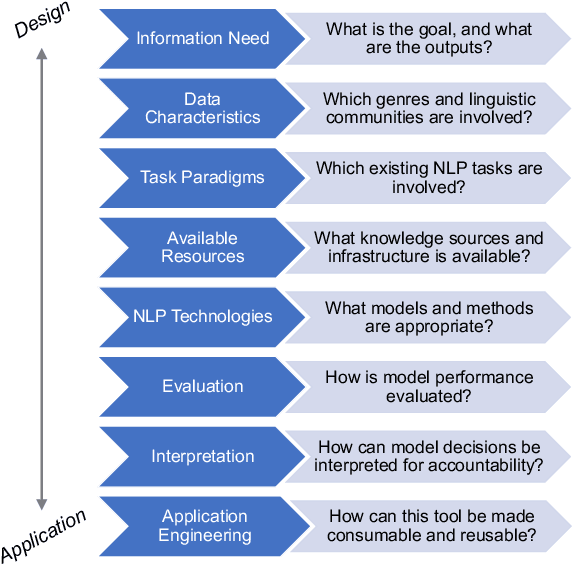
Natural language processing (NLP) research combines the study of universal principles, through basic science, with applied science targeting specific use cases and settings. However, the process of exchange between basic NLP and applications is often assumed to emerge naturally, resulting in many innovations going unapplied and many important questions left unstudied. We describe a new paradigm of Translational NLP, which aims to structure and facilitate the processes by which basic and applied NLP research inform one another. Translational NLP thus presents a third research paradigm, focused on understanding the challenges posed by application needs and how these challenges can drive innovation in basic science and technology design. We show that many significant advances in NLP research have emerged from the intersection of basic principles with application needs, and present a conceptual framework outlining the stakeholders and key questions in translational research. Our framework provides a roadmap for developing Translational NLP as a dedicated research area, and identifies general translational principles to facilitate exchange between basic and applied research.
TextEssence: A Tool for Interactive Analysis of Semantic Shifts Between Corpora
Mar 19, 2021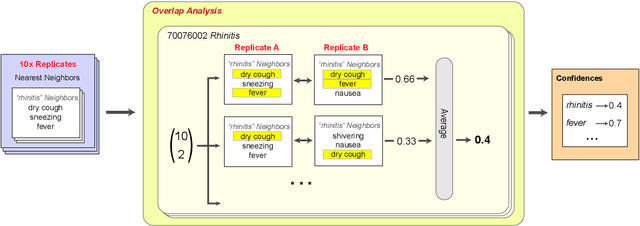
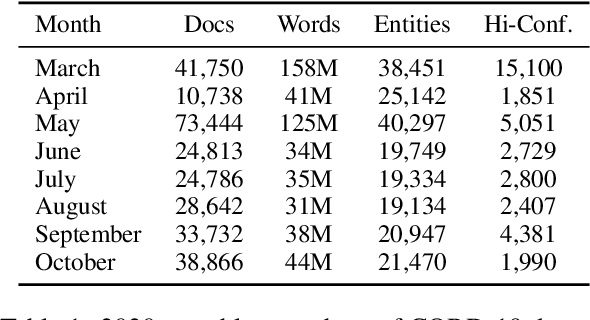
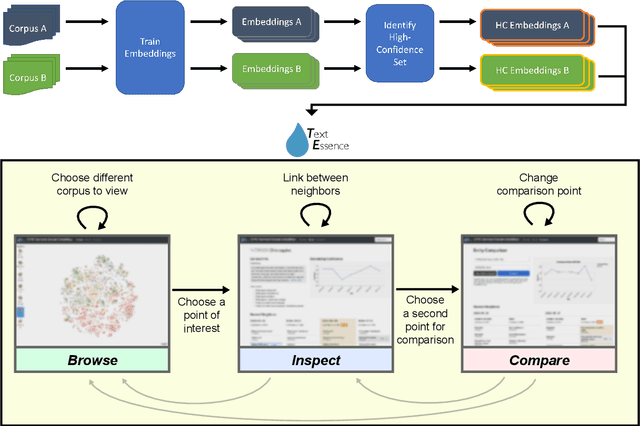

Embeddings of words and concepts capture syntactic and semantic regularities of language; however, they have seen limited use as tools to study characteristics of different corpora and how they relate to one another. We introduce TextEssence, an interactive system designed to enable comparative analysis of corpora using embeddings. TextEssence includes visual, neighbor-based, and similarity-based modes of embedding analysis in a lightweight, web-based interface. We further propose a new measure of embedding confidence based on nearest neighborhood overlap, to assist in identifying high-quality embeddings for corpus analysis. A case study on COVID-19 scientific literature illustrates the utility of the system. TextEssence is available from https://github.com/drgriffis/text-essence.
An Interactive Tool for Natural Language Processing on Clinical Text
Jul 07, 2017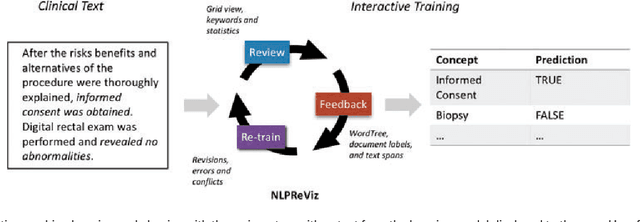
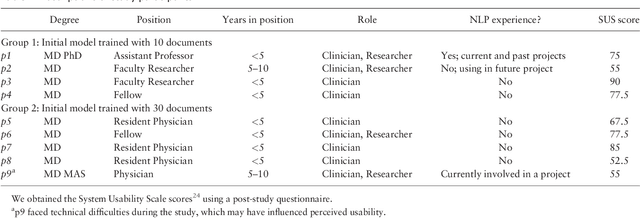
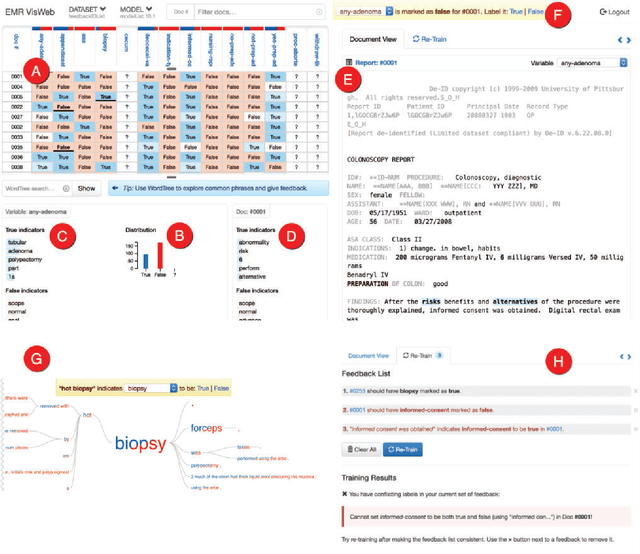
Natural Language Processing (NLP) systems often make use of machine learning techniques that are unfamiliar to end-users who are interested in analyzing clinical records. Although NLP has been widely used in extracting information from clinical text, current systems generally do not support model revision based on feedback from domain experts. We present a prototype tool that allows end users to visualize and review the outputs of an NLP system that extracts binary variables from clinical text. Our tool combines multiple visualizations to help the users understand these results and make any necessary corrections, thus forming a feedback loop and helping improve the accuracy of the NLP models. We have tested our prototype in a formative think-aloud user study with clinicians and researchers involved in colonoscopy research. Results from semi-structured interviews and a System Usability Scale (SUS) analysis show that the users are able to quickly start refining NLP models, despite having very little or no experience with machine learning. Observations from these sessions suggest revisions to the interface to better support review workflow and interpretation of results.