 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Memory Engine: Spatial Memory for Robust Multi-Step LLM Agents
May 26, 2025Large Language Models (LLMs) falter in multi-step interactions -- often hallucinating, repeating actions, or misinterpreting user corrections -- due to reliance on linear, unstructured context. This fragility stems from the lack of persistent memory to track evolving goals and task dependencies, undermining trust in autonomous agents. We introduce the Task Memory Engine (TME), a modular memory controller that transforms existing LLMs into robust, revision-aware agents without fine-tuning. TME implements a spatial memory framework that replaces flat context with graph-based structures to support consistent, multi-turn reasoning. Departing from linear concatenation and ReAct-style prompting, TME builds a dynamic task graph -- either a tree or directed acyclic graph (DAG) -- to map user inputs to subtasks, align them with prior context, and enable dependency-tracked revisions. Its Task Representation and Intent Management (TRIM) component models task semantics and user intent to ensure accurate interpretation. Across four multi-turn scenarios-trip planning, cooking, meeting scheduling, and shopping cart editing -- TME eliminates 100% of hallucinations and misinterpretations in three tasks, and reduces hallucinations by 66.7% and misinterpretations by 83.3% across 27 user turns, outperforming ReAct. TME's modular design supports plug-and-play deployment and domain-specific customization, adaptable to both personal assistants and enterprise automation. We release TME's codebase, benchmarks, and components as open-source resources, enabling researchers to develop reliable LLM agents. TME's scalable architecture addresses a critical gap in agent performance across complex, interactive settings.
Task Memory Engine (TME): A Structured Memory Framework with Graph-Aware Extensions for Multi-Step LLM Agent Tasks
Apr 16, 2025Large Language Models (LLMs) are increasingly used as autonomous agents for multi-step tasks. However, most existing frameworks fail to maintain a structured understanding of the task state, often relying on linear prompt concatenation or shallow memory buffers. This leads to brittle performance, frequent hallucinations, and poor long-range coherence. In this work, we propose the Task Memory Engine (TME), a lightweight and structured memory module that tracks task execution using a hierarchical Task Memory Tree (TMT). Each node in the tree corresponds to a task step, storing relevant input, output, status, and sub-task relationships. We introduce a prompt synthesis method that dynamically generates LLM prompts based on the active node path, significantly improving execution consistency and contextual grounding. Through case studies and comparative experiments on multi-step agent tasks, we demonstrate that TME leads to better task completion accuracy and more interpretable behavior with minimal implementation overhead. A reference implementation of the core TME components is available at https://github.com/biubiutomato/TME-Agent, including basic examples and structured memory integration. While the current implementation uses a tree-based structure, TME is designed to be graph-aware, supporting reusable substeps, converging task paths, and shared dependencies. This lays the groundwork for future DAG-based memory architectures.
Transfer Learning with Clinical Concept Embeddings from Large Language Models
Sep 20, 2024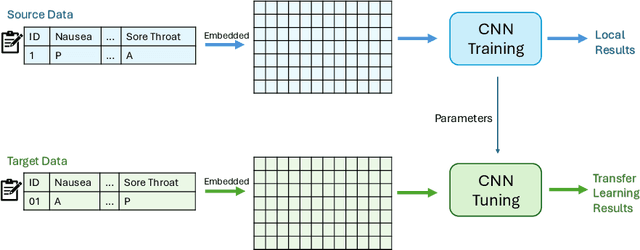

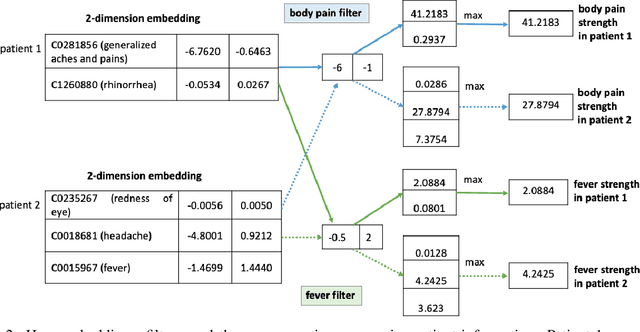

Knowledge sharing is crucial in healthcare, especially when leveraging data from multiple clinical sites to address data scarcity, reduce costs, and enable timely interventions. Transfer learning can facilitate cross-site knowledge transfer, but a major challenge is heterogeneity in clinical concepts across different sites. Large Language Models (LLMs) show significant potential of capturing the semantic meaning of clinical concepts and reducing heterogeneity. This study analyzed electronic health records from two large healthcare systems to assess the impact of semantic embeddings from LLMs on local, shared, and transfer learning models. Results indicate that domain-specific LLMs, such as Med-BERT, consistently outperform in local and direct transfer scenarios, while generic models like OpenAI embeddings require fine-tuning for optimal performance. However, excessive tuning of models with biomedical embeddings may reduce effectiveness, emphasizing the need for balance. This study highlights the importance of domain-specific embeddings and careful model tuning for effective knowledge transfer in healthcare.
Online Transfer Learning for RSV Case Detection
Feb 03, 2024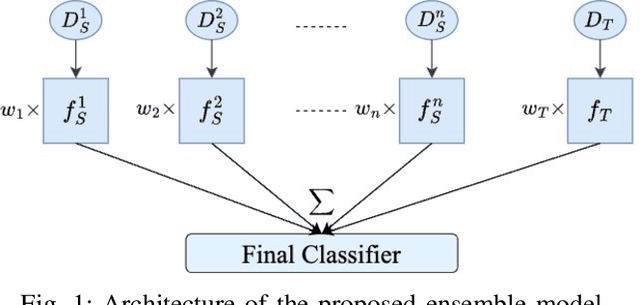



Transfer learning has become a pivotal technique in machine learning, renowned for its effectiveness in various real-world applications. However, a significant challenge arises when applying this approach to sequential epidemiological data, often characterized by a scarcity of labeled information. To address this challenge, we introduce Predictive Volume-Adaptive Weighting (PVAW), a novel online multi-source transfer learning method. PVAW innovatively implements a dynamic weighting mechanism within an ensemble model, allowing for the automatic adjustment of weights based on the relevance and contribution of each source and target model. We demonstrate the effectiveness of PVAW through its application in analyzing Respiratory Syncytial Virus (RSV) data, collected over multiple seasons at the University of Pittsburgh Medical Center. Our method showcases significant improvements in model performance over existing baselines, highlighting the potential of online transfer learning in handling complex, sequential data. This study not only underscores the adaptability and sophistication of transfer learning in healthcare but also sets a new direction for future research in creating advanced predictive models.
A Survey of Heterogeneous Transfer Learning
Oct 15, 2023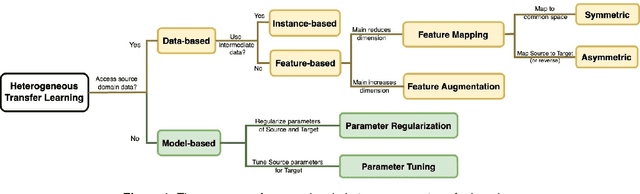

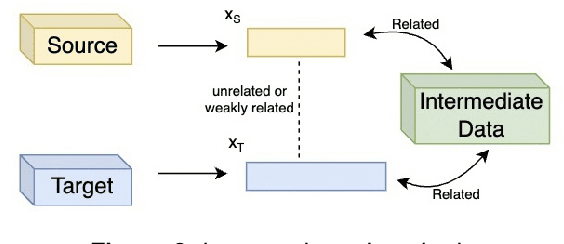

The application of transfer learning, an approach utilizing knowledge from a source domain to enhance model performance in a target domain, has seen a tremendous rise in recent years, underpinning many real-world scenarios. The key to its success lies in the shared common knowledge between the domains, a prerequisite in most transfer learning methodologies. These methods typically presuppose identical feature spaces and label spaces in both domains, known as homogeneous transfer learning, which, however, is not always a practical assumption. Oftentimes, the source and target domains vary in feature spaces, data distributions, and label spaces, making it challenging or costly to secure source domain data with identical feature and label spaces as the target domain. Arbitrary elimination of these differences is not always feasible or optimal. Thus, heterogeneous transfer learning, acknowledging and dealing with such disparities, has emerged as a promising approach for a variety of tasks. Despite the existence of a survey in 2017 on this topic, the fast-paced advances post-2017 necessitate an updated, in-depth review. We therefore present a comprehensive survey of recent developments in heterogeneous transfer learning methods, offering a systematic guide for future research. Our paper reviews methodologies for diverse learning scenarios, discusses the limitations of current studies, and covers various application contexts, including Natural Language Processing, Computer Vision, Multimodality, and Biomedicine, to foster a deeper understanding and spur future research.
Prediction of COVID-19 Patients' Emergency Room Revisit using Multi-Source Transfer Learning
Jun 29, 2023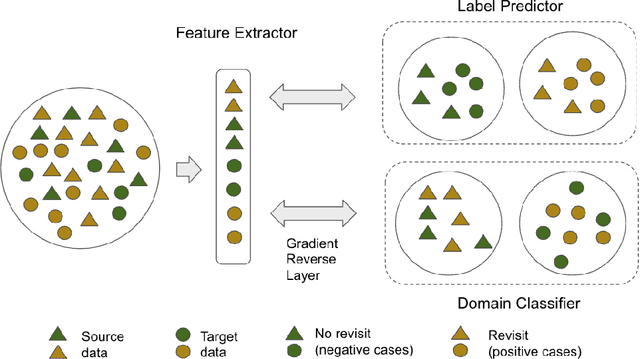
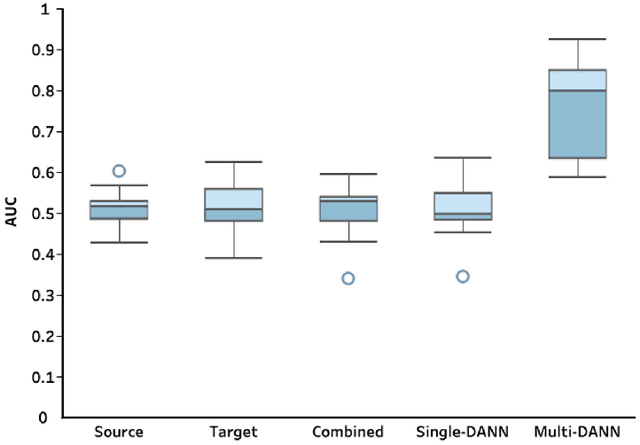
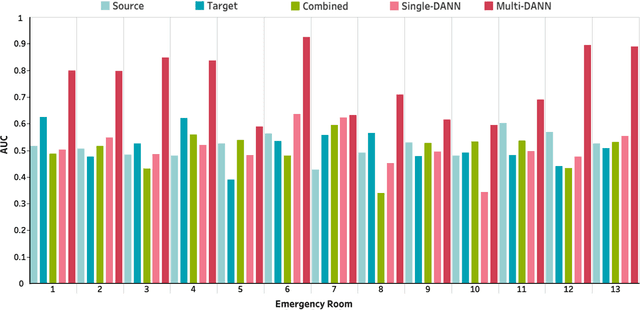
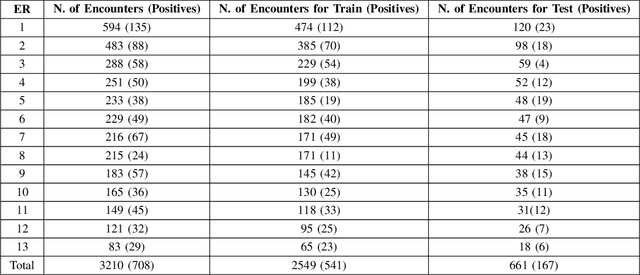
The coronavirus disease 2019 (COVID-19) has led to a global pandemic of significant severity. In addition to its high level of contagiousness, COVID-19 can have a heterogeneous clinical course, ranging from asymptomatic carriers to severe and potentially life-threatening health complications. Many patients have to revisit the emergency room (ER) within a short time after discharge, which significantly increases the workload for medical staff. Early identification of such patients is crucial for helping physicians focus on treating life-threatening cases. In this study, we obtained Electronic Health Records (EHRs) of 3,210 encounters from 13 affiliated ERs within the University of Pittsburgh Medical Center between March 2020 and January 2021. We leveraged a Natural Language Processing technique, ScispaCy, to extract clinical concepts and used the 1001 most frequent concepts to develop 7-day revisit models for COVID-19 patients in ERs. The research data we collected from 13 ERs may have distributional differences that could affect the model development. To address this issue, we employed a classic deep transfer learning method called the Domain Adversarial Neural Network (DANN) and evaluated different modeling strategies, including the Multi-DANN algorithm, the Single-DANN algorithm, and three baseline methods. Results showed that the Multi-DANN models outperformed the Single-DANN models and baseline models in predicting revisits of COVID-19 patients to the ER within 7 days after discharge. Notably, the Multi-DANN strategy effectively addressed the heterogeneity among multiple source domains and improved the adaptation of source data to the target domain. Moreover, the high performance of Multi-DANN models indicates that EHRs are informative for developing a prediction model to identify COVID-19 patients who are very likely to revisit an ER within 7 days after discharge.
Deep Transfer Learning for Infectious Disease Case Detection Using Electronic Medical Records
Mar 08, 2021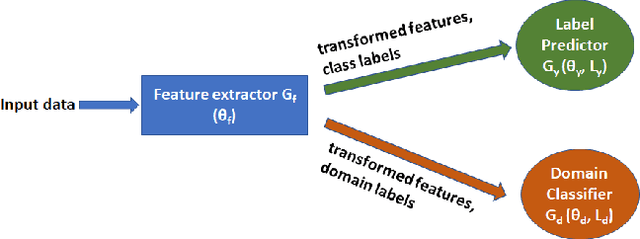


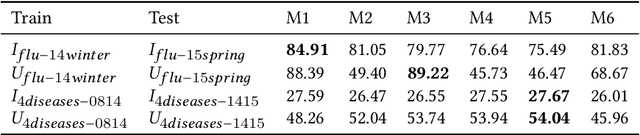
During an infectious disease pandemic, it is critical to share electronic medical records or models (learned from these records) across regions. Applying one region's data/model to another region often have distribution shift issues that violate the assumptions of traditional machine learning techniques. Transfer learning can be a solution. To explore the potential of deep transfer learning algorithms, we applied two data-based algorithms (domain adversarial neural networks and maximum classifier discrepancy) and model-based transfer learning algorithms to infectious disease detection tasks. We further studied well-defined synthetic scenarios where the data distribution differences between two regions are known. Our experiments show that, in the context of infectious disease classification, transfer learning may be useful when (1) the source and target are similar and the target training data is insufficient and (2) the target training data does not have labels. Model-based transfer learning works well in the first situation, in which case the performance closely matched that of the data-based transfer learning models. Still, further investigation of the domain shift in real world research data to account for the drop in performance is needed.
Change-point Detection Methods for Body-Worn Video
Oct 20, 2016

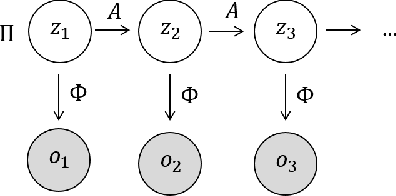

Body-worn video (BWV) cameras are increasingly utilized by police departments to provide a record of police-public interactions. However, large-scale BWV deployment produces terabytes of data per week, necessitating the development of effective computational methods to identify salient changes in video. In work carried out at the 2016 RIPS program at IPAM, UCLA, we present a novel two-stage framework for video change-point detection. First, we employ state-of-the-art machine learning methods including convolutional neural networks and support vector machines for scene classification. We then develop and compare change-point detection algorithms utilizing mean squared-error minimization, forecasting methods, hidden Markov models, and maximum likelihood estimation to identify noteworthy changes. We test our framework on detection of vehicle exits and entrances in a BWV data set provided by the Los Angeles Police Department and achieve over 90% recall and nearly 70% precision -- demonstrating robustness to rapid scene changes, extreme luminance differences, and frequent camera occlusions.