 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning with Clinical Concept Embeddings from Large Language Models
Sep 20, 2024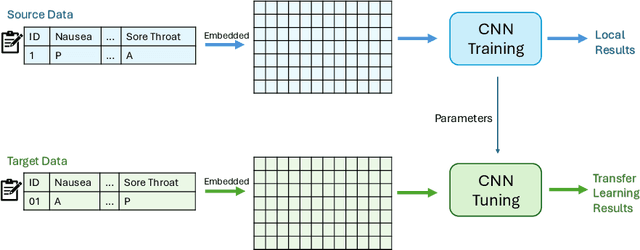

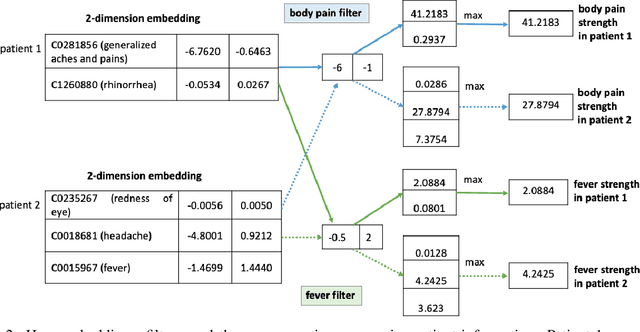

Knowledge sharing is crucial in healthcare, especially when leveraging data from multiple clinical sites to address data scarcity, reduce costs, and enable timely interventions. Transfer learning can facilitate cross-site knowledge transfer, but a major challenge is heterogeneity in clinical concepts across different sites. Large Language Models (LLMs) show significant potential of capturing the semantic meaning of clinical concepts and reducing heterogeneity. This study analyzed electronic health records from two large healthcare systems to assess the impact of semantic embeddings from LLMs on local, shared, and transfer learning models. Results indicate that domain-specific LLMs, such as Med-BERT, consistently outperform in local and direct transfer scenarios, while generic models like OpenAI embeddings require fine-tuning for optimal performance. However, excessive tuning of models with biomedical embeddings may reduce effectiveness, emphasizing the need for balance. This study highlights the importance of domain-specific embeddings and careful model tuning for effective knowledge transfer in healthcare.
Online Transfer Learning for RSV Case Detection
Feb 03, 2024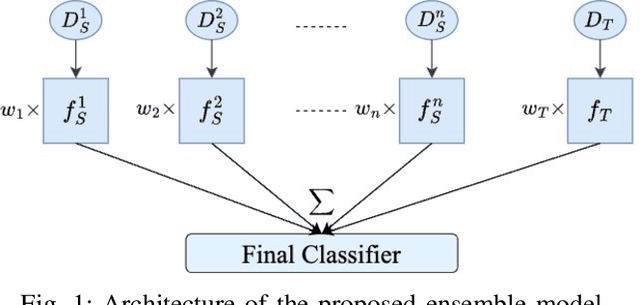



Transfer learning has become a pivotal technique in machine learning, renowned for its effectiveness in various real-world applications. However, a significant challenge arises when applying this approach to sequential epidemiological data, often characterized by a scarcity of labeled information. To address this challenge, we introduce Predictive Volume-Adaptive Weighting (PVAW), a novel online multi-source transfer learning method. PVAW innovatively implements a dynamic weighting mechanism within an ensemble model, allowing for the automatic adjustment of weights based on the relevance and contribution of each source and target model. We demonstrate the effectiveness of PVAW through its application in analyzing Respiratory Syncytial Virus (RSV) data, collected over multiple seasons at the University of Pittsburgh Medical Center. Our method showcases significant improvements in model performance over existing baselines, highlighting the potential of online transfer learning in handling complex, sequential data. This study not only underscores the adaptability and sophistication of transfer learning in healthcare but also sets a new direction for future research in creating advanced predictive models.
Large Language Model for Causal Decision Making
Dec 29, 2023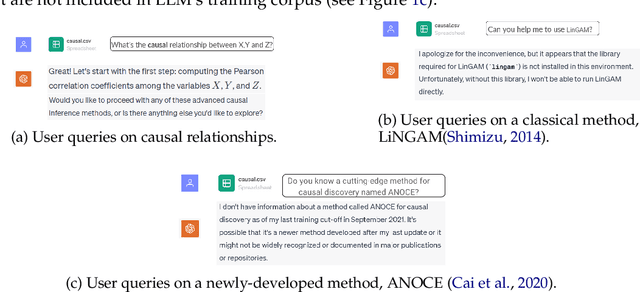

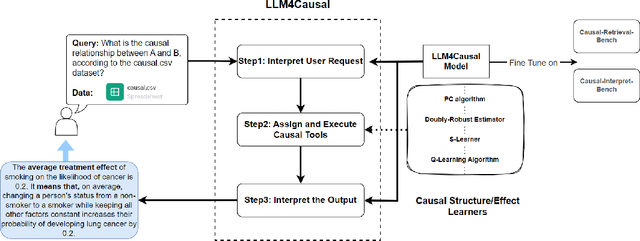

Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to inference based on user-specified structured data and knowledge in corpus-rare concepts like causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. With three case studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers. Numerical studies also reveal that it has a remarkable ability to identify the correct causal task given a query.
A Survey of Heterogeneous Transfer Learning
Oct 15, 2023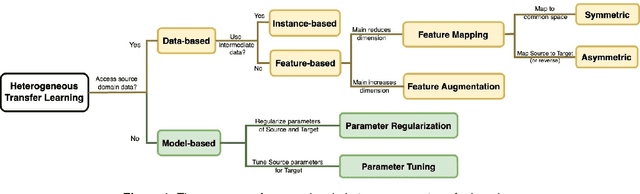

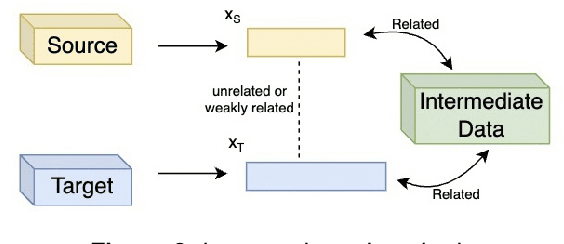

The application of transfer learning, an approach utilizing knowledge from a source domain to enhance model performance in a target domain, has seen a tremendous rise in recent years, underpinning many real-world scenarios. The key to its success lies in the shared common knowledge between the domains, a prerequisite in most transfer learning methodologies. These methods typically presuppose identical feature spaces and label spaces in both domains, known as homogeneous transfer learning, which, however, is not always a practical assumption. Oftentimes, the source and target domains vary in feature spaces, data distributions, and label spaces, making it challenging or costly to secure source domain data with identical feature and label spaces as the target domain. Arbitrary elimination of these differences is not always feasible or optimal. Thus, heterogeneous transfer learning, acknowledging and dealing with such disparities, has emerged as a promising approach for a variety of tasks. Despite the existence of a survey in 2017 on this topic, the fast-paced advances post-2017 necessitate an updated, in-depth review. We therefore present a comprehensive survey of recent developments in heterogeneous transfer learning methods, offering a systematic guide for future research. Our paper reviews methodologies for diverse learning scenarios, discusses the limitations of current studies, and covers various application contexts, including Natural Language Processing, Computer Vision, Multimodality, and Biomedicine, to foster a deeper understanding and spur future research.
Prediction of COVID-19 Patients' Emergency Room Revisit using Multi-Source Transfer Learning
Jun 29, 2023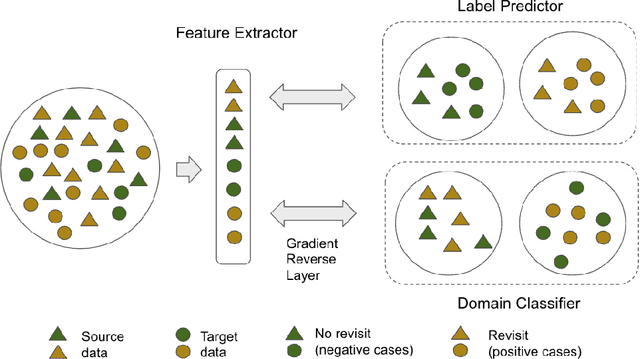
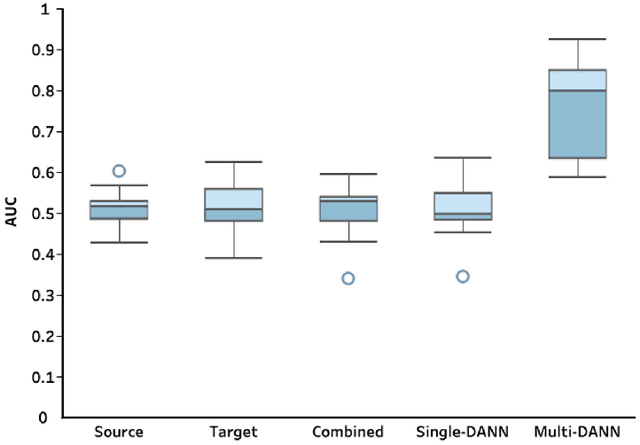
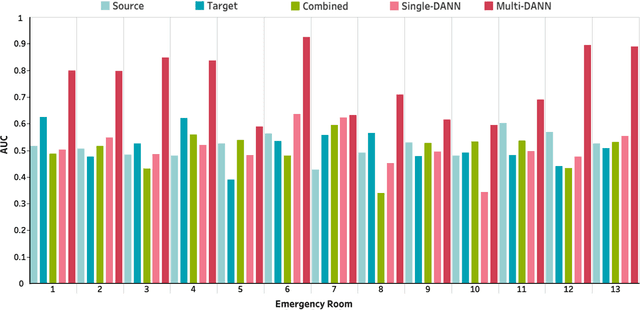
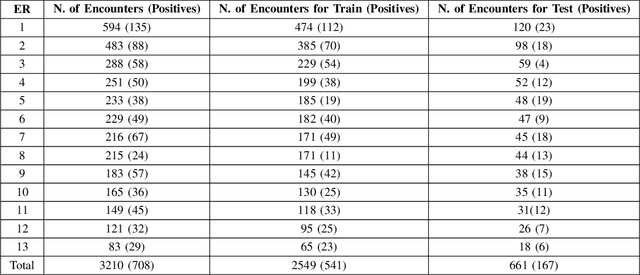
The coronavirus disease 2019 (COVID-19) has led to a global pandemic of significant severity. In addition to its high level of contagiousness, COVID-19 can have a heterogeneous clinical course, ranging from asymptomatic carriers to severe and potentially life-threatening health complications. Many patients have to revisit the emergency room (ER) within a short time after discharge, which significantly increases the workload for medical staff. Early identification of such patients is crucial for helping physicians focus on treating life-threatening cases. In this study, we obtained Electronic Health Records (EHRs) of 3,210 encounters from 13 affiliated ERs within the University of Pittsburgh Medical Center between March 2020 and January 2021. We leveraged a Natural Language Processing technique, ScispaCy, to extract clinical concepts and used the 1001 most frequent concepts to develop 7-day revisit models for COVID-19 patients in ERs. The research data we collected from 13 ERs may have distributional differences that could affect the model development. To address this issue, we employed a classic deep transfer learning method called the Domain Adversarial Neural Network (DANN) and evaluated different modeling strategies, including the Multi-DANN algorithm, the Single-DANN algorithm, and three baseline methods. Results showed that the Multi-DANN models outperformed the Single-DANN models and baseline models in predicting revisits of COVID-19 patients to the ER within 7 days after discharge. Notably, the Multi-DANN strategy effectively addressed the heterogeneity among multiple source domains and improved the adaptation of source data to the target domain. Moreover, the high performance of Multi-DANN models indicates that EHRs are informative for developing a prediction model to identify COVID-19 patients who are very likely to revisit an ER within 7 days after discharge.
Deep Spectral Q-learning with Application to Mobile Health
Jan 03, 2023Dynamic treatment regimes assign personalized treatments to patients sequentially over time based on their baseline information and time-varying covariates. In mobile health applications, these covariates are typically collected at different frequencies over a long time horizon. In this paper, we propose a deep spectral Q-learning algorithm, which integrates principal component analysis (PCA) with deep Q-learning to handle the mixed frequency data. In theory, we prove that the mean return under the estimated optimal policy converges to that under the optimal one and establish its rate of convergence. The usefulness of our proposal is further illustrated via simulations and an application to a diabetes dataset.
Sparse Winograd Convolutional neural networks on small-scale systolic arrays
Oct 03, 2018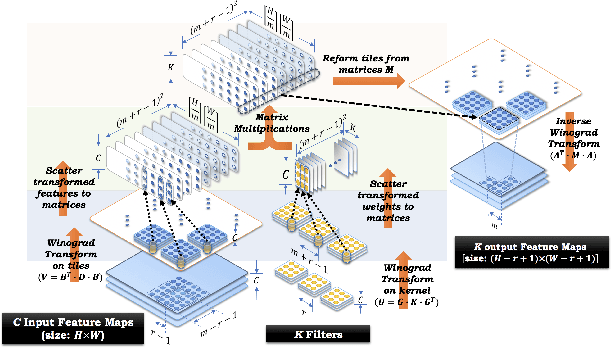
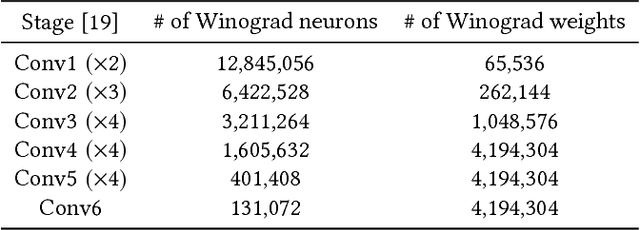
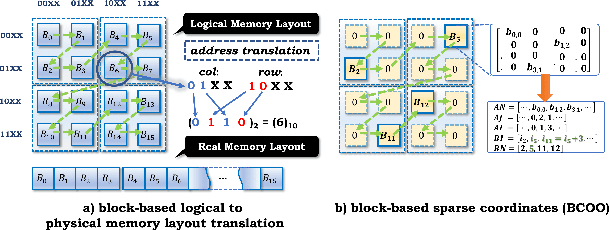
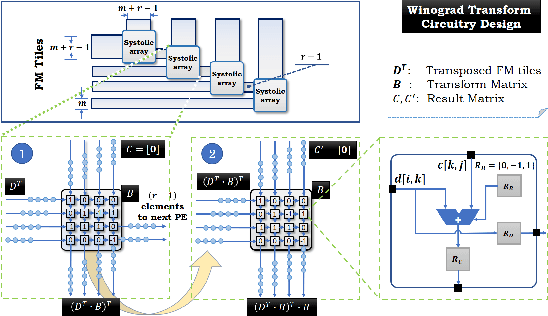
The reconfigurability, energy-efficiency, and massive parallelism on FPGAs make them one of the best choices for implementing efficient deep learning accelerators. However, state-of-art implementations seldom consider the balance between high throughput of computation power and the ability of the memory subsystem to support it. In this paper, we implement an accelerator on FPGA by combining the sparse Winograd convolution, clusters of small-scale systolic arrays, and a tailored memory layout design. We also provide an analytical model analysis for the general Winograd convolution algorithm as a design reference. Experimental results on VGG16 show that it achieves very high computational resource utilization, 20x ~ 30x energy efficiency, and more than 5x speedup compared with the dense implementation.