 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model for Causal Decision Making
Paper and Code
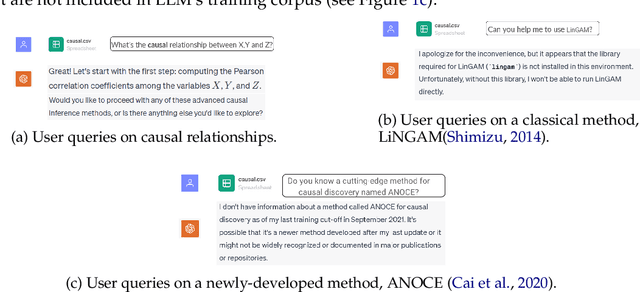

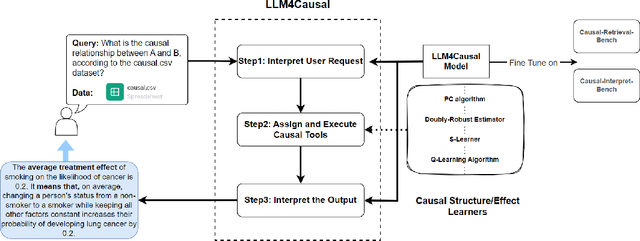

Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to inference based on user-specified structured data and knowledge in corpus-rare concepts like causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. With three case studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers. Numerical studies also reveal that it has a remarkable ability to identify the correct causal task given a query.