 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Reasoning Cues: A Framework and Case Study of the Roles of AI Information in Complex Decisions
Jan 30, 2026Artificial intelligence (AI)-based decision support systems can be highly accurate yet still fail to support users or improve decisions. Existing theories of AI-assisted decision-making focus on calibrating reliance on AI advice, leaving it unclear how different system designs might influence the reasoning processes underneath. We address this gap by reconsidering AI interfaces as collections of intelligent reasoning cues: discrete pieces of AI information that can individually influence decision-making. We then explore the roles of eight types of reasoning cues in a high-stakes clinical decision (treating patients with sepsis in intensive care). Through contextual inquiries with six teams and a think-aloud study with 25 physicians, we find that reasoning cues have distinct patterns of influence that can directly inform design. Our results also suggest that reasoning cues should prioritize tasks with high variability and discretion, adapt to ensure compatibility with evolving decision needs, and provide complementary, rigorous insights on complex cases.
Over-Relying on Reliance: Towards Realistic Evaluations of AI-Based Clinical Decision Support
Apr 10, 2025As AI-based clinical decision support (AI-CDS) is introduced in more and more aspects of healthcare services, HCI research plays an increasingly important role in designing for complementarity between AI and clinicians. However, current evaluations of AI-CDS often fail to capture when AI is and is not useful to clinicians. This position paper reflects on our work and influential AI-CDS literature to advocate for moving beyond evaluation metrics like Trust, Reliance, Acceptance, and Performance on the AI's task (what we term the "trap" of human-AI collaboration). Although these metrics can be meaningful in some simple scenarios, we argue that optimizing for them ignores important ways that AI falls short of clinical benefit, as well as ways that clinicians successfully use AI. As the fields of HCI and AI in healthcare develop new ways to design and evaluate CDS tools, we call on the community to prioritize ecologically valid, domain-appropriate study setups that measure the emergent forms of value that AI can bring to healthcare professionals.
Compress and Compare: Interactively Evaluating Efficiency and Behavior Across ML Model Compression Experiments
Aug 06, 2024To deploy machine learning models on-device, practitioners use compression algorithms to shrink and speed up models while maintaining their high-quality output. A critical aspect of compression in practice is model comparison, including tracking many compression experiments, identifying subtle changes in model behavior, and negotiating complex accuracy-efficiency trade-offs. However, existing compression tools poorly support comparison, leading to tedious and, sometimes, incomplete analyses spread across disjoint tools. To support real-world comparative workflows, we develop an interactive visual system called Compress and Compare. Within a single interface, Compress and Compare surfaces promising compression strategies by visualizing provenance relationships between compressed models and reveals compression-induced behavior changes by comparing models' predictions, weights, and activations. We demonstrate how Compress and Compare supports common compression analysis tasks through two case studies, debugging failed compression on generative language models and identifying compression artifacts in image classification models. We further evaluate Compress and Compare in a user study with eight compression experts, illustrating its potential to provide structure to compression workflows, help practitioners build intuition about compression, and encourage thorough analysis of compression's effect on model behavior. Through these evaluations, we identify compression-specific challenges that future visual analytics tools should consider and Compress and Compare visualizations that may generalize to broader model comparison tasks.
How Consistent are Clinicians? Evaluating the Predictability of Sepsis Disease Progression with Dynamics Models
Apr 10, 2024Reinforcement learning (RL) is a promising approach to generate treatment policies for sepsis patients in intensive care. While retrospective evaluation metrics show decreased mortality when these policies are followed, studies with clinicians suggest their recommendations are often spurious. We propose that these shortcomings may be due to lack of diversity in observed actions and outcomes in the training data, and we construct experiments to investigate the feasibility of predicting sepsis disease severity changes due to clinician actions. Preliminary results suggest incorporating action information does not significantly improve model performance, indicating that clinician actions may not be sufficiently variable to yield measurable effects on disease progression. We discuss the implications of these findings for optimizing sepsis treatment.
LSTM-RASA Based Agri Farm Assistant for Farmers
Apr 07, 2022



The application of Deep Learning and Natural Language based ChatBots are growing rapidly in recent years. They are used in many fields like customer support, reservation system and as personal assistant. The Enterprises are using such ChatBots to serve their customers in a better and efficient manner. Even after such technological advancement, the expert advice does not reach the farmers on timely manner. The farmers are still largely dependent on their peers knowledge in solving the problems they face in their field. These technologies have not been effectively used to give the required information to farmers on timely manner. This project aims to implement a closed domain ChatBot for the field of Agriculture Farmers Assistant. Farmers can have conversation with the Chatbot and get the expert advice in their field. Farmers Assistant is based on RASA Open Source Framework. The Chatbot identifies the intent and entity from user utterances and retrieve the remedy from the database and share it with the user. We tested the Bot with existing data and it showed promising results.
Improving Human-AI Partnerships in Child Welfare: Understanding Worker Practices, Challenges, and Desires for Algorithmic Decision Support
Apr 05, 2022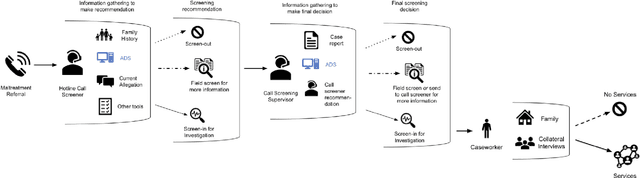
AI-based decision support tools (ADS) are increasingly used to augment human decision-making in high-stakes, social contexts. As public sector agencies begin to adopt ADS, it is critical that we understand workers' experiences with these systems in practice. In this paper, we present findings from a series of interviews and contextual inquiries at a child welfare agency, to understand how they currently make AI-assisted child maltreatment screening decisions. Overall, we observe how workers' reliance upon the ADS is guided by (1) their knowledge of rich, contextual information beyond what the AI model captures, (2) their beliefs about the ADS's capabilities and limitations relative to their own, (3) organizational pressures and incentives around the use of the ADS, and (4) awareness of misalignments between algorithmic predictions and their own decision-making objectives. Drawing upon these findings, we discuss design implications towards supporting more effective human-AI decision-making.
Emblaze: Illuminating Machine Learning Representations through Interactive Comparison of Embedding Spaces
Feb 16, 2022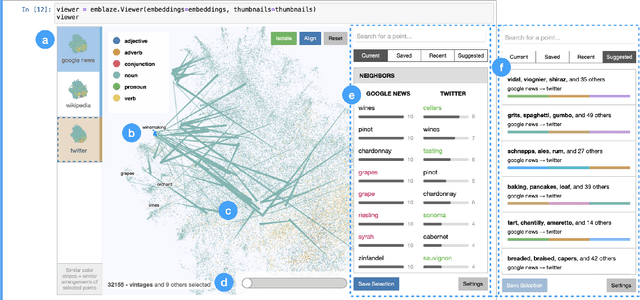


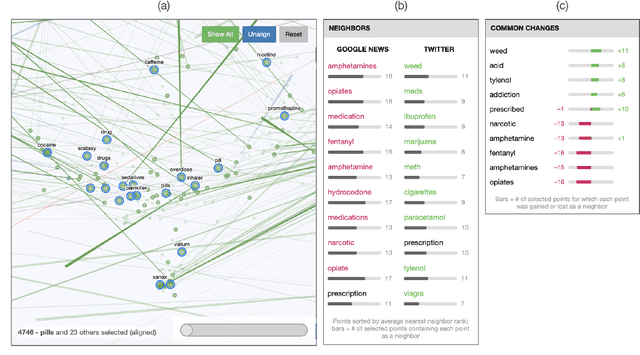
Modern machine learning techniques commonly rely on complex, high-dimensional embedding representations to capture underlying structure in the data and improve performance. In order to characterize model flaws and choose a desirable representation, model builders often need to compare across multiple embedding spaces, a challenging analytical task supported by few existing tools. We first interviewed nine embedding experts in a variety of fields to characterize the diverse challenges they face and techniques they use when analyzing embedding spaces. Informed by these perspectives, we developed a novel system called Emblaze that integrates embedding space comparison within a computational notebook environment. Emblaze uses an animated, interactive scatter plot with a novel Star Trail augmentation to enable visual comparison. It also employs novel neighborhood analysis and clustering procedures to dynamically suggest groups of points with interesting changes between spaces. Through a series of case studies with ML experts, we demonstrate how interactive comparison with Emblaze can help gain new insights into embedding space structure.
TextEssence: A Tool for Interactive Analysis of Semantic Shifts Between Corpora
Mar 19, 2021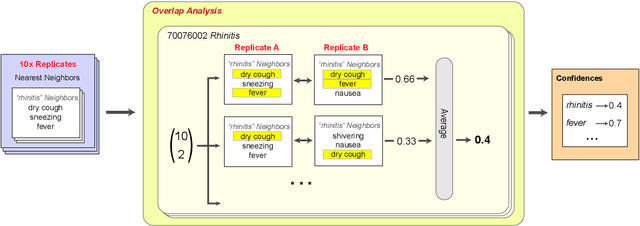
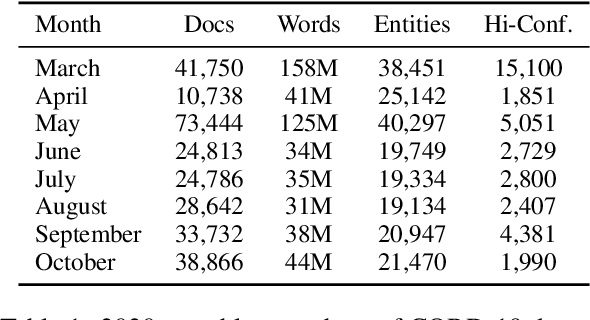
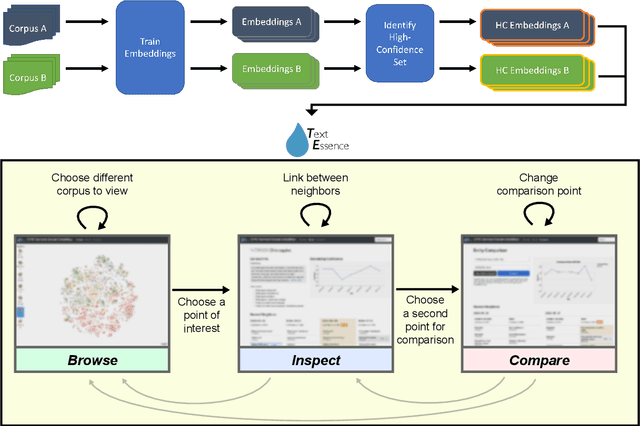

Embeddings of words and concepts capture syntactic and semantic regularities of language; however, they have seen limited use as tools to study characteristics of different corpora and how they relate to one another. We introduce TextEssence, an interactive system designed to enable comparative analysis of corpora using embeddings. TextEssence includes visual, neighbor-based, and similarity-based modes of embedding analysis in a lightweight, web-based interface. We further propose a new measure of embedding confidence based on nearest neighborhood overlap, to assist in identifying high-quality embeddings for corpus analysis. A case study on COVID-19 scientific literature illustrates the utility of the system. TextEssence is available from https://github.com/drgriffis/text-essence.