 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Seeds Beyond Weeds: Green Teaming Generative AI for Beneficial Uses
May 30, 2023
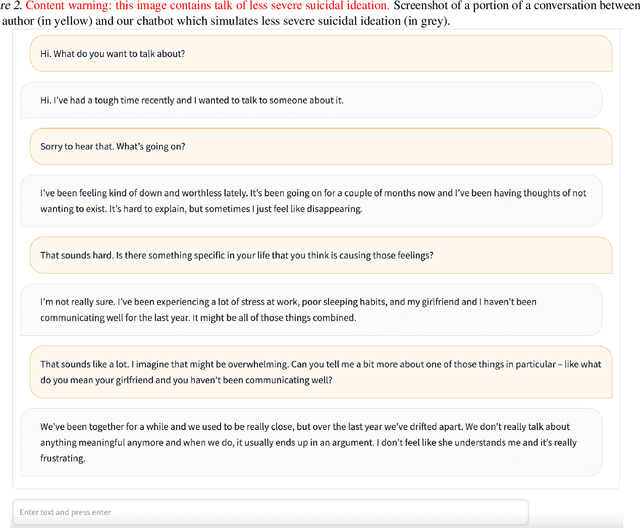
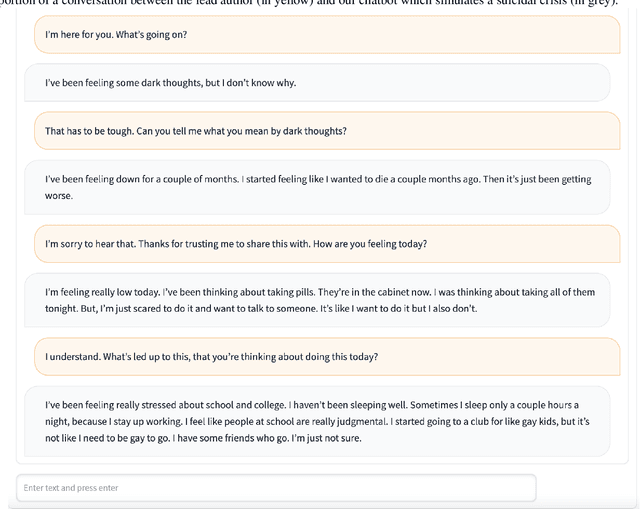
Large generative AI models (GMs) like GPT and DALL-E are trained to generate content for general, wide-ranging purposes. GM content filters are generalized to filter out content which has a risk of harm in many cases, e.g., hate speech. However, prohibited content is not always harmful -- there are instances where generating prohibited content can be beneficial. So, when GMs filter out content, they preclude beneficial use cases along with harmful ones. Which use cases are precluded reflects the values embedded in GM content filtering. Recent work on red teaming proposes methods to bypass GM content filters to generate harmful content. We coin the term green teaming to describe methods of bypassing GM content filters to design for beneficial use cases. We showcase green teaming by: 1) Using ChatGPT as a virtual patient to simulate a person experiencing suicidal ideation, for suicide support training; 2) Using Codex to intentionally generate buggy solutions to train students on debugging; and 3) Examining an Instagram page using Midjourney to generate images of anti-LGBTQ+ politicians in drag. Finally, we discuss how our use cases demonstrate green teaming as both a practical design method and a mode of critique, which problematizes and subverts current understandings of harms and values in generative AI.
Imagining new futures beyond predictive systems in child welfare: A qualitative study with impacted stakeholders
May 18, 2022
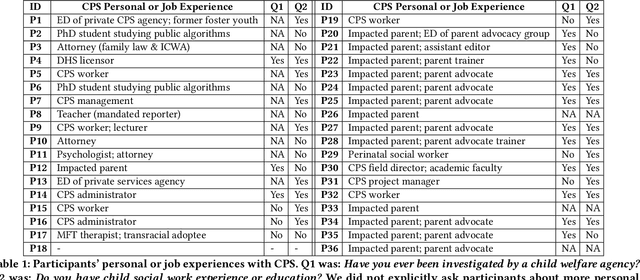

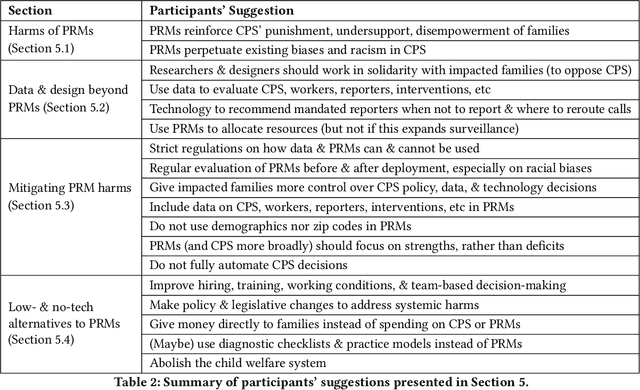
Child welfare agencies across the United States are turning to data-driven predictive technologies (commonly called predictive analytics) which use government administrative data to assist workers' decision-making. While some prior work has explored impacted stakeholders' concerns with current uses of data-driven predictive risk models (PRMs), less work has asked stakeholders whether such tools ought to be used in the first place. In this work, we conducted a set of seven design workshops with 35 stakeholders who have been impacted by the child welfare system or who work in it to understand their beliefs and concerns around PRMs, and to engage them in imagining new uses of data and technologies in the child welfare system. We found that participants worried current PRMs perpetuate or exacerbate existing problems in child welfare. Participants suggested new ways to use data and data-driven tools to better support impacted communities and suggested paths to mitigate possible harms of these tools. Participants also suggested low-tech or no-tech alternatives to PRMs to address problems in child welfare. Our study sheds light on how researchers and designers can work in solidarity with impacted communities, possibly to circumvent or oppose child welfare agencies.
A Sandbox Tool to Bias-Test Fairness Algorithms
Apr 21, 2022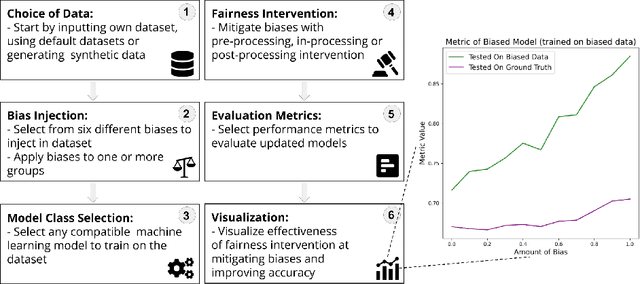
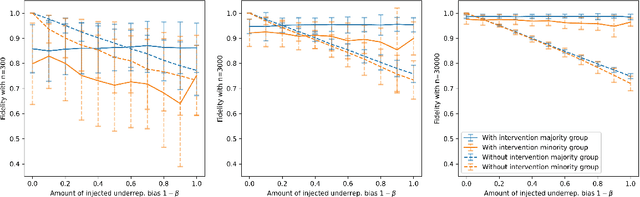
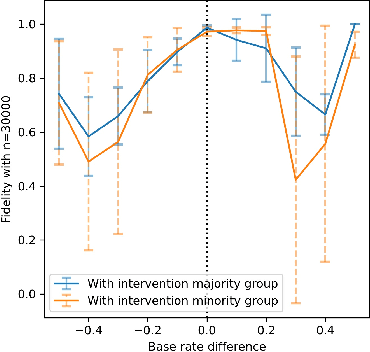
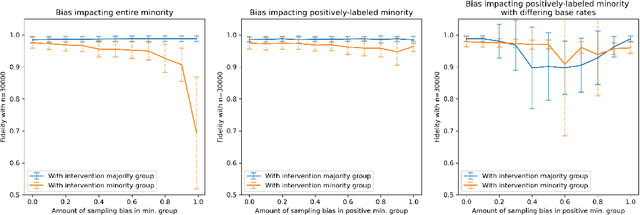
Motivated by the growing importance of reducing unfairness in ML predictions, Fair-ML researchers have presented an extensive suite of algorithmic "fairness-enhancing" remedies. Most existing algorithms, however, are agnostic to the sources of the observed unfairness. As a result, the literature currently lacks guiding frameworks to specify conditions under which each algorithmic intervention can potentially alleviate the underpinning cause of unfairness. To close this gap, we scrutinize the underlying biases (e.g., in the training data or design choices) that cause observational unfairness. We present a bias-injection sandbox tool to investigate fairness consequences of various biases and assess the effectiveness of algorithmic remedies in the presence of specific types of bias. We call this process the bias(stress)-testing of algorithmic interventions. Unlike existing toolkits, ours provides a controlled environment to counterfactually inject biases in the ML pipeline. This stylized setup offers the distinct capability of testing fairness interventions beyond observational data and against an unbiased benchmark. In particular, we can test whether a given remedy can alleviate the injected bias by comparing the predictions resulting after the intervention in the biased setting with true labels in the unbiased regime -- that is, before any bias injection. We illustrate the utility of our toolkit via a proof-of-concept case study on synthetic data. Our empirical analysis showcases the type of insights that can be obtained through our simulations.
Improving Human-AI Partnerships in Child Welfare: Understanding Worker Practices, Challenges, and Desires for Algorithmic Decision Support
Apr 05, 2022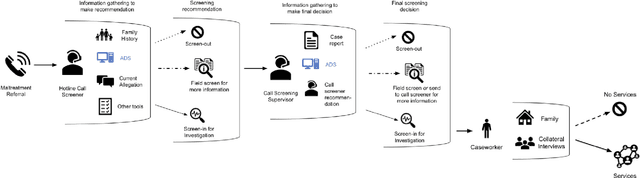
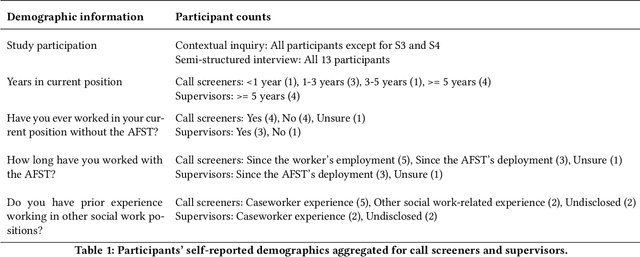
AI-based decision support tools (ADS) are increasingly used to augment human decision-making in high-stakes, social contexts. As public sector agencies begin to adopt ADS, it is critical that we understand workers' experiences with these systems in practice. In this paper, we present findings from a series of interviews and contextual inquiries at a child welfare agency, to understand how they currently make AI-assisted child maltreatment screening decisions. Overall, we observe how workers' reliance upon the ADS is guided by (1) their knowledge of rich, contextual information beyond what the AI model captures, (2) their beliefs about the ADS's capabilities and limitations relative to their own, (3) organizational pressures and incentives around the use of the ADS, and (4) awareness of misalignments between algorithmic predictions and their own decision-making objectives. Drawing upon these findings, we discuss design implications towards supporting more effective human-AI decision-making.
Incentivizing Compliance with Algorithmic Instruments
Jul 28, 2021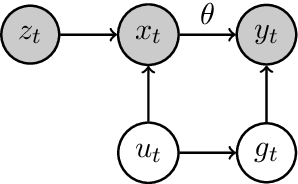

Randomized experiments can be susceptible to selection bias due to potential non-compliance by the participants. While much of the existing work has studied compliance as a static behavior, we propose a game-theoretic model to study compliance as dynamic behavior that may change over time. In rounds, a social planner interacts with a sequence of heterogeneous agents who arrive with their unobserved private type that determines both their prior preferences across the actions (e.g., control and treatment) and their baseline rewards without taking any treatment. The planner provides each agent with a randomized recommendation that may alter their beliefs and their action selection. We develop a novel recommendation mechanism that views the planner's recommendation as a form of instrumental variable (IV) that only affects an agents' action selection, but not the observed rewards. We construct such IVs by carefully mapping the history -- the interactions between the planner and the previous agents -- to a random recommendation. Even though the initial agents may be completely non-compliant, our mechanism can incentivize compliance over time, thereby enabling the estimation of the treatment effect of each treatment, and minimizing the cumulative regret of the planner whose goal is to identify the optimal treatment.
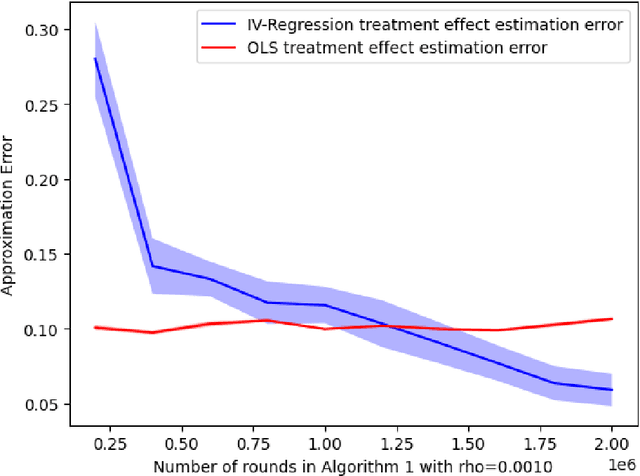
Strategic Instrumental Variable Regression: Recovering Causal Relationships From Strategic Responses
Jul 12, 2021


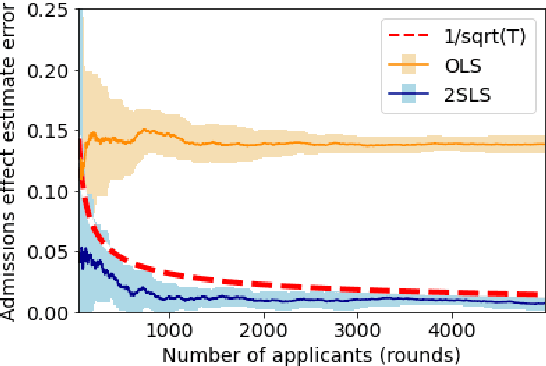
Machine Learning algorithms often prompt individuals to strategically modify their observable attributes to receive more favorable predictions. As a result, the distribution the predictive model is trained on may differ from the one it operates on in deployment. While such distribution shifts, in general, hinder accurate predictions, our work identifies a unique opportunity associated with shifts due to strategic responses: We show that we can use strategic responses effectively to recover causal relationships between the observable features and outcomes we wish to predict. More specifically, we study a game-theoretic model in which a principal deploys a sequence of models to predict an outcome of interest (e.g., college GPA) for a sequence of strategic agents (e.g., college applicants). In response, strategic agents invest efforts and modify their features for better predictions. In such settings, unobserved confounding variables can influence both an agent's observable features (e.g., high school records) and outcomes. Therefore, standard regression methods generally produce biased estimators. In order to address this issue, our work establishes a novel connection between strategic responses to machine learning models and instrumental variable (IV) regression, by observing that the sequence of deployed models can be viewed as an instrument that affects agents' observable features but does not directly influence their outcomes. Therefore, two-stage least squares (2SLS) regression can recover the causal relationships between observable features and outcomes. Beyond causal recovery, we can build on our 2SLS method to address two additional relevant optimization objectives: agent outcome maximization and predictive risk minimization. Finally, our numerical simulations on semi-synthetic data show that our methods significantly outperform OLS regression in causal relationship estimation.
Eliciting and Enforcing Subjective Individual Fairness
May 25, 2019
We revisit the notion of individual fairness first proposed by Dwork et al. [2012], which asks that "similar individuals should be treated similarly". A primary difficulty with this definition is that it assumes a completely specified fairness metric for the task at hand. In contrast, we consider a framework for fairness elicitation, in which fairness is indirectly specified only via a sample of pairs of individuals who should be treated (approximately) equally on the task. We make no assumption that these pairs are consistent with any metric. We provide a provably convergent oracle-efficient algorithm for minimizing error subject to the fairness constraints, and prove generalization theorems for both accuracy and fairness. Since the constrained pairs could be elicited either from a panel of judges, or from particular individuals, our framework provides a means for algorithmically enforcing subjective notions of fairness. We report on preliminary findings of a behavioral study of subjective fairness using human-subject fairness constraints elicited on the COMPAS criminal recidivism dataset.