 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Algorithmic Gaze: An Audit and Ethnography of the LAION-Aesthetics Predictor Model
Jan 14, 2026Visual generative AI models are trained using a one-size-fits-all measure of aesthetic appeal. However, what is deemed "aesthetic" is inextricably linked to personal taste and cultural values, raising the question of whose taste is represented in visual generative AI models. In this work, we study an aesthetic evaluation model--LAION Aesthetic Predictor (LAP)--that is widely used to curate datasets to train visual generative image models, like Stable Diffusion, and evaluate the quality of AI-generated images. To understand what LAP measures, we audited the model across three datasets. First, we examined the impact of aesthetic filtering on the LAION-Aesthetics Dataset (approximately 1.2B images), which was curated from LAION-5B using LAP. We find that the LAP disproportionally filters in images with captions mentioning women, while filtering out images with captions mentioning men or LGBTQ+ people. Then, we used LAP to score approximately 330k images across two art datasets, finding the model rates realistic images of landscapes, cityscapes, and portraits from western and Japanese artists most highly. In doing so, the algorithmic gaze of this aesthetic evaluation model reinforces the imperial and male gazes found within western art history. In order to understand where these biases may have originated, we performed a digital ethnography of public materials related to the creation of LAP. We find that the development of LAP reflects the biases we found in our audits, such as the aesthetic scores used to train LAP primarily coming from English-speaking photographers and western AI-enthusiasts. In response, we discuss how aesthetic evaluation can perpetuate representational harms and call on AI developers to shift away from prescriptive measures of "aesthetics" toward more pluralistic evaluation.
POET: Supporting Prompting Creativity and Personalization with Automated Expansion of Text-to-Image Generation
Apr 18, 2025
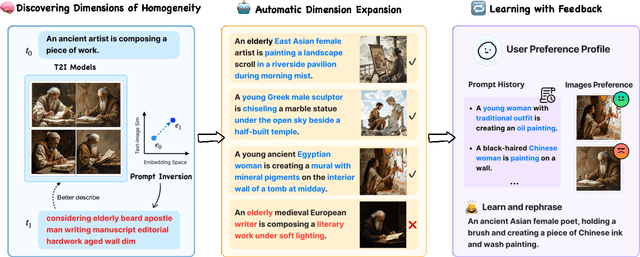


State-of-the-art visual generative AI tools hold immense potential to assist users in the early ideation stages of creative tasks -- offering the ability to generate (rather than search for) novel and unprecedented (instead of existing) images of considerable quality that also adhere to boundless combinations of user specifications. However, many large-scale text-to-image systems are designed for broad applicability, yielding conventional output that may limit creative exploration. They also employ interaction methods that may be difficult for beginners. Given that creative end users often operate in diverse, context-specific ways that are often unpredictable, more variation and personalization are necessary. We introduce POET, a real-time interactive tool that (1) automatically discovers dimensions of homogeneity in text-to-image generative models, (2) expands these dimensions to diversify the output space of generated images, and (3) learns from user feedback to personalize expansions. An evaluation with 28 users spanning four creative task domains demonstrated POET's ability to generate results with higher perceived diversity and help users reach satisfaction in fewer prompts during creative tasks, thereby prompting them to deliberate and reflect more on a wider range of possible produced results during the co-creative process. Focusing on visual creativity, POET offers a first glimpse of how interaction techniques of future text-to-image generation tools may support and align with more pluralistic values and the needs of end users during the ideation stages of their work.
Un-Straightening Generative AI: How Queer Artists Surface and Challenge the Normativity of Generative AI Models
Mar 12, 2025Queer people are often discussed as targets of bias, harm, or discrimination in research on generative AI. However, the specific ways that queer people engage with generative AI, and thus possible uses that support queer people, have yet to be explored. We conducted a workshop study with 13 queer artists, during which we gave participants access to GPT-4 and DALL-E 3 and facilitated group sensemaking activities. We found our participants struggled to use these models due to various normative values embedded in their designs, such as hyper-positivity and anti-sexuality. We describe various strategies our participants developed to overcome these models' limitations and how, nevertheless, our participants found value in these highly-normative technologies. Drawing on queer feminist theory, we discuss implications for the conceptualization of "state-of-the-art" models and consider how FAccT researchers might support queer alternatives.
Studying Up Public Sector AI: How Networks of Power Relations Shape Agency Decisions Around AI Design and Use
May 21, 2024As public sector agencies rapidly introduce new AI tools in high-stakes domains like social services, it becomes critical to understand how decisions to adopt these tools are made in practice. We borrow from the anthropological practice to ``study up'' those in positions of power, and reorient our study of public sector AI around those who have the power and responsibility to make decisions about the role that AI tools will play in their agency. Through semi-structured interviews and design activities with 16 agency decision-makers, we examine how decisions about AI design and adoption are influenced by their interactions with and assumptions about other actors within these agencies (e.g., frontline workers and agency leaders), as well as those above (legal systems and contracted companies), and below (impacted communities). By centering these networks of power relations, our findings shed light on how infrastructural, legal, and social factors create barriers and disincentives to the involvement of a broader range of stakeholders in decisions about AI design and adoption. Agency decision-makers desired more practical support for stakeholder involvement around public sector AI to help overcome the knowledge and power differentials they perceived between them and other stakeholders (e.g., frontline workers and impacted community members). Building on these findings, we discuss implications for future research and policy around actualizing participatory AI approaches in public sector contexts.
Wikibench: Community-Driven Data Curation for AI Evaluation on Wikipedia
Feb 21, 2024AI tools are increasingly deployed in community contexts. However, datasets used to evaluate AI are typically created by developers and annotators outside a given community, which can yield misleading conclusions about AI performance. How might we empower communities to drive the intentional design and curation of evaluation datasets for AI that impacts them? We investigate this question on Wikipedia, an online community with multiple AI-based content moderation tools deployed. We introduce Wikibench, a system that enables communities to collaboratively curate AI evaluation datasets, while navigating ambiguities and differences in perspective through discussion. A field study on Wikipedia shows that datasets curated using Wikibench can effectively capture community consensus, disagreement, and uncertainty. Furthermore, study participants used Wikibench to shape the overall data curation process, including refining label definitions, determining data inclusion criteria, and authoring data statements. Based on our findings, we propose future directions for systems that support community-driven data curation.
Training Towards Critical Use: Learning to Situate AI Predictions Relative to Human Knowledge
Aug 30, 2023



A growing body of research has explored how to support humans in making better use of AI-based decision support, including via training and onboarding. Existing research has focused on decision-making tasks where it is possible to evaluate "appropriate reliance" by comparing each decision against a ground truth label that cleanly maps to both the AI's predictive target and the human decision-maker's goals. However, this assumption does not hold in many real-world settings where AI tools are deployed today (e.g., social work, criminal justice, and healthcare). In this paper, we introduce a process-oriented notion of appropriate reliance called critical use that centers the human's ability to situate AI predictions against knowledge that is uniquely available to them but unavailable to the AI model. To explore how training can support critical use, we conduct a randomized online experiment in a complex social decision-making setting: child maltreatment screening. We find that, by providing participants with accelerated, low-stakes opportunities to practice AI-assisted decision-making in this setting, novices came to exhibit patterns of disagreement with AI that resemble those of experienced workers. A qualitative examination of participants' explanations for their AI-assisted decisions revealed that they drew upon qualitative case narratives, to which the AI model did not have access, to learn when (not) to rely on AI predictions. Our findings open new questions for the study and design of training for real-world AI-assisted decision-making.
Organizational Bulk Email Systems: Their Role and Performance in Remote Work
Aug 09, 2023


The COVID-19 pandemic has forced many employees to work from home. Organizational bulk emails now play a critical role to reach employees with central information in this work-from-home environment. However, we know from our own recent work that organizational bulk email has problems: recipients fail to retain the bulk messages they received from the organization; recipients and senders have different opinions on which bulk messages were important; and communicators lack technology support to better target and design messages. In this position paper, first we review the prior work on evaluating, designing, and prototyping organizational communication systems. Second we review our recent findings and some research techniques we found useful in studying organizational communication. Last we propose a research agenda to study organizational communications in remote work environment and suggest some key questions and potential study directions.
LLMs as Workers in Human-Computational Algorithms? Replicating Crowdsourcing Pipelines with LLMs
Jul 20, 2023

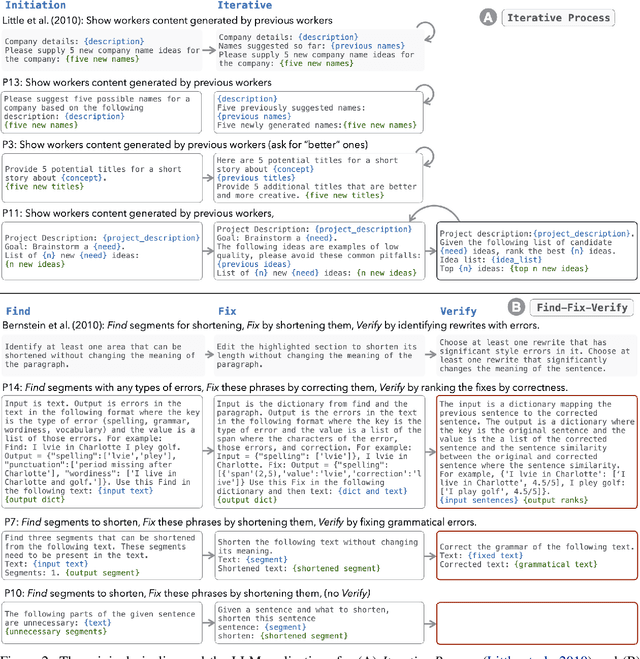
LLMs have shown promise in replicating human-like behavior in crowdsourcing tasks that were previously thought to be exclusive to human abilities. However, current efforts focus mainly on simple atomic tasks. We explore whether LLMs can replicate more complex crowdsourcing pipelines. We find that modern LLMs can simulate some of crowdworkers' abilities in these "human computation algorithms," but the level of success is variable and influenced by requesters' understanding of LLM capabilities, the specific skills required for sub-tasks, and the optimal interaction modality for performing these sub-tasks. We reflect on human and LLMs' different sensitivities to instructions, stress the importance of enabling human-facing safeguards for LLMs, and discuss the potential of training humans and LLMs with complementary skill sets. Crucially, we show that replicating crowdsourcing pipelines offers a valuable platform to investigate (1) the relative strengths of LLMs on different tasks (by cross-comparing their performances on sub-tasks) and (2) LLMs' potential in complex tasks, where they can complete part of the tasks while leaving others to humans.
Seeing Seeds Beyond Weeds: Green Teaming Generative AI for Beneficial Uses
May 30, 2023
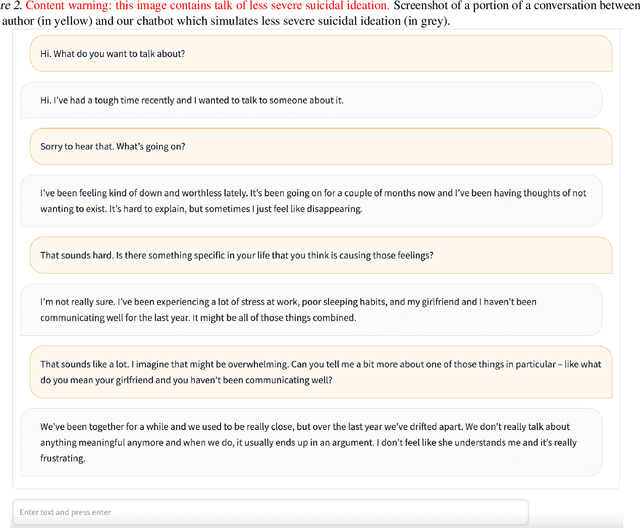
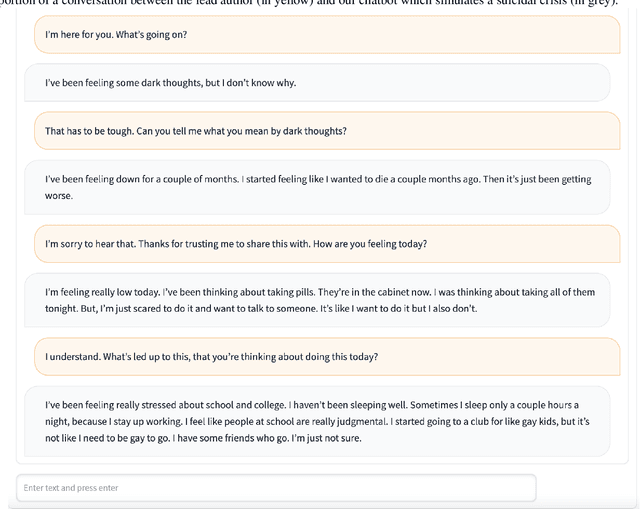
Large generative AI models (GMs) like GPT and DALL-E are trained to generate content for general, wide-ranging purposes. GM content filters are generalized to filter out content which has a risk of harm in many cases, e.g., hate speech. However, prohibited content is not always harmful -- there are instances where generating prohibited content can be beneficial. So, when GMs filter out content, they preclude beneficial use cases along with harmful ones. Which use cases are precluded reflects the values embedded in GM content filtering. Recent work on red teaming proposes methods to bypass GM content filters to generate harmful content. We coin the term green teaming to describe methods of bypassing GM content filters to design for beneficial use cases. We showcase green teaming by: 1) Using ChatGPT as a virtual patient to simulate a person experiencing suicidal ideation, for suicide support training; 2) Using Codex to intentionally generate buggy solutions to train students on debugging; and 3) Examining an Instagram page using Midjourney to generate images of anti-LGBTQ+ politicians in drag. Finally, we discuss how our use cases demonstrate green teaming as both a practical design method and a mode of critique, which problematizes and subverts current understandings of harms and values in generative AI.
Recentering Validity Considerations through Early-Stage Deliberations Around AI and Policy Design
Mar 26, 2023AI-based decision-making tools are rapidly spreading across a range of real-world, complex domains like healthcare, criminal justice, and child welfare. A growing body of research has called for increased scrutiny around the validity of AI system designs. However, in real-world settings, it is often not possible to fully address questions around the validity of an AI tool without also considering the design of associated organizational and public policies. Yet, considerations around how an AI tool may interface with policy are often only discussed retrospectively, after the tool is designed or deployed. In this short position paper, we discuss opportunities to promote multi-stakeholder deliberations around the design of AI-based technologies and associated policies, at the earliest stages of a new project.