 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalsifying Predictive Algorithm
Jan 23, 2026Empirical investigations into unintended model behavior often show that the algorithm is predicting another outcome than what was intended. These exposes highlight the need to identify when algorithms predict unintended quantities - ideally before deploying them into consequential settings. We propose a falsification framework that provides a principled statistical test for discriminant validity: the requirement that an algorithm predict intended outcomes better than impermissible ones. Drawing on falsification practices from causal inference, econometrics, and psychometrics, our framework compares calibrated prediction losses across outcomes to assess whether the algorithm exhibits discriminant validity with respect to a specified impermissible proxy. In settings where the target outcome is difficult to observe, multiple permissible proxy outcomes may be available; our framework accommodates both this setting and the case with a single permissible proxy. Throughout we use nonparametric hypothesis testing methods that make minimal assumptions on the data-generating process. We illustrate the method in an admissions setting, where the framework establishes discriminant validity with respect to gender but fails to establish discriminant validity with respect to race. This demonstrates how falsification can serve as an early validity check, prior to fairness or robustness analyses. We also provide analysis in a criminal justice setting, where we highlight the limitations of our framework and emphasize the need for complementary approaches to assess other aspects of construct validity and external validity.
Studying Up Public Sector AI: How Networks of Power Relations Shape Agency Decisions Around AI Design and Use
May 21, 2024As public sector agencies rapidly introduce new AI tools in high-stakes domains like social services, it becomes critical to understand how decisions to adopt these tools are made in practice. We borrow from the anthropological practice to ``study up'' those in positions of power, and reorient our study of public sector AI around those who have the power and responsibility to make decisions about the role that AI tools will play in their agency. Through semi-structured interviews and design activities with 16 agency decision-makers, we examine how decisions about AI design and adoption are influenced by their interactions with and assumptions about other actors within these agencies (e.g., frontline workers and agency leaders), as well as those above (legal systems and contracted companies), and below (impacted communities). By centering these networks of power relations, our findings shed light on how infrastructural, legal, and social factors create barriers and disincentives to the involvement of a broader range of stakeholders in decisions about AI design and adoption. Agency decision-makers desired more practical support for stakeholder involvement around public sector AI to help overcome the knowledge and power differentials they perceived between them and other stakeholders (e.g., frontline workers and impacted community members). Building on these findings, we discuss implications for future research and policy around actualizing participatory AI approaches in public sector contexts.
Predictive Performance Comparison of Decision Policies Under Confounding
Apr 01, 2024



Predictive models are often introduced to decision-making tasks under the rationale that they improve performance over an existing decision-making policy. However, it is challenging to compare predictive performance against an existing decision-making policy that is generally under-specified and dependent on unobservable factors. These sources of uncertainty are often addressed in practice by making strong assumptions about the data-generating mechanism. In this work, we propose a method to compare the predictive performance of decision policies under a variety of modern identification approaches from the causal inference and off-policy evaluation literatures (e.g., instrumental variable, marginal sensitivity model, proximal variable). Key to our method is the insight that there are regions of uncertainty that we can safely ignore in the policy comparison. We develop a practical approach for finite-sample estimation of regret intervals under no assumptions on the parametric form of the status quo policy. We verify our framework theoretically and via synthetic data experiments. We conclude with a real-world application using our framework to support a pre-deployment evaluation of a proposed modification to a healthcare enrollment policy.
Examining risks of racial biases in NLP tools for child protective services
May 30, 2023
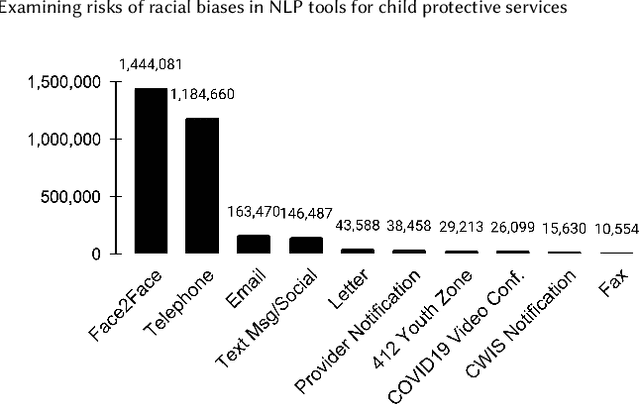


Although much literature has established the presence of demographic bias in natural language processing (NLP) models, most work relies on curated bias metrics that may not be reflective of real-world applications. At the same time, practitioners are increasingly using algorithmic tools in high-stakes settings, with particular recent interest in NLP. In this work, we focus on one such setting: child protective services (CPS). CPS workers often write copious free-form text notes about families they are working with, and CPS agencies are actively seeking to deploy NLP models to leverage these data. Given well-established racial bias in this setting, we investigate possible ways deployed NLP is liable to increase racial disparities. We specifically examine word statistics within notes and algorithmic fairness in risk prediction, coreference resolution, and named entity recognition (NER). We document consistent algorithmic unfairness in NER models, possible algorithmic unfairness in coreference resolution models, and little evidence of exacerbated racial bias in risk prediction. While there is existing pronounced criticism of risk prediction, our results expose previously undocumented risks of racial bias in realistic information extraction systems, highlighting potential concerns in deploying them, even though they may appear more benign. Our work serves as a rare realistic examination of NLP algorithmic fairness in a potential deployed setting and a timely investigation of a specific risk associated with deploying NLP in CPS settings.
Recentering Validity Considerations through Early-Stage Deliberations Around AI and Policy Design
Mar 26, 2023AI-based decision-making tools are rapidly spreading across a range of real-world, complex domains like healthcare, criminal justice, and child welfare. A growing body of research has called for increased scrutiny around the validity of AI system designs. However, in real-world settings, it is often not possible to fully address questions around the validity of an AI tool without also considering the design of associated organizational and public policies. Yet, considerations around how an AI tool may interface with policy are often only discussed retrospectively, after the tool is designed or deployed. In this short position paper, we discuss opportunities to promote multi-stakeholder deliberations around the design of AI-based technologies and associated policies, at the earliest stages of a new project.
Counterfactual Prediction Under Outcome Measurement Error
Feb 22, 2023Across domains such as medicine, employment, and criminal justice, predictive models often target labels that imperfectly reflect the outcomes of interest to experts and policymakers. For example, clinical risk assessments deployed to inform physician decision-making often predict measures of healthcare utilization (e.g., costs, hospitalization) as a proxy for patient medical need. These proxies can be subject to outcome measurement error when they systematically differ from the target outcome they are intended to measure. However, prior modeling efforts to characterize and mitigate outcome measurement error overlook the fact that the decision being informed by a model often serves as a risk-mitigating intervention that impacts the target outcome of interest and its recorded proxy. Thus, in these settings, addressing measurement error requires counterfactual modeling of treatment effects on outcomes. In this work, we study intersectional threats to model reliability introduced by outcome measurement error, treatment effects, and selection bias from historical decision-making policies. We develop an unbiased risk minimization method which, given knowledge of proxy measurement error properties, corrects for the combined effects of these challenges. We also develop a method for estimating treatment-dependent measurement error parameters when these are unknown in advance. We demonstrate the utility of our approach theoretically and via experiments on real-world data from randomized controlled trials conducted in healthcare and employment domains. As importantly, we demonstrate that models correcting for outcome measurement error or treatment effects alone suffer from considerable reliability limitations. Our work underscores the importance of considering intersectional threats to model validity during the design and evaluation of predictive models for decision support.
Ground Truth: A Causal Framework for Proxy Labels in Human-Algorithm Decision-Making
Feb 22, 2023
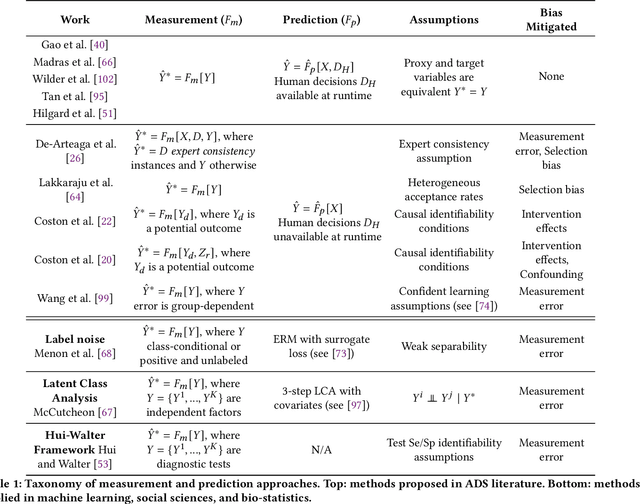
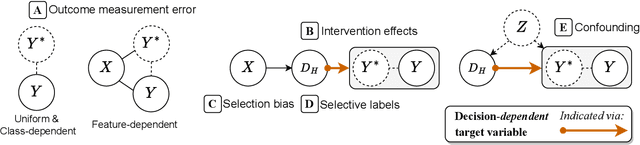
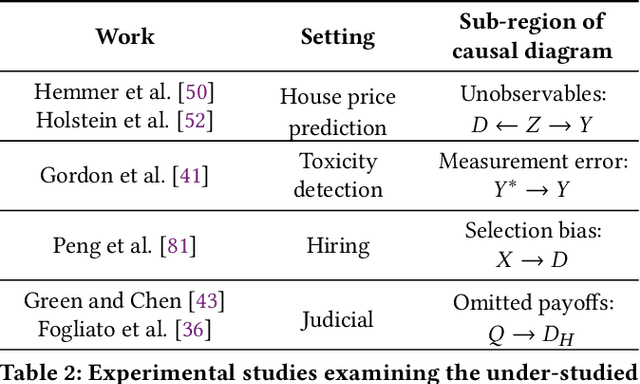
A growing literature on human-AI decision-making investigates strategies for combining human judgment with statistical models to improve decision-making. Research in this area often evaluates proposed improvements to models, interfaces, or workflows by demonstrating improved predictive performance on "ground truth" labels. However, this practice overlooks a key difference between human judgments and model predictions. Whereas humans reason about broader phenomena of interest in a decision -- including latent constructs that are not directly observable, such as disease status, the "toxicity" of online comments, or future "job performance" -- predictive models target proxy labels that are readily available in existing datasets. Predictive models' reliance on simplistic proxies makes them vulnerable to various sources of statistical bias. In this paper, we identify five sources of target variable bias that can impact the validity of proxy labels in human-AI decision-making tasks. We develop a causal framework to disentangle the relationship between each bias and clarify which are of concern in specific human-AI decision-making tasks. We demonstrate how our framework can be used to articulate implicit assumptions made in prior modeling work, and we recommend evaluation strategies for verifying whether these assumptions hold in practice. We then leverage our framework to re-examine the designs of prior human subjects experiments that investigate human-AI decision-making, finding that only a small fraction of studies examine factors related to target variable bias. We conclude by discussing opportunities to better address target variable bias in future research.
Counterfactual Risk Assessments under Unmeasured Confounding
Dec 19, 2022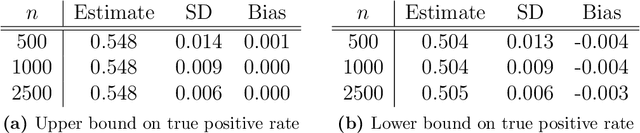
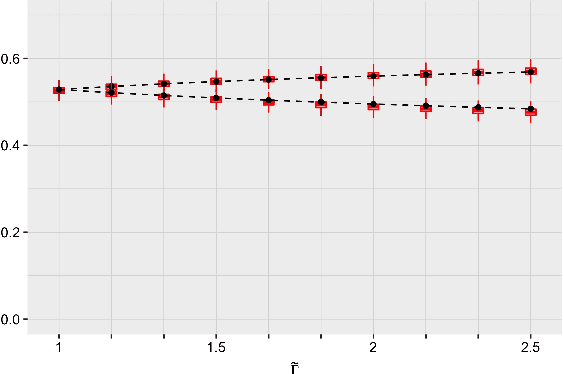
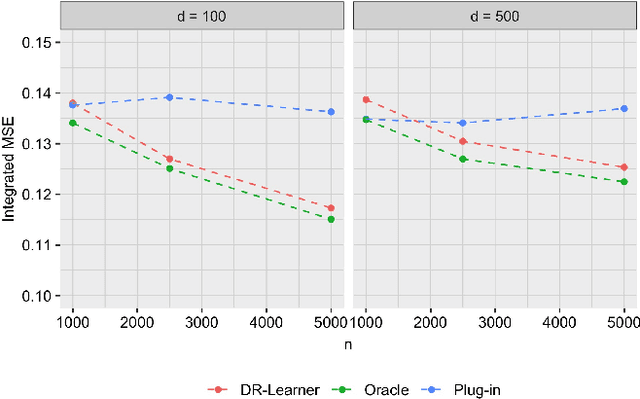
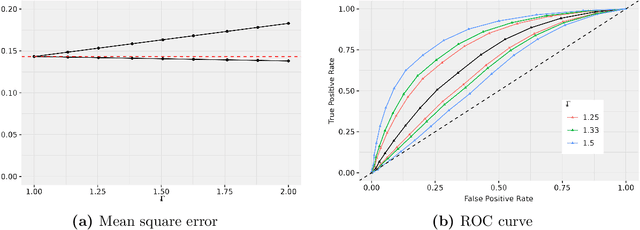
Statistical risk assessments inform consequential decisions such as pretrial release in criminal justice, and loan approvals in consumer finance. Such risk assessments make counterfactual predictions, predicting the likelihood of an outcome under a proposed decision (e.g., what would happen if we approved this loan?). A central challenge, however, is that there may have been unmeasured confounders that jointly affected past decisions and outcomes in the historical data. This paper proposes a tractable mean outcome sensitivity model that bounds the extent to which unmeasured confounders could affect outcomes on average. The mean outcome sensitivity model partially identifies the conditional likelihood of the outcome under the proposed decision, popular predictive performance metrics (e.g., accuracy, calibration, TPR, FPR), and commonly-used predictive disparities. We derive their sharp identified sets, and we then solve three tasks that are essential to deploying statistical risk assessments in high-stakes settings. First, we propose a doubly-robust learning procedure for the bounds on the conditional likelihood of the outcome under the proposed decision. Second, we translate our estimated bounds on the conditional likelihood of the outcome under the proposed decision into a robust, plug-in decision-making policy. Third, we develop doubly-robust estimators of the bounds on the predictive performance of an existing risk assessment.
The role of the geometric mean in case-control studies
Jul 19, 2022Historically used in settings where the outcome is rare or data collection is expensive, outcome-dependent sampling is relevant to many modern settings where data is readily available for a biased sample of the target population, such as public administrative data. Under outcome-dependent sampling, common effect measures such as the average risk difference and the average risk ratio are not identified, but the conditional odds ratio is. Aggregation of the conditional odds ratio is challenging since summary measures are generally not identified. Furthermore, the marginal odds ratio can be larger (or smaller) than all conditional odds ratios. This so-called non-collapsibility of the odds ratio is avoidable if we use an alternative aggregation to the standard arithmetic mean. We provide a new definition of collapsibility that makes this choice of aggregation method explicit, and we demonstrate that the odds ratio is collapsible under geometric aggregation. We describe how to partially identify, estimate, and do inference on the geometric odds ratio under outcome-dependent sampling. Our proposed estimator is based on the efficient influence function and therefore has doubly robust-style properties.
A Validity Perspective on Evaluating the Justified Use of Data-driven Decision-making Algorithms
Jun 30, 2022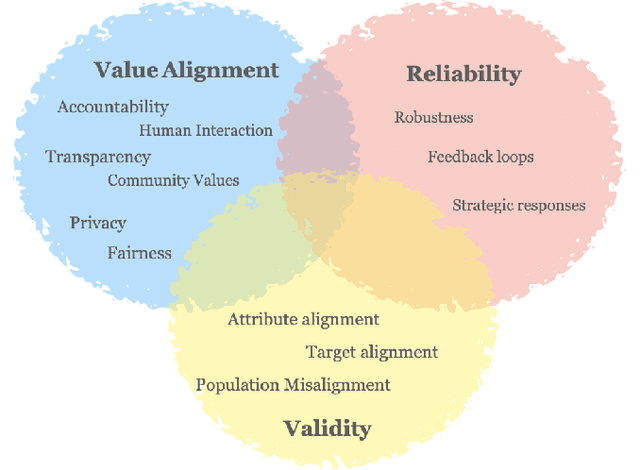
This work seeks to center validity considerations in deliberations around whether and how to build data-driven algorithms in high-stakes domains. Toward this end, we translate key concepts from validity theory to predictive algorithms. We describe common challenges in problem formulation and data issues that jeopardize the validity of predictive algorithms. We distill these issues into a series of high-level questions intended to promote and document reflections on the legitimacy of the predictive task and the suitability of the data. This contribution lays the foundation for co-designing a validity protocol, in collaboration with real-world stakeholders, including decision-makers, modelers, and members of potentially impacted communities, to critically evaluate the justifiability of specific designs and uses of data-driven algorithmic systems.