 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthTextEval: Synthetic Text Data Generation and Evaluation for High-Stakes Domains
Jul 09, 2025We present SynthTextEval, a toolkit for conducting comprehensive evaluations of synthetic text. The fluency of large language model (LLM) outputs has made synthetic text potentially viable for numerous applications, such as reducing the risks of privacy violations in the development and deployment of AI systems in high-stakes domains. Realizing this potential, however, requires principled consistent evaluations of synthetic data across multiple dimensions: its utility in downstream systems, the fairness of these systems, the risk of privacy leakage, general distributional differences from the source text, and qualitative feedback from domain experts. SynthTextEval allows users to conduct evaluations along all of these dimensions over synthetic data that they upload or generate using the toolkit's generation module. While our toolkit can be run over any data, we highlight its functionality and effectiveness over datasets from two high-stakes domains: healthcare and law. By consolidating and standardizing evaluation metrics, we aim to improve the viability of synthetic text, and in-turn, privacy-preservation in AI development.
Beyond Text: Characterizing Domain Expert Needs in Document Research
Apr 16, 2025Working with documents is a key part of almost any knowledge work, from contextualizing research in a literature review to reviewing legal precedent. Recently, as their capabilities have expanded, primarily text-based NLP systems have often been billed as able to assist or even automate this kind of work. But to what extent are these systems able to model these tasks as experts conceptualize and perform them now? In this study, we interview sixteen domain experts across two domains to understand their processes of document research, and compare it to the current state of NLP systems. We find that our participants processes are idiosyncratic, iterative, and rely extensively on the social context of a document in addition its content; existing approaches in NLP and adjacent fields that explicitly center the document as an object, rather than as merely a container for text, tend to better reflect our participants' priorities, though they are often less accessible outside their research communities. We call on the NLP community to more carefully consider the role of the document in building useful tools that are accessible, personalizable, iterative, and socially aware.
Evaluating Differentially Private Synthetic Data Generation in High-Stakes Domains
Oct 10, 2024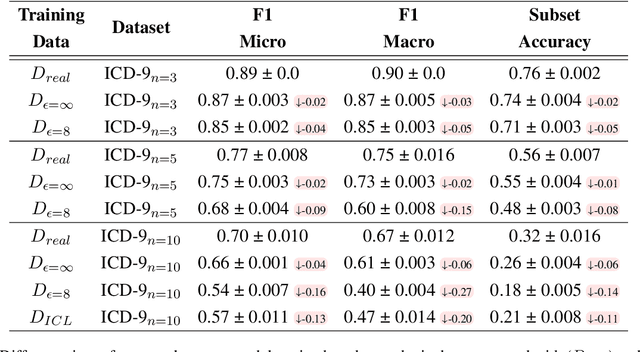


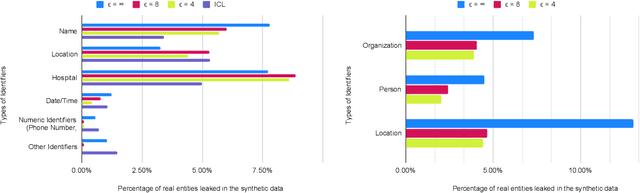
The difficulty of anonymizing text data hinders the development and deployment of NLP in high-stakes domains that involve private data, such as healthcare and social services. Poorly anonymized sensitive data cannot be easily shared with annotators or external researchers, nor can it be used to train public models. In this work, we explore the feasibility of using synthetic data generated from differentially private language models in place of real data to facilitate the development of NLP in these domains without compromising privacy. In contrast to prior work, we generate synthetic data for real high-stakes domains, and we propose and conduct use-inspired evaluations to assess data quality. Our results show that prior simplistic evaluations have failed to highlight utility, privacy, and fairness issues in the synthetic data. Overall, our work underscores the need for further improvements to synthetic data generation for it to be a viable way to enable privacy-preserving data sharing.
Examining risks of racial biases in NLP tools for child protective services
May 30, 2023
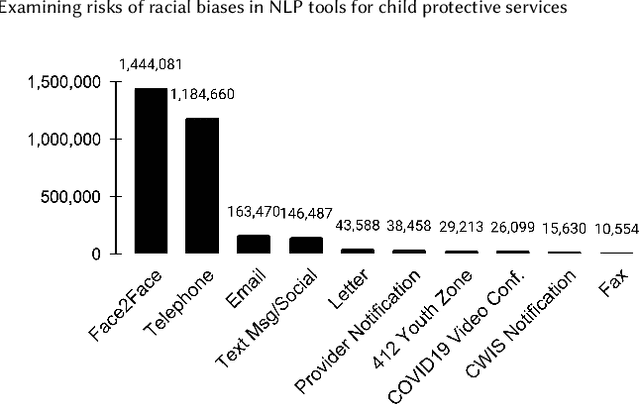


Although much literature has established the presence of demographic bias in natural language processing (NLP) models, most work relies on curated bias metrics that may not be reflective of real-world applications. At the same time, practitioners are increasingly using algorithmic tools in high-stakes settings, with particular recent interest in NLP. In this work, we focus on one such setting: child protective services (CPS). CPS workers often write copious free-form text notes about families they are working with, and CPS agencies are actively seeking to deploy NLP models to leverage these data. Given well-established racial bias in this setting, we investigate possible ways deployed NLP is liable to increase racial disparities. We specifically examine word statistics within notes and algorithmic fairness in risk prediction, coreference resolution, and named entity recognition (NER). We document consistent algorithmic unfairness in NER models, possible algorithmic unfairness in coreference resolution models, and little evidence of exacerbated racial bias in risk prediction. While there is existing pronounced criticism of risk prediction, our results expose previously undocumented risks of racial bias in realistic information extraction systems, highlighting potential concerns in deploying them, even though they may appear more benign. Our work serves as a rare realistic examination of NLP algorithmic fairness in a potential deployed setting and a timely investigation of a specific risk associated with deploying NLP in CPS settings.
Mention Annotations Alone Enable Efficient Domain Adaptation for Coreference Resolution
Oct 14, 2022

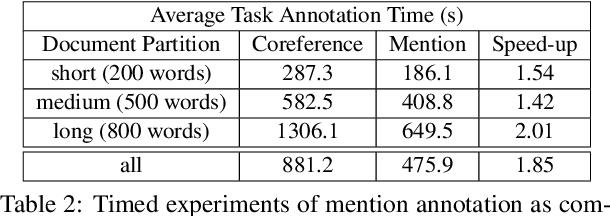

Although, recent advances in neural network models for coreference resolution have led to substantial improvements on benchmark datasets, it remains a challenge to successfully transfer those models to new target domains containing many out-of-vocabulary spans and requiring differing annotation schemes. Typical approaches for domain adaptation involve continued training on coreference annotations in the target domain, but obtaining those annotations is costly and time-consuming. In this work, we show that adapting mention detection is the key component to successful domain adaptation of coreference models, rather than antecedent linking. Through timed annotation experiments, we also show annotating mentions alone is nearly twice as fast as annotating full coreference chains. Based on these insights, we propose a method for effectively adapting coreference models that requires only mention annotations in the target domain. We use an auxiliary mention detection objective trained with mention examples in the target domain resulting in higher mention precision. We demonstrate that our approach facilitates sample- and time-efficient transfer to new annotation schemes and lexicons in extensive evaluation across three English coreference datasets: CoNLL-2012 (news/conversation), i2b2/VA (medical case notes), and a dataset of child welfare case notes. We show that annotating mentions results in 7-14% improvement in average F1 over annotating coreference over an equivalent amount of time.
Improving Span Representation for Domain-adapted Coreference Resolution
Sep 20, 2021



Recent work has shown fine-tuning neural coreference models can produce strong performance when adapting to different domains. However, at the same time, this can require a large amount of annotated target examples. In this work, we focus on supervised domain adaptation for clinical notes, proposing the use of concept knowledge to more efficiently adapt coreference models to a new domain. We develop methods to improve the span representations via (1) a retrofitting loss to incentivize span representations to satisfy a knowledge-based distance function and (2) a scaffolding loss to guide the recovery of knowledge from the span representation. By integrating these losses, our model is able to improve our baseline precision and F-1 score. In particular, we show that incorporating knowledge with end-to-end coreference models results in better performance on the most challenging, domain-specific spans.
Multi-dimensional Features for Prediction with Tweets
Oct 15, 2019
With the rise of opioid abuse in the US, there has been a growth of overlapping hotspots for overdose-related and HIV-related deaths in Springfield, Boston, Fall River, New Bedford, and parts of Cape Cod. With a large part of population, including rural communities, active on social media, it is crucial that we leverage the predictive power of social media as a preventive measure. We explore the predictive power of micro-blogging social media website Twitter with respect to HIV new diagnosis rates per county. While trending work in Twitter NLP has focused on primarily text-based features, we show that multi-dimensional feature construction can significantly improve the predictive power of topic features alone with respect STI's (sexually transmitted infections). By multi-dimensional features, we mean leveraging not only the topical features (text) of a corpus, but also location-based information (counties) about the tweets in feature-construction. We develop novel text-location-based smoothing features to predict new diagnoses of HIV.