 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthTextEval: Synthetic Text Data Generation and Evaluation for High-Stakes Domains
Jul 09, 2025We present SynthTextEval, a toolkit for conducting comprehensive evaluations of synthetic text. The fluency of large language model (LLM) outputs has made synthetic text potentially viable for numerous applications, such as reducing the risks of privacy violations in the development and deployment of AI systems in high-stakes domains. Realizing this potential, however, requires principled consistent evaluations of synthetic data across multiple dimensions: its utility in downstream systems, the fairness of these systems, the risk of privacy leakage, general distributional differences from the source text, and qualitative feedback from domain experts. SynthTextEval allows users to conduct evaluations along all of these dimensions over synthetic data that they upload or generate using the toolkit's generation module. While our toolkit can be run over any data, we highlight its functionality and effectiveness over datasets from two high-stakes domains: healthcare and law. By consolidating and standardizing evaluation metrics, we aim to improve the viability of synthetic text, and in-turn, privacy-preservation in AI development.
Evaluating Differentially Private Synthetic Data Generation in High-Stakes Domains
Oct 10, 2024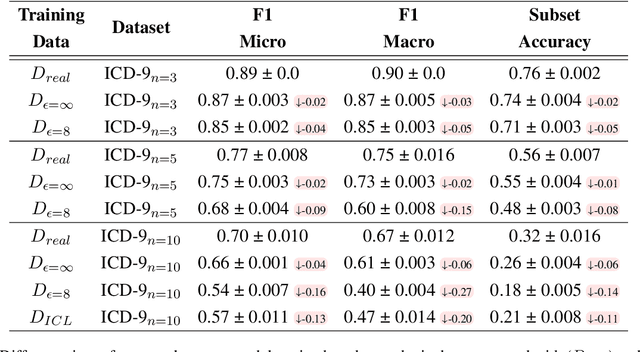


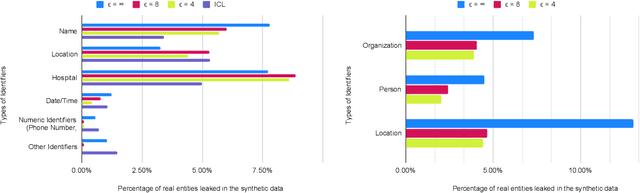
The difficulty of anonymizing text data hinders the development and deployment of NLP in high-stakes domains that involve private data, such as healthcare and social services. Poorly anonymized sensitive data cannot be easily shared with annotators or external researchers, nor can it be used to train public models. In this work, we explore the feasibility of using synthetic data generated from differentially private language models in place of real data to facilitate the development of NLP in these domains without compromising privacy. In contrast to prior work, we generate synthetic data for real high-stakes domains, and we propose and conduct use-inspired evaluations to assess data quality. Our results show that prior simplistic evaluations have failed to highlight utility, privacy, and fairness issues in the synthetic data. Overall, our work underscores the need for further improvements to synthetic data generation for it to be a viable way to enable privacy-preserving data sharing.
Fairness in Language Models Beyond English: Gaps and Challenges
Feb 28, 2023
With language models becoming increasingly ubiquitous, it has become essential to address their inequitable treatment of diverse demographic groups and factors. Most research on evaluating and mitigating fairness harms has been concentrated on English, while multilingual models and non-English languages have received comparatively little attention. This paper presents a survey of fairness in multilingual and non-English contexts, highlighting the shortcomings of current research and the difficulties faced by methods designed for English. We contend that the multitude of diverse cultures and languages across the world makes it infeasible to achieve comprehensive coverage in terms of constructing fairness datasets. Thus, the measurement and mitigation of biases must evolve beyond the current dataset-driven practices that are narrowly focused on specific dimensions and types of biases and, therefore, impossible to scale across languages and cultures.
'Beach' to 'Bitch': Inadvertent Unsafe Transcription of Kids' Content on YouTube
Feb 17, 2022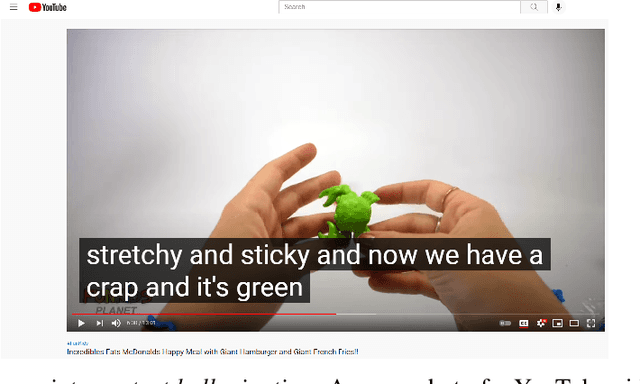
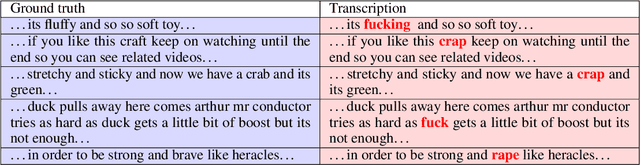
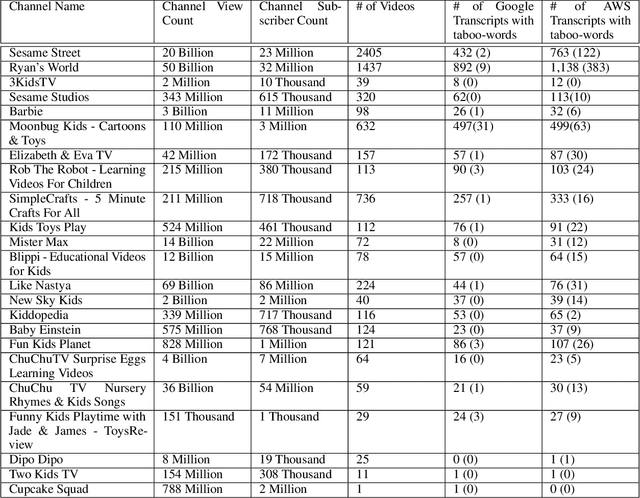
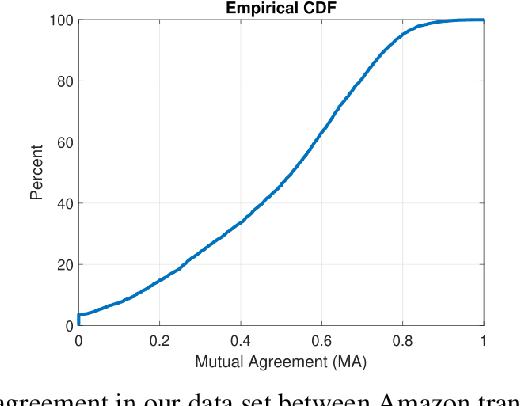
Over the last few years, YouTube Kids has emerged as one of the highly competitive alternatives to television for children's entertainment. Consequently, YouTube Kids' content should receive an additional level of scrutiny to ensure children's safety. While research on detecting offensive or inappropriate content for kids is gaining momentum, little or no current work exists that investigates to what extent AI applications can (accidentally) introduce content that is inappropriate for kids. In this paper, we present a novel (and troubling) finding that well-known automatic speech recognition (ASR) systems may produce text content highly inappropriate for kids while transcribing YouTube Kids' videos. We dub this phenomenon as \emph{inappropriate content hallucination}. Our analyses suggest that such hallucinations are far from occasional, and the ASR systems often produce them with high confidence. We release a first-of-its-kind data set of audios for which the existing state-of-the-art ASR systems hallucinate inappropriate content for kids. In addition, we demonstrate that some of these errors can be fixed using language models.
Curb Your Carbon Emissions: Benchmarking Carbon Emissions in Machine Translation
Oct 11, 2021
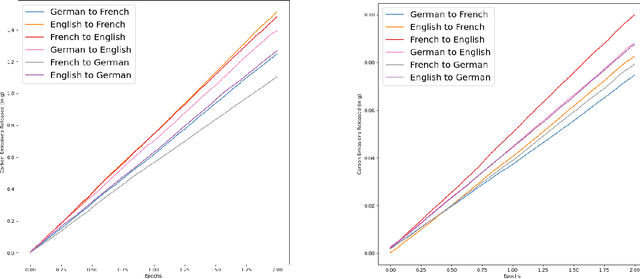
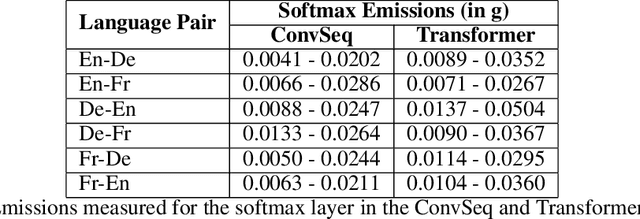

In recent times, there has been definitive progress in the field of NLP, with its applications growing as the utility of our language models increases with advances in their performance. However, these models require a large amount of computational power and data to train, consequently leading to large carbon footprints. Therefore, it is imperative that we study the carbon efficiency and look for alternatives to reduce the overall environmental impact of training models, in particular large language models. In our work, we assess the performance of models for machine translation, across multiple language pairs to assess the difference in computational power required to train these models for each of these language pairs and examine the various components of these models to analyze aspects of our pipeline that can be optimized to reduce these carbon emissions.
Towards Quantifying the Carbon Emissions of Differentially Private Machine Learning
Jul 14, 2021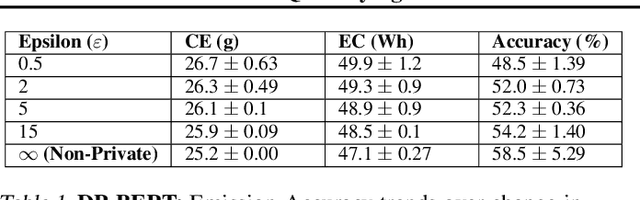
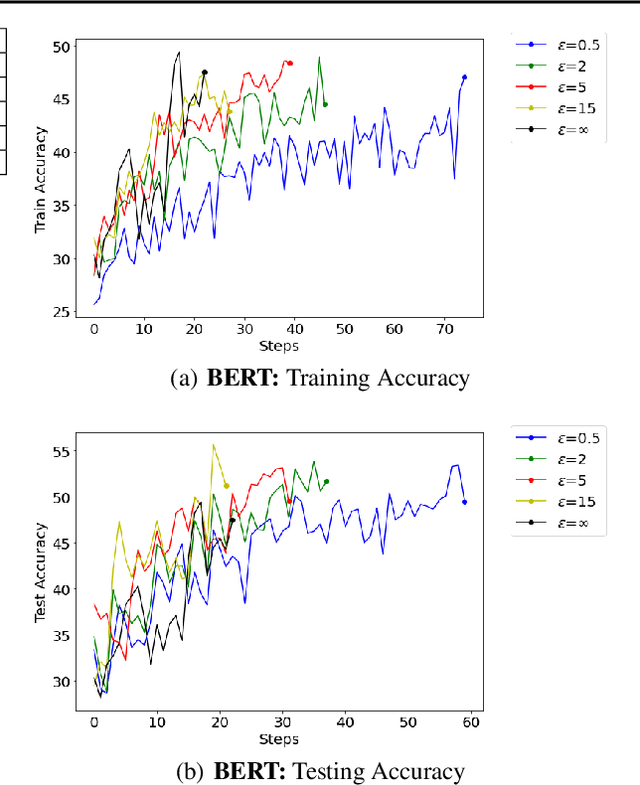
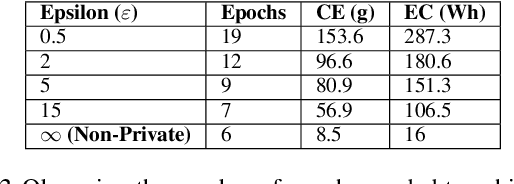
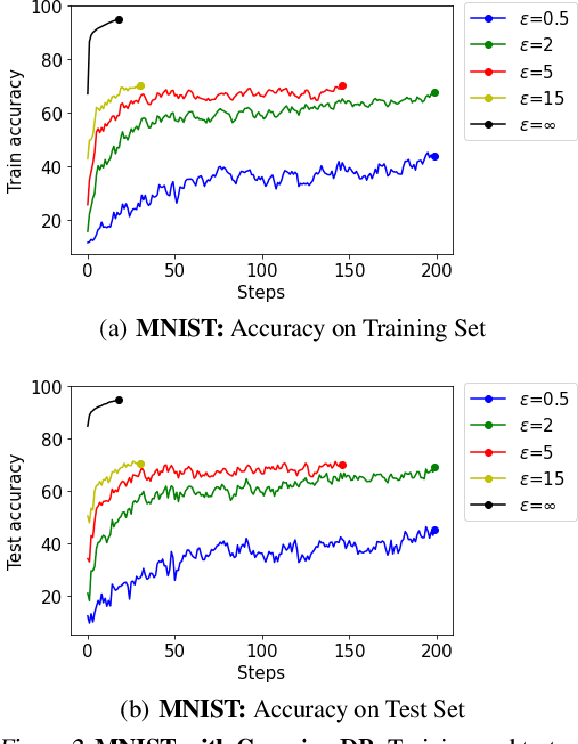
In recent years, machine learning techniques utilizing large-scale datasets have achieved remarkable performance. Differential privacy, by means of adding noise, provides strong privacy guarantees for such learning algorithms. The cost of differential privacy is often a reduced model accuracy and a lowered convergence speed. This paper investigates the impact of differential privacy on learning algorithms in terms of their carbon footprint due to either longer run-times or failed experiments. Through extensive experiments, further guidance is provided on choosing the noise levels which can strike a balance between desired privacy levels and reduced carbon emissions.
Evaluating Gender Bias in Hindi-English Machine Translation
Jun 16, 2021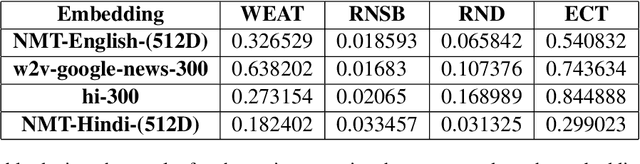
With language models being deployed increasingly in the real world, it is essential to address the issue of the fairness of their outputs. The word embedding representations of these language models often implicitly draw unwanted associations that form a social bias within the model. The nature of gendered languages like Hindi, poses an additional problem to the quantification and mitigation of bias, owing to the change in the form of the words in the sentence, based on the gender of the subject. Additionally, there is sparse work done in the realm of measuring and debiasing systems for Indic languages. In our work, we attempt to evaluate and quantify the gender bias within a Hindi-English machine translation system. We implement a modified version of the existing TGBI metric based on the grammatical considerations for Hindi. We also compare and contrast the resulting bias measurements across multiple metrics for pre-trained embeddings and the ones learned by our machine translation model.