 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Graph Neural Networks for Indian Legal Judgment Prediction
Oct 19, 2023



The burdensome impact of a skewed judges-to-cases ratio on the judicial system manifests in an overwhelming backlog of pending cases alongside an ongoing influx of new ones. To tackle this issue and expedite the judicial process, the proposition of an automated system capable of suggesting case outcomes based on factual evidence and precedent from past cases gains significance. This research paper centres on developing a graph neural network-based model to address the Legal Judgment Prediction (LJP) problem, recognizing the intrinsic graph structure of judicial cases and making it a binary node classification problem. We explored various embeddings as model features, while nodes such as time nodes and judicial acts were added and pruned to evaluate the model's performance. The study is done while considering the ethical dimension of fairness in these predictions, considering gender and name biases. A link prediction task is also conducted to assess the model's proficiency in anticipating connections between two specified nodes. By harnessing the capabilities of graph neural networks and incorporating fairness analyses, this research aims to contribute insights towards streamlining the adjudication process, enhancing judicial efficiency, and fostering a more equitable legal landscape, ultimately alleviating the strain imposed by mounting case backlogs. Our best-performing model with XLNet pre-trained embeddings as its features gives the macro F1 score of 75% for the LJP task. For link prediction, the same set of features is the best performing giving ROC of more than 80%
Curb Your Carbon Emissions: Benchmarking Carbon Emissions in Machine Translation
Oct 11, 2021
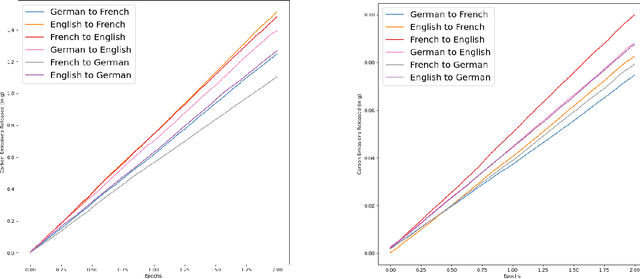
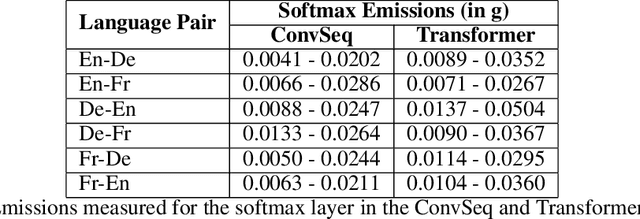

In recent times, there has been definitive progress in the field of NLP, with its applications growing as the utility of our language models increases with advances in their performance. However, these models require a large amount of computational power and data to train, consequently leading to large carbon footprints. Therefore, it is imperative that we study the carbon efficiency and look for alternatives to reduce the overall environmental impact of training models, in particular large language models. In our work, we assess the performance of models for machine translation, across multiple language pairs to assess the difference in computational power required to train these models for each of these language pairs and examine the various components of these models to analyze aspects of our pipeline that can be optimized to reduce these carbon emissions.